[解決済み] ValueError : "Can only tuple-index with a MultiIndex " を取得する。
2022-02-15 06:06:15
質問
整数列の次の整数を予測する簡単なRNNを実装しようとしています。そこで、以下のようなデータセットを持っています。
Id Sequence
1 1,0,0,2,24,552,21280,103760,70299264,5792853248,587159944704
2 1,1,5,11,35,93,269,747,2115,5933,16717,47003,132291,372157,1047181,2946251,8289731,23323853,65624397,184640891,519507267,1461688413,4112616845,11571284395,32557042499,91602704493,257733967693
4 0,1,101,2,15,102,73,3,40,16,47,103,51,74,116,4,57,41,125,17,12,48,9,104,30,52,141,75,107,117,69,5,148,58,88,42,33,126,152,18,160,13,38,49,55,10,28,105,146,31,158
5 1,4,14,23,42,33,35,34,63,66,87,116,84,101,126,164,128,102,135,143,149,155,203,224,186,204,210,237,261,218,219,286,257,266,361,355,336,302,374,339,371,398,340,409,348,388,494,436,407,406
6 1,1,2,5,4,2,6,13,11,4,10,10,12,6,8,29,16,11,18,20,12,10,22,26,29,12,38,30,28,8,30,61,20,16,24,55,36,18,24,52,40,12,42,50,44,22,46,58,55,29,32,60,52,38,40,78,36,28,58,40,60,30,66,125,48,20,66,80,44,24
9 0,31,59,90,120,151,181,212,243,273,304,334,365,396,424,455,485,516,546,577,608,638,669,699,730,761,789,820,850,881,911,942,973,1003,1034,1064,1095,1126,1155,1186,1216,1247,1277,1308,1339,1369,1400,1430
10 1,1,2,5,13,36,111,347,1134,3832,13126,46281,165283,598401,2202404,8168642,30653724,116082962,442503542,1701654889,6580937039,25603715395,100223117080,394001755683,1556876401398,6178202068457,24608353860698,98421159688268,394901524823138,1589722790850089
12 0,0,0,0,112,40286,5485032,534844548,45066853496,3538771308282,267882021563464,19861835713621616,1453175611052688600,105278656040052332838,7564280930105061931496
今までの私のコードは
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import math
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import SimpleRNN
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
from keras.preprocessing.sequence import pad_sequences
def stoarray(data = [], sep = ','):
return data.map(lambda x: np.array(x.split(sep), dtype=float))
def create_dataset(dataset, window_size=1):
dataX, dataY = [], []
for i in range(len(dataset)-window_size-1):
a = dataset[i:(i+window_size), 0]
dataX.append(a)
dataY.append(dataset[i + window_size, 0]) #gives the ValueError : Can only tuple index with multi index
return np.array(dataX), np.array(dataY)
# fix random seed for reproducibility
np.random.seed(7)
# loading data
colna = ['id', 'seq']
train_data = pd.read_csv('G:/Python/integer_sequencing/testfile.csv', header=1)
train_data.columns = colna
dataset = train_data['seq']
#print(dataset)
window_size = 1
X_train, Y_train = create_dataset(dataset, window_size)
print(X_train.head(5))
print(Y_train.head(5))
X_trainを入力として、最後の項を除く全セットからなるシーケンスを分割し、Y_trainは最後の桁のみからなる出力として扱おうとしています。 しかし、私はコードを実行すると、私はValueErrorを取得します。Can only tuple-index with a MultiIndex. どなたか、私のコードに関連して、それが何を意味するのか、また、それを解決するために何をしなければならないかを説明していただけますか?
トレースバックの呼び出しです。
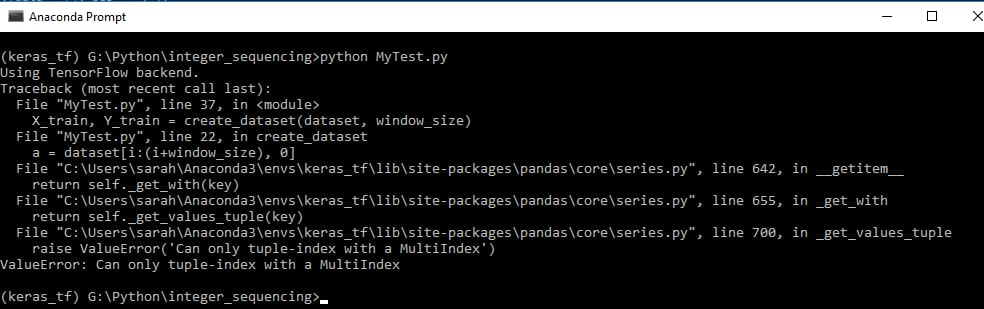
PS - 私はstack overflowと深層学習に新しいですので、私の質問のフォーマットで提案し、助けていただければ非常にありがたいです。
どのように解決するのですか?
で問題が発生した場合
i:(i+window_size), 0
で
dataset[i:(i+window_size), 0]
.
あなたのコードでは
dataset
というのは
train_data['seq']
これは、1 列 - 1 次元である
Series
- を使用していますが
i:(i+window_size), 0
のように、2次元の
DataFrame
.
のような単一の整数のみを使用することができます。
dataset[0]
またはスライス
dataset[i:(i+window_size)]
関連
-
[解決済み】 NameError: グローバル名 'xrange' は Python 3 で定義されていません。
-
[解決済み] builtins.TypeError: strでなければならない、bytesではない
-
[解決済み】syntaxError: 'continue' がループ内で適切に使用されていない
-
[解決済み] 'int'オブジェクトに'__getitem__'属性がない。
-
[解決済み] TypeError: 'DataFrame' オブジェクトは呼び出し可能ではない
-
[解決済み] Pythonで "with open "を使って複数のファイルを開くにはどうしたらいいですか?
-
[解決済み] ディクショナリーで最大値を持つキーを取得する?
-
[解決済み] リスト/タプルを指定されたインデックスにある要素でソートするには?
-
[解決済み] リストに対して max()/min() を使用して、返された最大または最小の項目のインデックスを取得する
-
[解決済み] 変数の値からpandas DataFrameを構築すると、「ValueError: すべてのスカラー値を使用する場合は、インデックスを渡す必要があります。"
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
opencvとpillowを用いた顔認証システム(デモあり)
-
pythonサイクルタスクスケジューリングツール スケジュール詳解
-
Python百行で韓服サークルの画像クロールを実現する
-
Pythonコードの可読性を向上させるツール「pycodestyle」の使い方を詳しく解説します
-
[解決済み】RuntimeWarning: invalid value encountered in double_scalars で numpy の除算ができない。
-
[解決済み】 AttributeError: モジュール 'matplotlib' には属性 'plot' がない。
-
[解決済み] 'DataFrame' オブジェクトに 'sort' 属性がない
-
[解決済み】インポートエラー。モジュール名 urllib2 がない
-
[解決済み】Python: SyntaxError: キーワードは式になり得ない
-
[解決済み】NameError: 名前 'self' が定義されていません。