Tensorflowのデータ(next_batch)を読み込む方法は以下の3つです。
Tensorflowのデータは、3つの方法で読み取ることができます。
- プリロードされたデータ プリロードされたデータ
- フィーディングを行う。Pythonがデータを生成し、それをバックエンドにフィードする。
- ファイルからの読み込み ファイルから直接読み込む
この3つの読み込み方法の違いは何でしょうか?まずはTensorFlow(TF)の仕組みを知る必要があります。
TFのコアはC++で書かれており、高速に動作するというメリットと、柔軟性のない呼び出しというデメリットがあります。Pythonはその逆なので、両言語の長所を兼ね備えています。PythonはこれらのAPIを呼び出して学習モデル(Graph)を設計し、設計したGraphをバックエンドに渡して実行させる。つまり、PythonはDesign、C++はRunという役割分担です。
I. データのプリロード
- <スパン インポート テンソルフローをtfとして
- <スパン # デザイングラフ
- x1 = tf.constant([ 2 , 3 , 4 ])
- x2 = tf.constant([ 4 , 0 , 1 ])
- y = tf.add(x1, x2)
- # セッションを開く --> 計算する y
- tf.Session()をsessとした場合。
- プリント sess.run(y)
II. pythonでデータを生成し、バックエンドに送り込む
- <スパン インポート テンソルフローをtfとして
- <スパン # デザイングラフ
- x1 = tf.placeholder(tf.int16)
- x2 = tf.placeholder(tf.int16)
- y = tf.add(x1, x2)
- # Pythonでデータを生成する
- li1 = [ 2 , 3 , 4 ]
- li2 = [ 4 , 0 , 1 ]
- <スパン # セッションを開く --> データをフィードする --> yを計算する
- tf.Session()をsessとした場合。
- プリント sess.run(y, feed_dict={x1: li1, x2: li2})
sess.run()
の中にある
feed_dict
パラメータで、Pythonで生成したデータをバックエンドに送り、yを計算します。
<スパン この2つの選択肢のデメリット
<スパン 1. プリロードです。 データを直接グラフにインライン化し、そのグラフをSessionに渡して実行する。データ量が比較的多い場合、Graphの転送は効率の問題が発生する .
2. データをプレースホルダーに置き換えて、実行時に入力されるようにします。
最初の2つの方法は便利です。
しかし、大きなデータになると圧倒されますし、Feedingでも中間リンクの追加はデータ型変換など、かなりのオーバーヘッドになります。
この場合、GUI(グラフィカル・ユーザー・インターフェース)を使用するのが最適です。最良の解決策は、Graphでファイル読み込みメソッドを定義し、TFにファイルからデータを読み込ませ、使用可能なサンプルセットにデコードさせることです。
3つ目は、ファイルからの読み込み、これは単純にデータ読み込みモジュールのグラフが構築されていることを意味します
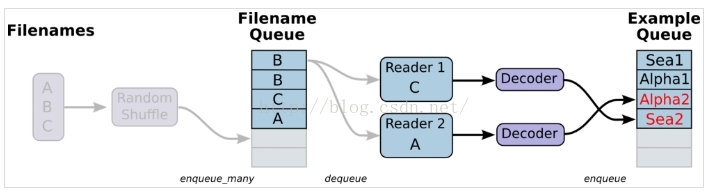
<スパン 1. データを用意し、A.csv,B.csv,C.csvの3つのファイルを作成します。
<スパン
- $ echo -e "Alpha1,A1nAlpha2,A2nAlpha3,A3" > A.csv
- $ echo -e "Bee1,B1nBee2,B2nBee3,B3" > B.csv
- $ echo -e "Sea1,C1nSea2,C2nSea3,C3" > C.csv
<スパン 2. シングルリーダー、シングルサンプル
- <スパン #-*- coding:utf-8 -*-.
- インポート テンソルフローをtfとして
- <スパン # 先入れ先出しのキューと、ファイル名キューを生成するQueueRunnerを生成する
- ファイル名 = [ 'A.csv' , 'B.csv' , 'C.csv'です。 ]
- filename_queue = tf.train.string_input_producer(filenames, shuffle=) 偽 )
- # リーダーの定義
- reader = tf.TextLineReader()
- key, value = reader.read(filename_queue)
- # デコーダーの定義
- 例:label = tf.decode_csv(value, record_defaults=[) 'ヌル' ], [ 'ヌル' ]])
- <スパン #example_batch, label_batch = tf.train.shuffle_batch([example,label], batch_size=1, capacity=200, min_after_dequeue=100, num_threads=2)
- # 実行グラフ
- tf.Session()をsessとした場合。
- coord = tf.train.Coordinator() # スレッドを管理するコーディネーターを作成する
- threads = tf.train.start_queue_runners(coord=coord) # ファイル名キューが入ったので、QueueRunnerを開始します。
- について i で 範囲( 10 ):
- プリント example.eval(),label.eval()を実行します。
- coord.request_stop()
- coord.join(threads)
α1 A2
α3 B1
Bee2 B3
海1 C2
海3 A1
α2 A3
Bee1 B2
Bee3 C1
海2 C3
アルファ1 A2
<スパン 解決方法 tf.train.shuffle_batchを使用することで、生成された結果を対応させることができます。
- <スパン #-*- coding:utf-8 -*-.
- インポート テンソルフローをtfとして
- <スパン # 先入れ先出しのキューと、ファイル名キューを生成するQueueRunnerを生成する
- ファイル名 = [ 'A.csv' , 'B.csv' , 'C.csv'です。 ]
- filename_queue = tf.train.string_input_producer(filenames, shuffle=) 偽 )
- # リーダーの定義
- reader = tf.TextLineReader()
- key, value = reader.read(filename_queue)
- # デコーダーの定義
- 例:label = tf.decode_csv(value, record_defaults=[) 'ヌル' ], [ 'ヌル' ]])
- example_batch, label_batch = tf.train.shuffle_batch([example,label], batch_size=) 1 容量 <スパン 200 min_after_dequeue= 100 , num_threads= <スパン 2 )
- # 実行グラフ
- tf.Session()をsessとした場合。
- coord = tf.train.Coordinator() # スレッドを管理するコーディネーターを作成する
- threads = tf.train.start_queue_runners(coord=coord) # ファイル名キューが入ったので、QueueRunnerを開始します。
- について i で 範囲( 10 ):
- e_val,l_val = sess.run([example_batch, label_batch])
- プリント e_val、l_val
- coord.request_stop()
- coord.join(threads)
<スパン 3. シングルリーダー、マルチサンプル、も主に使われています。 tf.train.shuffle_batch で実現する。 <スパン
- <スパン #-*- coding:utf-8 -*-.
- インポート テンソルフローをtfとして
- ファイル名 = [ 'A.csv' , 'B.csv' , 'C.csv'です。 ]
- filename_queue = tf.train.string_input_producer(filenames, shuffle=) 偽 )
- reader = tf.TextLineReader()
- key, value = reader.read(filename_queue)
- 例, label = tf.decode_csv(value, record_defaults=[[]) 'ヌル' ], [
関連
-
Java Exceptionが発生しました
-
メインクラス org.codehaus.plexus.classworlds.launcher.Launcher MAC が見つからない、またはロードできないエラーが以下に報告されています。
-
tomcat起動時のエラー java.lang.ClassNotFoundException を解決する。
-
jinja2.exceptions.TemplateNotFound: xxxx.html
-
画像ダウンロードの問題
-
Python 3.9 のモジュール 'time' には 'clock' という属性がありません。
-
RabbitMQ起動時のトラブルと解決方法
-
Python3_TypeError: 'list' オブジェクトは呼び出し可能ではありません。
-
[違反】スクロールブロックの「mousewheel」イベントに非パッシブなイベントリスナーを追加。
-
Android ConstraintLayout app:layout_constraintHorizontal_bias について解説します。
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
! 拒否]マスター->マスター(フェッチファースト)問題の解決法
-
python prompts ImportError: Image という名前のモジュールがありません。
-
を作ってください。*** ターゲットが指定されておらず、makefileも見つかりませんでした。
-
liunx, makeでmysqlをインストール *** ターゲットが指定されておらず、makefileも見つかりませんでしたので停止しました。
-
OSError: [Errno 98] アドレスはすでに使用中です。
-
Pycharm コード ドッカー コンテナ 実行 デバッグ|機械学習シリーズ
-
raise JSONDecodeError("Expecting value", s, err.value) from None
-
tf.variable_scope パラメータ
-
未定義参照発生時のcmakeの扱いについて
-
SQLステートメント共通エラー。"不明な列 'xxx' in 'where 節 "どのように解決するには?