TensorFlowにおける勾配降下とAdagradとMomentumの比較
2023-10-13 18:55:45
質問
勉強中です。 TensorFlow や、ニューラルネットワークやディープラーニングの専門家ではない(基礎だけ)私でも、その使い方を学ぶことができます。
チュートリアルに沿って、lossの3つのオプティマイザーの実際の実用的な違いがわからない。私が見ているのは API を見て、私は原理を理解していますが、私の質問は、次のとおりです。
1. どのような場合に、他のものを使用するのではなく、1つを使用することが望ましいのでしょうか?
2. 知っておくべき重要な違いはありますか?
どのように解決するのですか?
私の理解に基づいて、簡単に説明します。
- 運動量 役立つ SGDは関連する方向に沿って移動し、無関係の振動を和らげます。これは、現在のステップに、前のステップの方向の何分の一かを追加するだけです。これにより、正しい方向への速度の増幅と、誤った方向への振動の緩和が実現されます。この分数は通常(0, 1)の範囲にある。また、適応的な運動量を使用することも意味がある。学習の初期には、大きな運動量は上達を妨げるだけなので、0.01のようなものを使うのが理にかなっており、高い勾配がすべて消えたら、より大きな運動量を使うことができる。ゴールに近づいたとき、ほとんどの場合、勢いは非常に大きくなり、減速すべきことを認識できなくなります。このため、極小値付近で振動したり、失敗したりすることがあります。
- ネストロフ加速度勾配 は、早期に減速を開始することでこの問題を克服しています。運動量では、まず勾配を計算し、次にその方向へジャンプし、以前に持っていた運動量によって増幅されます。NAGは同じことをしますが、順序が違います。最初に蓄積された情報に基づいて大きくジャンプし、次に勾配を計算して小さく修正します。この一見関係ないような変化が、実用上の大きなスピードアップにつながるのです。
- AdaGrad または適応的勾配は、パラメータに基づいて学習率を適応させることができます。頻度の低いパラメータには大きな更新を、頻度の高いパラメータには小さな更新を行う。このため、疎なデータ(NLPや画像認識など)に適しています。もう一つの利点は、基本的に学習率を調整する必要がないことである。各パラメータは独自の学習速度を持ち、アルゴリズムの特性上、学習速度は単調減少する。これが最大の問題で、ある時点で学習率が非常に小さくなり、システムが学習を停止してしまうのです。
- AdaDelta は解決する は、AdaGrad における学習率が単調に減少する問題を解決する。AdaGradでは、学習率はおよそ1を平方根の合計で割ったものとして計算されていた。各ステージで、合計に別の平方根を加えるので、分母が常に増加することになる。AdaDeltaでは、過去のすべての平方根を合計するのではなく、スライディングウィンドウを用いて、合計を減少させることができます。 RMSprop はAdaDeltaに非常に似ています。
-
アダム やadaptive momentumはAdaDeltaに似たアルゴリズムです。しかし、各パラメータの学習率を保存することに加えて、各パラメータの運動量変化を別々に保存します。
A 少数の可視化 :
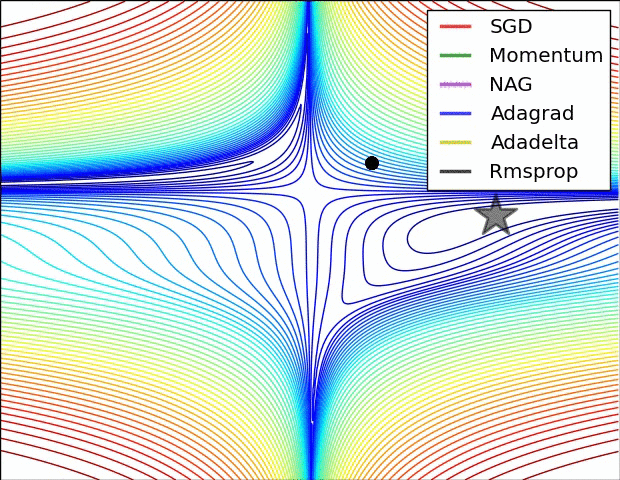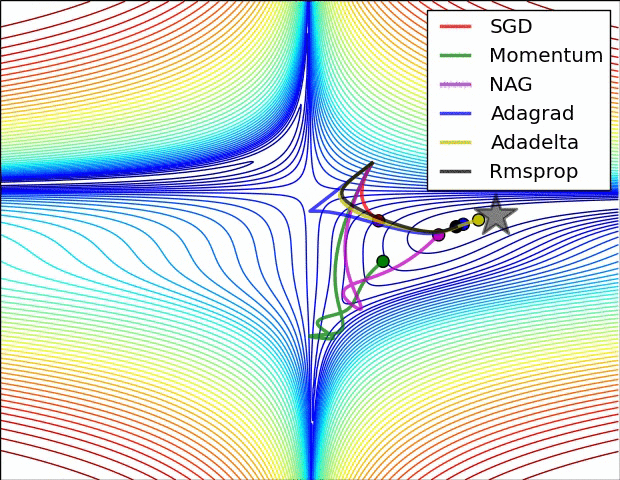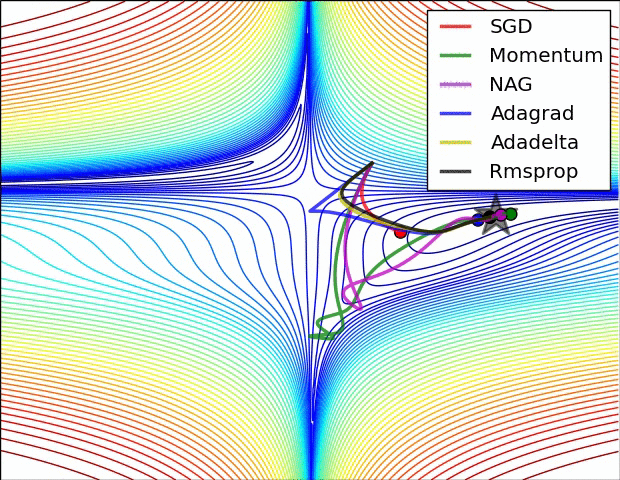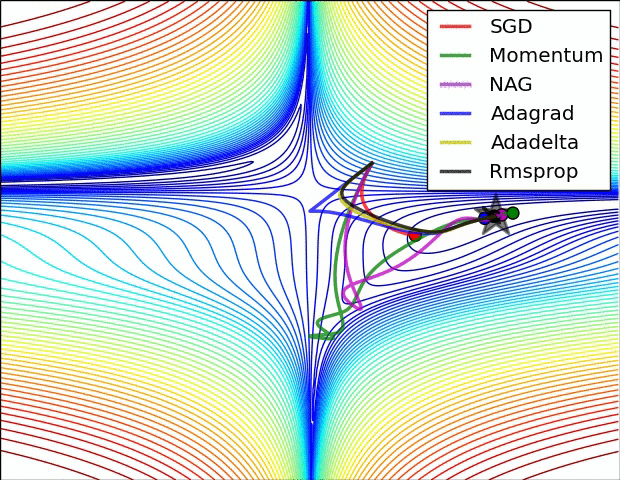
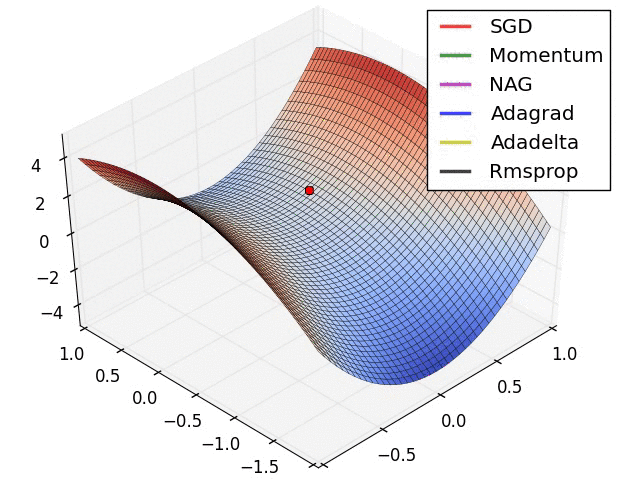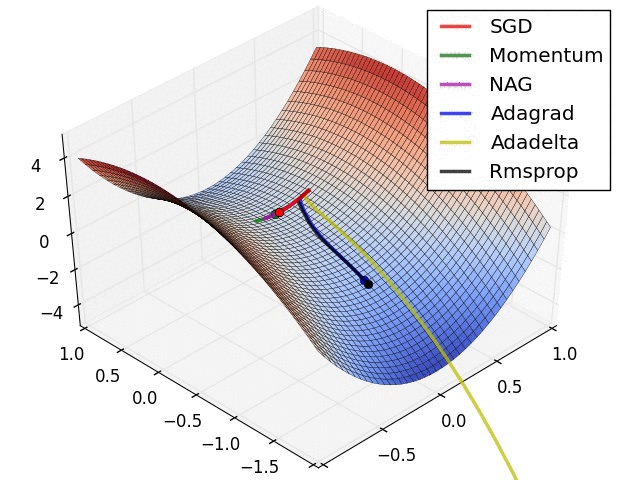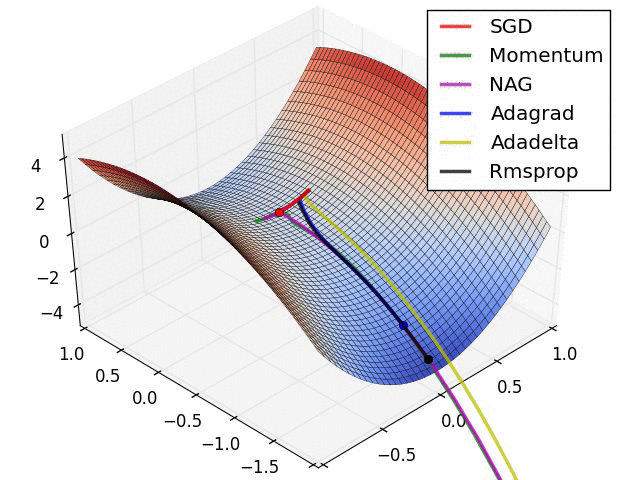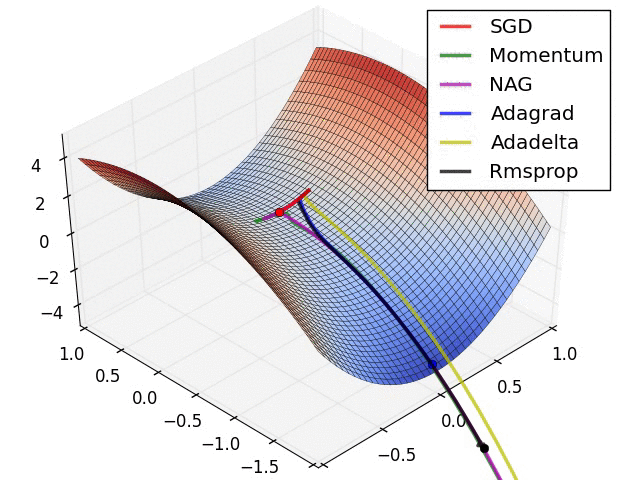
SGD、モメンタム、ネステロフが前の3人より劣っていると言えるでしょう。
関連
-
Running tensorflow program prompts Your CPU supports instructions that this TensorFlow binary was not compiled to use:
-
TensorflowでProcess finished with exit code -1073741819 (0xC0000005)が発生した場合の解決策。
-
GPU版TensorFlowの正常なインストールをテストします。
-
TensorFlowプログラムのGPU使用量無制限を解決する。
-
TensorFlowのインストールにpipを使うのをやめ、condaを使う(CPU & GPU)
-
[解決済み] TensorFlow、なぜpythonが選ばれたのか?
-
[解決済み] TensorFlowでクロスエントロピーの損失を選択するには?
-
[解決済み] TensorFlowで正則化を追加するには?
-
[解決済み] TensorFlowモデルで予測する
-
tf.Session()とtf.InteractiveSession()の違いは何ですか?
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
Running tensorflow program prompts Your CPU supports instructions that this TensorFlow binary was not compiled to use:
-
undefined警告 お使いのCPUは、このTensorFlowバイナリが使用するためにコンパイルされていない命令をサポートしています。AVX2
-
EnvironmentErrorのため、パッケージをインストールできませんでした。[Errno 13] パーミッションが拒否された問題を解決しました。
-
TensorFlowの問題:AttributeError:'NoneType'オブジェクトには'dtype'という属性がない。
-
tensorflow Solutionに一致するディストリビューションは見つかりませんでした。
-
GPU版TensorFlowの正常なインストールをテストします。
-
TensorFlowのインストールにpipを使うのをやめ、condaを使う(CPU & GPU)
-
[解決済み] Dataset.map, Dataset.prefetch, Dataset.shuffleにおけるbuffer_sizeの意味するところ
-
[解決済み] TensorBoardはGoogle Colabと一緒に使えますか?
-
[解決済み] TensorFlowモデルで予測する