[解決済み] カクテルパーティーアルゴリズム SVD の実装 ... 1行のコードで?
質問
CourseraのスタンフォードのAndrew Ngによる機械学習の入門講義の中のスライドで、彼は、音声ソースが2つの空間的に離れたマイクによって録音されている場合、カクテルパーティー問題に対する次の1行のOctaveの解を与えています。
[W,s,v]=svd((repmat(sum(x.*x,1),size(x,1),1).*x)*x');
スライドの下部には "出典: Sam Roweis, Yair Weiss, Eero Simoncelli" とあり、以前のスライドの下部には "Audio clips courtesy of Te-Won Lee" と書かれています。動画の中で、Ng教授はこう言っています。
このアプリケーションを構築するために、この音声処理を行うには、大量のコードを書くか、音声を処理する多数の C++ または Java ライブラリにリンクする必要があるように思われます。音声の分離など、音声処理を行うには本当に複雑なプログラムになりそうです。しかし、今聞いたようなことをするためのアルゴリズムは、たった1行のコードでできることがわかりました......ここに示されています。この1行のコードを考え出すのに研究者は長い時間を要しました。だから、これが簡単な問題だとは言いません。しかし、正しいプログラミング環境を使えば、多くの学習アルゴリズムが本当に短いプログラムになることがわかりました。
ビデオ講義で流れた分離音声の結果は完璧ではありませんが、私の意見としては素晴らしいものでした。この 1 行のコードがどのようにうまく動作するか、どなたかご存知でしょうか。特に、その 1 行のコードに関する Te-Won Lee、Sam Roweis、Yair Weiss、および Eero Simoncelli の仕事を説明する文献をご存知の方はいらっしゃいますか?
アップデイト
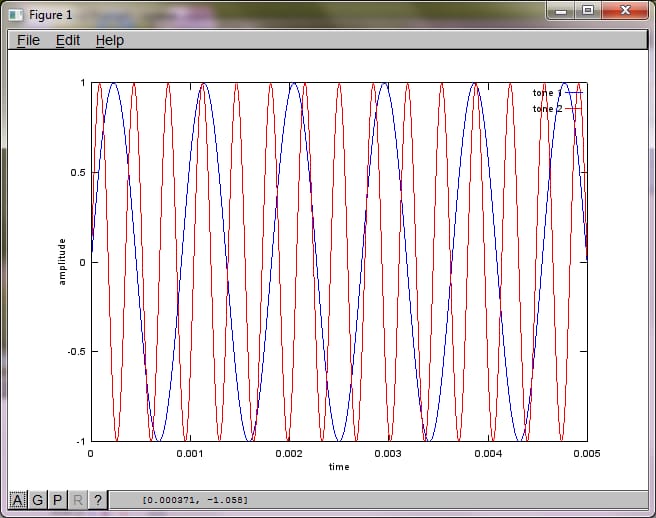
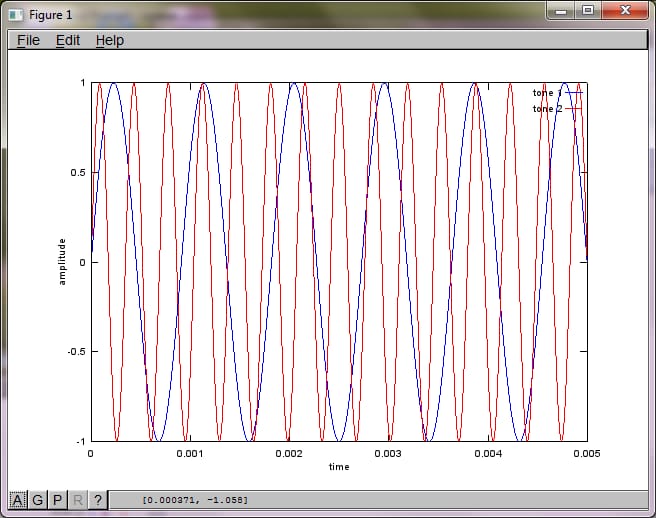
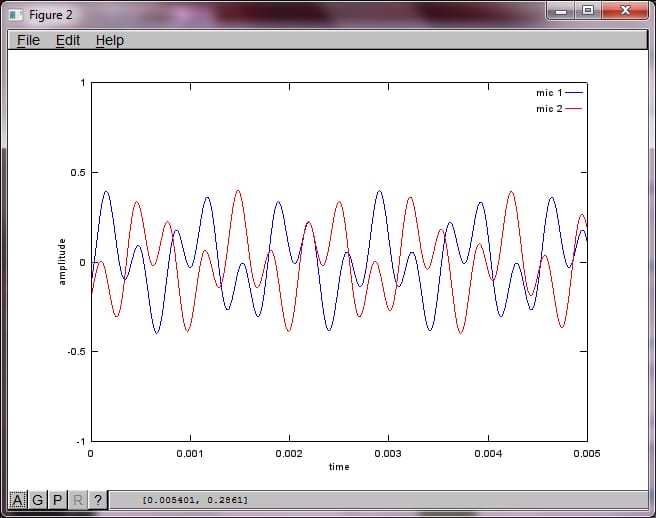
マイクの距離に対するアルゴリズムの感度を示すために、次のシミュレーション(オクターブ)は、空間的に分離した2つのトーンジェネレータからのトーンを分離します。
% define model
f1 = 1100; % frequency of tone generator 1; unit: Hz
f2 = 2900; % frequency of tone generator 2; unit: Hz
Ts = 1/(40*max(f1,f2)); % sampling period; unit: s
dMic = 1; % distance between microphones centered about origin; unit: m
dSrc = 10; % distance between tone generators centered about origin; unit: m
c = 340.29; % speed of sound; unit: m / s
% generate tones
figure(1);
t = [0:Ts:0.025];
tone1 = sin(2*pi*f1*t);
tone2 = sin(2*pi*f2*t);
plot(t,tone1);
hold on;
plot(t,tone2,'r'); xlabel('time'); ylabel('amplitude'); axis([0 0.005 -1 1]); legend('tone 1', 'tone 2');
hold off;
% mix tones at microphones
% assume inverse square attenuation of sound intensity (i.e., inverse linear attenuation of sound amplitude)
figure(2);
dNear = (dSrc - dMic)/2;
dFar = (dSrc + dMic)/2;
mic1 = 1/dNear*sin(2*pi*f1*(t-dNear/c)) + \
1/dFar*sin(2*pi*f2*(t-dFar/c));
mic2 = 1/dNear*sin(2*pi*f2*(t-dNear/c)) + \
1/dFar*sin(2*pi*f1*(t-dFar/c));
plot(t,mic1);
hold on;
plot(t,mic2,'r'); xlabel('time'); ylabel('amplitude'); axis([0 0.005 -1 1]); legend('mic 1', 'mic 2');
hold off;
% use svd to isolate sound sources
figure(3);
x = [mic1' mic2'];
[W,s,v]=svd((repmat(sum(x.*x,1),size(x,1),1).*x)*x');
plot(t,v(:,1));
hold on;
maxAmp = max(v(:,1));
plot(t,v(:,2),'r'); xlabel('time'); ylabel('amplitude'); axis([0 0.005 -maxAmp maxAmp]); legend('isolated tone 1', 'isolated tone 2');
hold off;
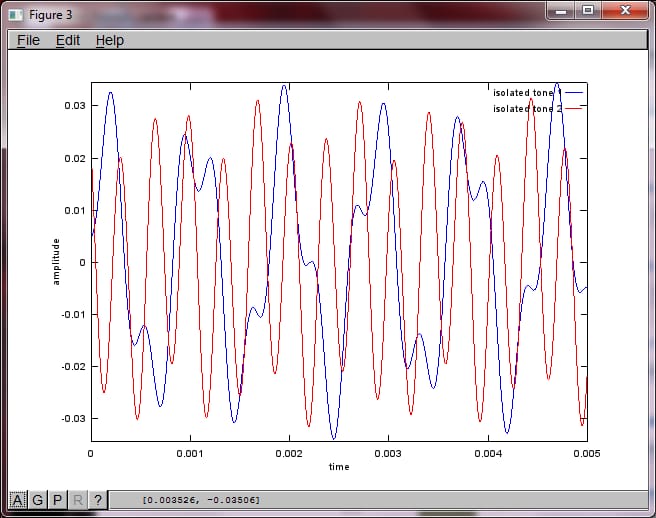
私のラップトップ コンピュータで約 10 分間実行した後、シミュレーションは次の 3 つの図を生成し、2 つの孤立した音が正しい周波数を持っていることを示しました。
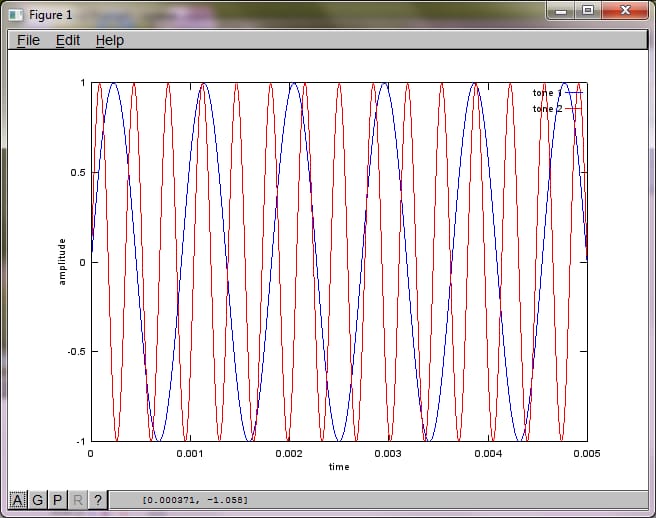
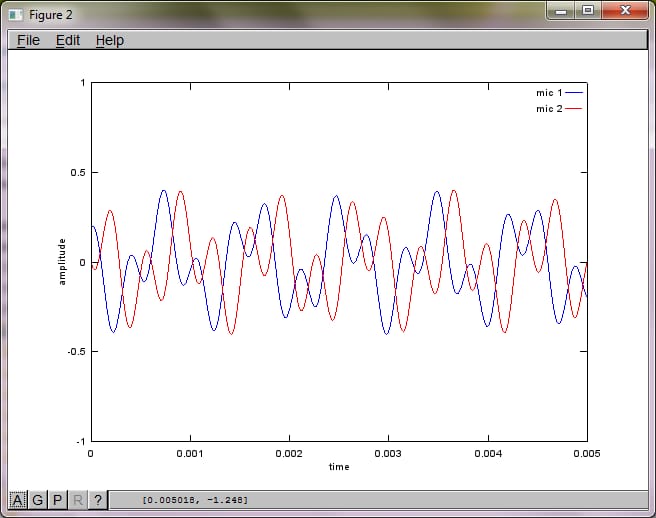
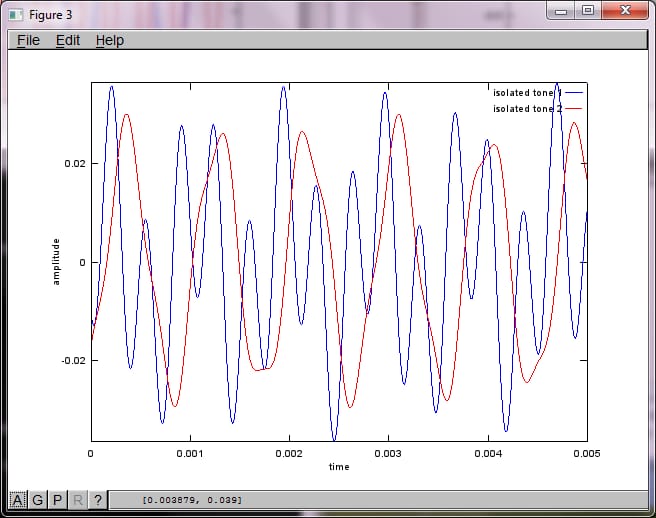
しかし、マイクの分離距離をゼロに設定する (すなわち、dMic = 0) と、シミュレーションは次の3つの図を生成し、シミュレーションが2番目のトーンを分離できなかったことを示します (svd のマトリックスで返される単一の有意な対角項によって確認されます)。
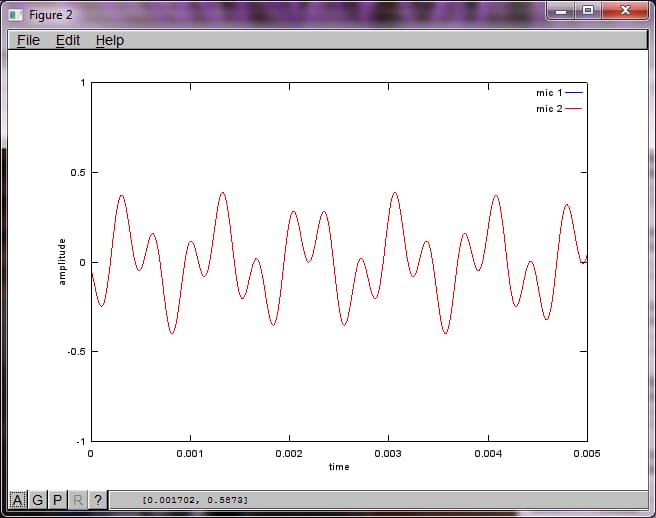
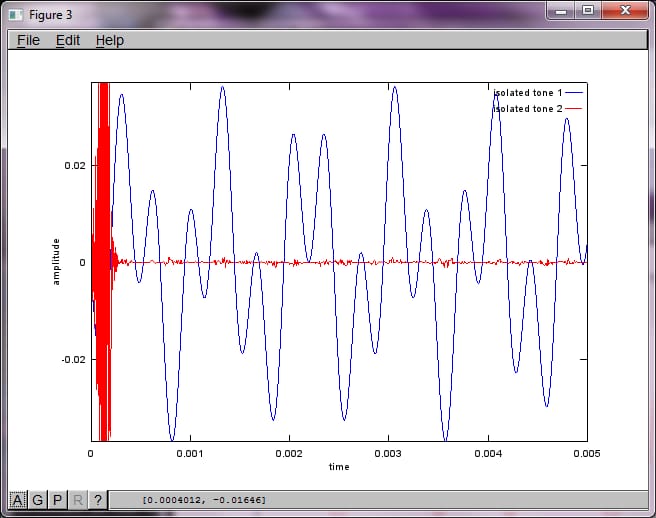
スマートフォンのマイクの離隔距離を十分に大きくして良い結果を得られると期待していましたが、マイクの離隔距離を 5.25 インチ (すなわち dMic = 0.1333 m) に設定すると、シミュレーションでは、最初の孤立音の高い周波数成分を示す、あまり期待できない次の図が生成されました。
どのように解決するのですか?
私は2年後に、同様にこれを理解しようとしていました。しかし、私は私の答えを得た。それは誰かの助けになることを願っています。
2つのオーディオ録音が必要です。以下のサイトからサンプル音声を入手できます。 http://research.ics.aalto.fi/ica/cocktail/cocktail_en.cgi .
実装のリファレンスは http://www.cs.nyu.edu/~roweis/kica.html
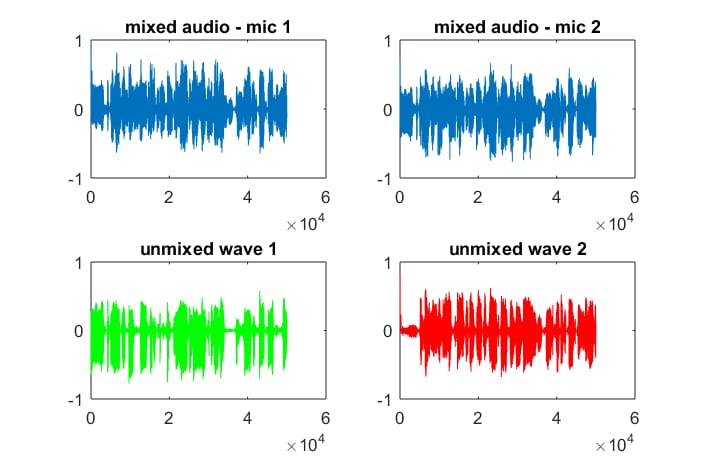
OK、これがそのコードです。
[x1, Fs1] = audioread('mix1.wav');
[x2, Fs2] = audioread('mix2.wav');
xx = [x1, x2]';
yy = sqrtm(inv(cov(xx')))*(xx-repmat(mean(xx,2),1,size(xx,2)));
[W,s,v] = svd((repmat(sum(yy.*yy,1),size(yy,1),1).*yy)*yy');
a = W*xx; %W is unmixing matrix
subplot(2,2,1); plot(x1); title('mixed audio - mic 1');
subplot(2,2,2); plot(x2); title('mixed audio - mic 2');
subplot(2,2,3); plot(a(1,:), 'g'); title('unmixed wave 1');
subplot(2,2,4); plot(a(2,:),'r'); title('unmixed wave 2');
audiowrite('unmixed1.wav', a(1,:), Fs1);
audiowrite('unmixed2.wav', a(2,:), Fs1);
関連
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン