[解決済み] SQL ServerでVARCHAR/CHARの代わりにNVARCHAR/NCHARを使用しなければならないのはどのような場合ですか?
質問
Unicodeの型を使用しなければならない決まりはありますか?
私は、ほとんどのヨーロッパ言語(ドイツ語、イタリア語、英語、...)が、同じデータベースでVARCHARカラムで問題ないことを見てきました。
私は、次のようなものを探しています。
- 中国語がある場合 --> NVARCHARを使用します。
- ドイツ語とアラビア語がある場合 --> NVARCHARを使用します。
サーバー/データベースの照合順序はどうなっていますか?
ここで提案されているように、常にNVARCHARを使用したいわけではありません。 varchar と nvarchar SQL Server データ型の主なパフォーマンスの違いは何ですか?
どのように解決するのですか?
最も多く投票された 2 つの回答はどちらも間違っています。それは、quot;異なる/複数の言語を保存する" とは関係ないはずです。以下のようなスペイン語の文字をサポートすることができます。
ñ
のようなスペイン語の文字も、英語の文字も、単に共通の
varchar
フィールドと
Latin1_General_CI_AS
COLLATION
のように、例えば
ショートバージョン
を使用する必要があります。
NVARCHAR
/
NCHAR
はいつでも
ENCODING
によって決定される。
COLLATION
で決定されますが、必要な文字がサポートされていません。
また、SQL Server のバージョンによっては、特定の
COLLATIONs
のように
Latin1_General_100_CI_AS_SC_UTF8
という、SQL Server 2019 から利用できるようになりました。この照合順序を設定することで
VARCHAR
フィールド (またはテーブル/データベース全体) にこの照合順序を設定すると
UTF-8
ENCODING
を使用し、そのフィールドのデータの保存と処理に使用します。
UNICODE
文字を完全にサポートし、それ故にそれによって受け入れられるあらゆる言語が可能になります。
FULLY UNDERSTAND(完全に理解する)ために。
<サブ
これから説明することを完全に理解するためには、以下の概念が必要不可欠です。
UNICODE
,
ENCODING
と
COLLATION
はすべて、あなたの頭の中で非常に明確になっています。 そうでない場合は、まず以下の「UNICODE、ENCODING、COLLATION、UTF-8とは何か、そしてそれらがどのように関連しているか」についての私の謙虚で簡素な説明と付属のドキュメントリンクに目を通してください。また、私がここで言うことはすべて
Microsoft SQL Server
でのデータの保存と処理方法についてです。
char
/
nchar
そして
varchar
/
nvarchar
のフィールドがあります。
例えば、MSSQL Serverデータベースに独特なテキストを保存したいとします。それは、Instagramのコメントで、「I love stackoverflow! というようなInstagramのコメントかもしれません。
平易な英語の部分はASCIIでも完全にサポートされていますが、絵文字も存在するので、これは
UNICODE
規格で指定された文字である絵文字があるため
ENCODING
をサポートする必要があります。
MSSQL Server は
COLLATION
を決定するために、どのような
ENCODING
で使用されます。
char
/
nchar
/
varchar
/
nvarchar
のフィールドがあります。ですから、多くの人が考えるのとは違って
COLLATION
は
のみならず、データの並べ替えや比較、そして
ENCODING
といった、結果的に
データがどのように保存されるか
だから 照合順序で使用されるエンコーディングが何であるかをどのように知ることができますか? これを使えば
SELECT COLLATIONPROPERTY( 'Latin1_General_CI_AI' , 'CodePage' ) AS [CodePage]
--returns 1252
この単純なSQLは
Windows Code Page
に対して
COLLATION
. A
Windows Code Page
への別のマッピングに過ぎません。
ENCODINGs
. そのため
Latin1_General_CI_AI
COLLATION
を返します。
Windows Code Page
コード
1252
に対応する
Windows-1252
ENCODING
.
つまり
varchar
カラムでは
Latin1_General_CI_AI
COLLATION
である場合、このフィールドは
Windows-1252
ENCODING
を使ってデータを扱い、このエンコーディングでサポートされている文字だけを正しく保存します。
をチェックすると
Windows-1252 ENCODING
仕様
Windows-1252用文字一覧
と記述すると、このエンコーディングでは絵文字がサポートされないことがわかります。そして、もしそれでも試してみるなら
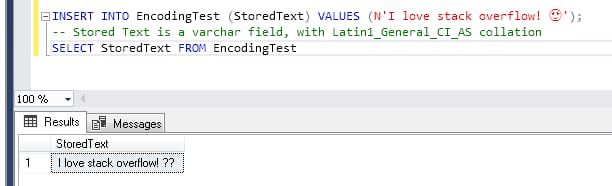
OK、ではどうすればこれを解決できるのでしょうか? 実は、それ次第で、GOOD!
NCHAR
/
NVARCHAR
SQL Server 2019 以前には、私たちが持っていたのは
NCHAR
そして
NVARCHAR
のフィールドがあります。ある人は、それらが
UNICODE
のフィールドになります。
と言う人もいます。
それは間違いだ!
. 繰り返しになりますが、それはフィールドの
COLLATION
と SQLServer のバージョンにも依存します。
マイクロソフトの
nchar および nvarchar (Transact-SQL)" documentation
は完璧に指定しています。
SQL Server 2012 (11.x) 以降、SC (Supplementary Character) を有効にした照合順序で 補足文字(SC)が有効な照合順序が使用されている場合、これらのデータ型は Unicode 文字データの全範囲を格納し、そのデータを使用します。 これらのデータ型は、Unicode 文字データの全範囲を格納し、UTF-16 文字エンコードを使用します。 UTF-16 文字エンコードを使用します。非SC照合順序が指定された場合 これらのデータ型は、UCS-2 文字エンコーディングでサポートされる文字データのサブセットのみを格納します。 UCS-2 文字エンコーディングがサポートする文字データのサブセットのみを格納します。
言い換えると、たとえば SQL Server 2008 R2 のように、2012 よりも古い SQL Server を使用する場合、このデータ型は
ENCODING
を使用することになります。
UCS-2 ENCODING
のサブセットをサポートする
UNICODE
. しかし、SQL Server 2012 以降を使用する場合、このメソッドで
COLLATION
を定義すると
Supplementary Character
が有効になっている場合、私たちのフィールドを使用するよりも
UTF-16
ENCODING
を完全にサポートする
UNICODE
.
が、なんと、まだあるのです! utf-8が使えるようになったんです!
CHAR
/
VARCHAR
SQL Server 2019から始まる。
を使用することができます。
CHAR
/
VARCHAR
フィールドを完全にサポートし、なおかつ
UNICODE
を使用して
UTF-8
ENCODING
!!!
マイクロソフトの char および varchar (Transact-SQL)" ドキュメントより。 :
SQL Server 2019 (15.x) 以降では、以下のような場合に UTF-8 が有効な照合順序が使用される場合、これらのデータ型は完全な範囲を保存します。 の Unicode 文字データを格納し、UTF-8 文字エンコーディングを使用します。もし 非UTF-8照合順序が指定された場合、これらのデータ型は対応する文字がサポートするサブセットのみを格納します。 の対応するコードページでサポートされる文字のサブセットのみを格納します。 のサブセットのみを格納します。
繰り返しますが、言い換えれば、たとえば SQL Server 2008 R2 のような 2019 年より古い SQL Server を使用する場合、SQL Server 2008 R2 で使用された照合順序を確認する必要があります。
ENCODING
を先ほど説明した方法で確認する必要があります。しかし、SQL Server 2019以降を使用し、定義された
COLLATION
のように
Latin1_General_100_CI_AS_SC_UTF8
のようにすると、私たちのフィールドは
UTF-8
ENCODING
これは最もよく使われる効率的なエンコーディングで、すべての
UNICODE
文字をサポートしています。
ボーナス情報です。
OPの観察について ヨーロッパの言語 (ドイツ語、イタリア語、英語、...) のほとんどは、同じデータベース内で VARCHAR 列で問題ないことを確認しました。 は、その理由を知ることはいいことだと思います。
最も一般的な
COLLATIONs
のように、デフォルトのものは
Latin1_General_CI_AI
または
SQL_Latin1_General_CP1_CI_AS
は
ENCODING
になります。
Windows-1252
に対して
varchar
のフィールドを使用します。もし、その
ドキュメント
を見ると、それがサポートしていることがわかります。
英語、アイルランド語、イタリア語、ノルウェー語、ポルトガル語、スペイン語、スウェーデン語。さらに ドイツ語、フィンランド語、フランス語も。そして IJ を除いたオランダ語。
絵文字の例や、quot;The electric resistance of a lithium battery is 0.5Ω" のような文では、またしても平文で、ギリシャ文字/文字の "omega" (オーム単位の抵抗の記号)があり、これは、Windows-1252
ENCODING
.
結論
ということで、これにて終了です を使用する場合
char
/
nchar
そして
varchar
/
nvarchar
は、サポートしたい文字に依存し、またどの
COLLATIONs
を決定する SQL Server のバージョンにも依存します。
ENCODINGs
が利用できるようになります。
UNICODE、ENCODING、COLLATION、UTF-8とは何か、またどのような関係があるのか。
注:以下の説明はすべて
簡略化
. これらの概念に関するすべての詳細を知るために、供給されたドキュメントのリンクを参照してください。
-
UNICODE- 統一され、組織化された表ですべての文字を規制することを目的とした規格、慣習である。この表では、すべての文字が固有の番号を持っています。この番号は、一般にキャラクタのcode point.
unicodeはエンコーディングではありません! -
ENCODING- 文字とバイト/バイト列の間のマッピングです。つまり、エンコーディングは文字からバイトへ、あるいは逆にバイトから文字へ変換するために使用されます。最も一般的なものはUTF-8,ISO-8859-1,Windows-1252とASCII. これは、変換表と考えることができます(ここでは本当に単純化しています)。 -
COLLATION- これは重要ですね。マイクロソフトのドキュメントでさえ、このことを明確にはしていません。照合順序は、データがどのように並べられるか、比較されるかを指定します。 そして保存される! . そう、最後の1つは予想外だったでしょう?の照合はSQL Serverの照合順序も決定されます。ENCODINGは、その特定のchar/nchar/varchar/nvarcharフィールドを使用します。 -
ASCII ENCODING- 最初のエンコーディングの一つです。これは、文字テーブル(UNICODEの小さなバージョンのようなもの)とそのバイトマッピングの両方です。ですから、バイトをUNICODEにマッピングするのではなく、バイトを独自の文字テーブルにマッピングしています。また、常に7ビットしか使わず、128種類の文字をサポートしていた。これは、英字の大文字と小文字、数字、句読点、その他限られた数の文字をサポートするには十分なものでした。ASCIIの問題は、7ビットしか使わず、当時はほとんどすべてのコンピュータが8ビットだったので、さらに128種類の文字の可能性があり、誰もがこのバイトを独自の文字テーブルにマッピングし始め、多くの異なる文字を作り出したということです。ENCODINGs. -
UTF-8 ENCODING- これは別のENCODINGは、最もよく使われる(とまではいかないが)ものの1つであるENCODINGの周りで最も使われているものの一つです。これは可変バイト幅を使用し (仕様上、1 文字は 1 バイトから 6 バイトの長さになります)、すべてのUNICODE文字を完全にサポートします。 -
Windows-1252 ENCODING- また、最もよく使われるものの一つであるENCODINGも、最もよく使われるの一つで、SQL Server で広く使われています。固定サイズなので、1文字が常に1バイトになります。また、様々な言語の多くのアクセントをサポートしていますが、既存のすべてのアクセントをサポートしているわけではありません。 UNICODE. そのため、あなたのvarcharのような一般的な照合順序を持つフィールドがLatin1_General_CI_ASがサポートします。á,é,ñという文字があり、サポートされていないものでもUNICODEENCODING.
リソース
https://blog.greglow.com/2019/07/25/sql-think-that-varchar-characters-if-so-think-again/
https://medium.com/@apiltamang/unicode-utf-8-and-ascii-encodings-made-easy-5bfbe3a1c45a
https://www.johndcook.com/blog/2019/09/09/how-utf-8-works/
https://www.w3.org/International/questions/qa-what-is-encoding
https://en.wikipedia.org/wiki/List_of_Unicode_characters
https://www.fileformat.info/info/charset/windows-1252/list.htm
https://docs.microsoft.com/en-us/sql/t-sql/data-types/char-and-varchar-transact-sql?view=sql-server-ver15
https://docs.microsoft.com/en-us/sql/t-sql/data-types/nchar-and-nvarchar-transact-sql?view=sql-server-ver15
https://docs.microsoft.com/en-us/sql/t-sql/statements/windows-collation-name-transact-sql?view=sql-server-ver15
https://docs.microsoft.com/en-us/sql/t-sql/statements/sql-server-collation-name-transact-sql?view=sql-server-ver15
https://docs.microsoft.com/en-us/sql/relational-databases/collations/collation-and-unicode-support?view=sql-server-ver15#SQL-collations
SQL Server のデフォルトの文字エンコーディング
https://en.wikipedia.org/wiki/Windows_code_page
関連
-
[解決済み】PRIMARY KEY制約に違反しました。オブジェクトに重複したキーを挿入できない
-
[解決済み] 更新時のSqlエラー : UPDATE ステートメントが FOREIGN KEY 制約と競合しています。
-
[解決済み] SSRS レポートの定義が無効です。
-
[解決済み] SQL Server データベース復元エラー: 指定されたキャストは無効です。(SqlManagerUI)
-
[解決済み] 分散型トランザクションを開始できない
-
[解決済み] ')' 付近の構文が正しくない場合の対処方法
-
[解決済み] SQLでNaN値をNULLに、またはNaNを0に変換する
-
[解決済み] SQL Serverでforeachを記述する方法とは?
-
[解決済み] SQL Serverにおけるchar、nchar、varchar、nvarcharの違いは何ですか?
-
[解決済み] SQL Server の VARCHAR/NVARCHAR 文字列に改行を挿入する方法
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み】エラー "INSERT EXEC文はネストできません。" "INSERT-EXEC文の中でROLLBACK文は使用できません。" これを解決するにはどうすればよいですか?
-
[解決済み] SQL Server Error "String Data, Right Truncation "の意味と修正方法について教えてください。
-
[解決済み] SQL Serverでシングルクォートを置換する
-
[解決済み] SQL Server の更新コマンドでエラー - "現在のコマンドで深刻なエラーが発生しました".
-
[解決済み] パーセント値を保持するための適切なデータ型?
-
[解決済み] データベースのトランザクションログが満杯です。ログの領域が再利用できない理由を調べるには、sys.databases の log_reuse_wait_desc カラムを参照してください。
-
[解決済み] データセットに対するSSRSクエリの実行に失敗しました
-
[解決済み] SQL ServerでGROUP BYと一緒にDISTINCTを使用する
-
[解決済み] データベース内の全テーブルのサイズを取得する
-
[解決済み】varcharとnvarcharのSQL Serverデータ型の主なパフォーマンスの違いは何ですか?