[解決済み] SQL Serverの実行プランで「クラスター化インデックススキャン(クラスター化)」が意味するものは?
質問
ファイルグループ 'DEFAULT' のディスク容量が不足しているため、データベース 'TEMPDB' に新しいページを割り当てることができませんでした」と表示されて実行できないクエリがあります。
トラブルシューティングの途中で、実行計画を調べています。Clustered Index Scan (Clustered) "と書かれたコストのかかるステップが2つあります。私はこれが何を意味するのか見つけるのに苦労しています?
Clustered Index Scan (Clustered) "の説明や、関連ドキュメントの場所を教えていただけませんか?
どのように解決するのですか?
<ブロッククオートクラスタ化インデックススキャンについて教えてください。 (クラスター化)"。
インデックスシークとスキャンの両方を理解する必要があるため、分かりやすく説明します。
では、テーブルを作りましょう
use tempdb GO
create table scanseek (id int , name varchar(50) default ('some random names') )
create clustered index IX_ID_scanseek on scanseek(ID)
declare @i int
SET @i = 0
while (@i <5000)
begin
insert into scanseek
select @i, 'Name' + convert( varchar(5) ,@i)
set @i =@i+1
END
インデックスシークとは、SQLサーバーが b-ツリー の構造から、一致するレコードを直接探すことができます。
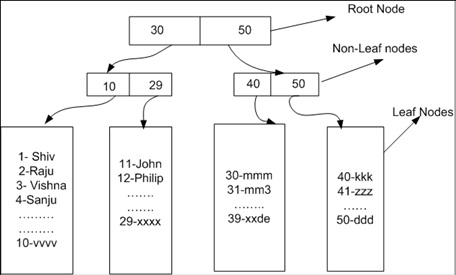
テーブルのルートとリーフノードは、以下のDMVで確認することができます。
-- check index level
SELECT
index_level
,record_count
,page_count
,avg_record_size_in_bytes
FROM sys.dm_db_index_physical_stats(DB_ID('tempdb'),OBJECT_ID('scanseek'),NULL,NULL,'DETAILED')
GO
ここで、カラム "ID"にクラスタ化インデックスを作成します。
いくつかの直接一致するレコードを探すことができます
select * from scanseek where id =340
そして実行計画を見てください

クエリで直接行を要求したため、クラスタ化インデックス SEEK を取得しました。
クラスター化インデックススキャン。
Sql サーバーがクラスタ化インデックス内の行を上から下へ読み取るとき。
例えば、非キーカラムのデータを検索する場合。このテーブルでは、NAMEは非キーカラムなので、NAMEカラムのデータを検索すると、次のようになります。
clustered index scan
なぜなら、すべての行はクラスタ化インデックスのリーフレベルにあるからです。
例
select * from scanseek where name = 'Name340'

注意:この回答は理解を深めるために短くまとめました。もし何か質問や提案があれば、以下にコメントしてください。
関連
-
[解決済み】単一のクエリで加重平均を計算する
-
[解決済み] SQL ServerでSELECTからUPDATEする方法とは?
-
[解決済み] SQL Server で複数行のテキストを 1 つのテキスト文字列に連結する方法
-
[解決済み] SQL Server テーブルにカラムが存在するかどうかを確認する方法は?
-
[解決済み] SQL Server の DateTime データ型から日付だけを返す方法
-
[解決済み] SQL ServerにおけるLEFT JOINとLEFT OUTER JOINの比較
-
[解決済み] SQL Server - 挿入された行のIDを取得するための最良の方法は?
-
[解決済み] クラスター化インデックスと非クラスター化インデックスの実際の意味は何ですか?
-
[解決済み】SQL Serverで既存のテーブルにデフォルト値を持つカラムを追加する
-
[解決済み] SQL ServerでINNER JOINを使用して削除するにはどうすればよいですか?
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み】オペランド型の衝突:intはdateと互換性がない + INSERT文はFOREIGN KEY制約と衝突した
-
[解決済み] 3を挿入すると「ORA-01438: この列で許容される指定精度より大きい値」と表示される。
-
[解決済み】Teradata - 計算中に数値のオーバーフローが発生しました。
-
[解決済み】一括読み込みデータ変換エラー(指定されたコードページに対して型の不一致または無効な文字)1行目4列目(年)について)
-
[解決済み】SQL ServerでIdentityカラムを更新する方法は?
-
[解決済み] SQL Server - 'RETURN'付近の、条件が想定されるコンテキストで指定された、非ブール型の式。
-
[解決済み] Varchar は Sum 演算子では無効です。
-
[解決済み] ORA-00920: 無効な関係演算子
-
[解決済み] varchar 値の変換で int カラムがオーバーフローしました。
-
[解決済み] 集計を行わずに行から列へピボット移動する