Spark SQL 2.4.8 データフレームを操作するための2つの方法
I. テストデータ
7369,SMITH,CLERK,7902,1980/12/17,800,20
7499,allen,salesman,7698,1981/2/20,1600,300,30
7521,ward,salesman,7698,1981/2/22,1250,500,30
7566,JONES,MANAGER,7839,1981/4/2,2975,20
7654,martin,salesman,7698,1981/9/28,1250,1400,30
7698,BLAKE,MANAGER,7839,1981/5/1,2850,30
7782,CLARK,MANAGER,7839,1981/6/9,2450,10
7788,SCOTT,ANALYST,7566,1987/4/19,3000,20
7839,KING,PRESIDENT,1981/11/17,5000,10
7844,TURNER,SALESMAN,7698,1981/9/8,1500,0,30
7876,ADAMS,CLERK,7788,1987/5/23,1100,20
7900,james,clerk,7698,1981/12/3,9500,30
7902,FORD,ANALYST,7566,1981/12/3,3000,20
7934,MILLER,CLERK,7782,1982/1/23,1300,10
II. データフレームの作成
方法1.DSL操作
- {を使用します。
SparkContextとSparkSessionのオブジェクトのインスタンス化
{を使用します。
データの構造情報を定義するStructType型を使ってスキーマを構築する。
{を使用します。
SparkContextオブジェクトを通してファイルを読み込み、RDDを生成する。
{を使用します。
RDD[String]をRDD[Row]に変換する。
{を使用します。
SparkSessionオブジェクトからdataframeを作成する
{を使用します。
コード全体は以下の通りです。
package com.scala.demo.sql
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.types.{DataType, DataTypes, StructField, StructType}
object Demo01 {
def main(args: Array[String]): Unit = {
// 1. Create SparkContext and SparkSession objects
val sc = new SparkContext(new SparkConf().setAppName("Demo01").setMaster("local[2]"))
val sparkSession = SparkSession.builder().getOrCreate()
// 2. Use StructType to define Schema
val mySchema = StructType(List(
StructField("empno", DataTypes.IntegerType, false),
StructField("ename", DataTypes.StringType, false),
StructField("job", DataTypes.StringType, false),
StructField("mgr", DataTypes.StringType, false),
StructField("hiredate", DataTypes.StringType, false),
StructField("sal", DataTypes.IntegerType, false),
StructField("comm", DataTypes.StringType, false),
StructField("deptno", DataTypes.IntegerType, false)
))
// 3. Read the data
val empRDD = sc.textFile("file:///D:\\TestDatas\\\emp.csv")
// 4. Map it to a ROW object
val rowRDD = empRDD.map(line => {
val strings = line.split(",")
Row(strings(0).toInt, strings(1), strings(2), strings(3), strings(4), strings(5).toInt, strings(6), strings(7).toInt)
})
// 5. Create a DataFrame
val dataFrame = sparkSession.createDataFrame(rowRDD, mySchema)
// 6. Display the content DSL
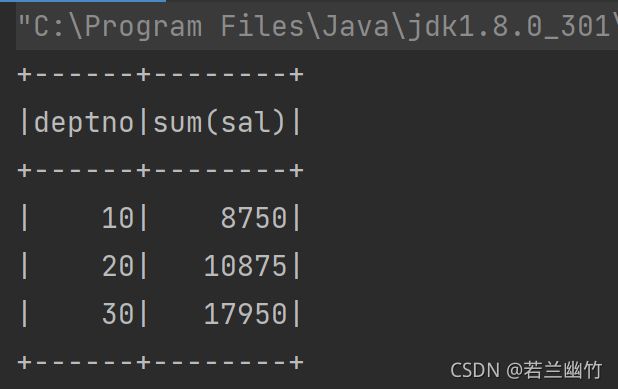
dataFrame.groupBy("deptno").sum("sal").as("result").sort("sum(sal)").show()
}
}
結果は次のようになります。
方法2:SQL操作
- SparkContextとSparkSessionのオブジェクトのインスタンス化
- データの構造情報を定義するケースクラス Emp sample クラスの作成 {を使用します。 SparkContextオブジェクトを通してファイルを読み込み、RDD[String]を生成します。
- RDD[String]をRDD[Emp]に変換する。 {を使用します。 スパーク暗黙変換関数を導入する(必須)
- RDD[Emp]をDataFrameに変換する {を使用します。 DataFrameをビューやテンポラリテーブルとして登録する {を使用します。 SparkSessionオブジェクトのsql関数を呼び出してsql文を記述する {を使用します。 リソースを停止する
- 具体的なコードは以下の通りです。
package com.scala.demo.sql
import org.apache.spark.rdd.
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.types.{DataType, DataTypes, StructField, StructType}
// 0. data analysis
// 7499,allen,salesman,7698,1981/2/20,1600,300,30
// 1. Define the Emp sample class
case class Emp(empNo:Int,empName:String,job:String,mgr:String,hiredate:String,sal:Int,comm:String,deptNo:Int)
object Demo02 {
def main(args: Array[String]): Unit = {
// 2. Read the data and map it to a Row object
val sc = new SparkContext(new SparkConf().setMaster("local[2]").setAppName("Demo02"))
val mapRdd = sc.textFile("file:///D:\\TestDatas\\emp.csv")
.map(_.split(","))
val rowRDD:RDD[Emp] = mapRdd.map(line => Emp(line(0).toInt, line(1), line(2), line(3), line(4), line(5).toInt, line(6), line(7).toInt))
// 3. Create the dataframe
val spark = SparkSession.builder().getOrCreate()
// Introduce the spark implicit conversion function
import spark.implicits._
// Convert the RDD to a Dataframe
val dataFrame = rowRDD.toDF
// 4.2 sql statement operations
// 1. Register the dataframe as a temporary table
dataFrame.createOrReplaceTempView("emp")
// 2. write sql statements to perform the operation
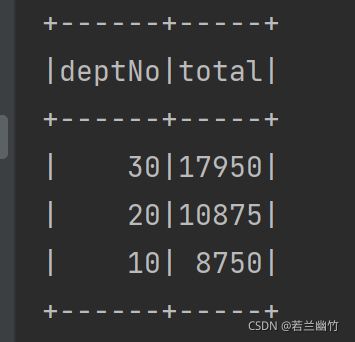
spark.sql("select deptNo,sum(sal) as total from emp group by deptNo order by total desc").show()
// Close the resource
spark.stop()
sc.stop()
}
}
結果は次のようになります。
今回はSpark SQL 2.4.8のDataframeの2つの操作方法について紹介しましたが、より関連するSpark SQL操作Dataframeの内容はBinaryDevelopの過去の記事を検索するか、以下の関連記事を引き続き閲覧してください。
関連
-
DataGrip Formatting SQLの実装(カスタムSqlフォーマット)
-
SQLServerクリーンアップログファイルのメソッド事例詳細
-
SQL Server一括挿入データ事例詳細
-
SQLの書き方--行ごとの比較
-
NavicatはSQL Serverのデータに接続します。エラー08001に対する完璧な解決策 - Named Pipeline Provider
-
日付で年齢を判定するSQLサンプルコード 関数
-
SQL Server のフィルタードインデックスによるクエリ文の改善に関するパフォーマンス分析
-
sql serverで最初の1000行のデータを削除する方法の例
-
データベース毎日練習問題、毎日少しづつ進歩(1)
-
データベース毎日練習問題、毎日少しづつ進歩(2)
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
SQL SERVERのストアドプロシージャを使用した履歴データの移行について
-
SQL Server2017では、IPをサーバー名としてサーバーに接続します。
-
SQLSERVER 変数文字列を用いたスプライシング ケース詳細
-
MySQLスレーブ遅延1列外部キーチェックとセルフインクリメントロック
-
Filestreamの簡単な使い方まとめ
-
SqlServerデータベースリモート接続ケースチュートリアル
-
SQL Serverでの判定文(IF ELSE/CASE WHEN)の使用例
-
SQLServerのエラーです。15404, unable to get information about Windows NT group/user WIN-8IVSNAQS8T7Administrator
-
SQL クエリ結果カラムのカンマ区切り文字列へのステッチング法
-
SQL SERVERオープンCDC実践講座詳細