Roc曲線とカットオフ点 パイソン
2023-10-08 20:18:05
質問
ロジスティック回帰モデルを実行し、ロジット値の予測を行いました。これを用いてROC曲線上の点を求めました。
from sklearn import metrics
fpr, tpr, thresholds = metrics.roc_curve(Y_test,p)
私は知っている
metrics.roc_auc_score
はROC曲線の下での面積を与えます。最適なカットオフポイント(しきい値)を見つけるコマンドを教えてください。
どのように解決するのですか?
次のような方法があります。
を使って
epi
パッケージで
しかし、私はPythonで同様のパッケージや例を見つけることができませんでした。
最適なカットオフポイントは、「真陽性率」が 高い で、「偽陽性率」が 低い . このロジックに基づき、最適な閾値を見つけるために、以下の例を引っ張ってきました。
Pythonのコードです。
import pandas as pd
import statsmodels.api as sm
import pylab as pl
import numpy as np
from sklearn.metrics import roc_curve, auc
# read the data in
df = pd.read_csv("http://www.ats.ucla.edu/stat/data/binary.csv")
# rename the 'rank' column because there is also a DataFrame method called 'rank'
df.columns = ["admit", "gre", "gpa", "prestige"]
# dummify rank
dummy_ranks = pd.get_dummies(df['prestige'], prefix='prestige')
# create a clean data frame for the regression
cols_to_keep = ['admit', 'gre', 'gpa']
data = df[cols_to_keep].join(dummy_ranks.iloc[:, 'prestige_2':])
# manually add the intercept
data['intercept'] = 1.0
train_cols = data.columns[1:]
# fit the model
result = sm.Logit(data['admit'], data[train_cols]).fit()
print result.summary()
# Add prediction to dataframe
data['pred'] = result.predict(data[train_cols])
fpr, tpr, thresholds =roc_curve(data['admit'], data['pred'])
roc_auc = auc(fpr, tpr)
print("Area under the ROC curve : %f" % roc_auc)
####################################
# The optimal cut off would be where tpr is high and fpr is low
# tpr - (1-fpr) is zero or near to zero is the optimal cut off point
####################################
i = np.arange(len(tpr)) # index for df
roc = pd.DataFrame({'fpr' : pd.Series(fpr, index=i),'tpr' : pd.Series(tpr, index = i), '1-fpr' : pd.Series(1-fpr, index = i), 'tf' : pd.Series(tpr - (1-fpr), index = i), 'thresholds' : pd.Series(thresholds, index = i)})
roc.iloc[(roc.tf-0).abs().argsort()[:1]]
# Plot tpr vs 1-fpr
fig, ax = pl.subplots()
pl.plot(roc['tpr'])
pl.plot(roc['1-fpr'], color = 'red')
pl.xlabel('1-False Positive Rate')
pl.ylabel('True Positive Rate')
pl.title('Receiver operating characteristic')
ax.set_xticklabels([])
最適なカットオフポイントは0.317628で、これより上は1でなければ0とラベル付けできます。出力/チャートから、TPRが1-FPRを越えているところではTPRは63%、FPRは36%、TPR-(1-FPR)は現在の例では0に最も近いことがわかります。
出力します。
1-fpr fpr tf thresholds tpr
171 0.637363 0.362637 0.000433 0.317628 0.637795
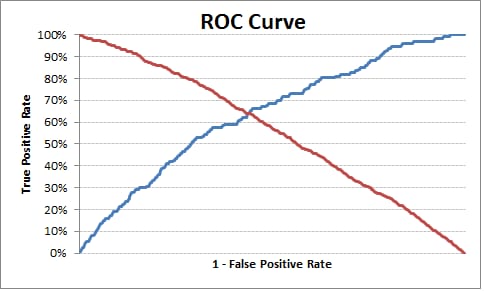
これが役に立つことを願っています。
編集
単純化し、再利用性を高めるために、最適な確率のカットオフ点を求める関数を作りました。
Pythonのコードです。
def Find_Optimal_Cutoff(target, predicted):
""" Find the optimal probability cutoff point for a classification model related to event rate
Parameters
----------
target : Matrix with dependent or target data, where rows are observations
predicted : Matrix with predicted data, where rows are observations
Returns
-------
list type, with optimal cutoff value
"""
fpr, tpr, threshold = roc_curve(target, predicted)
i = np.arange(len(tpr))
roc = pd.DataFrame({'tf' : pd.Series(tpr-(1-fpr), index=i), 'threshold' : pd.Series(threshold, index=i)})
roc_t = roc.iloc[(roc.tf-0).abs().argsort()[:1]]
return list(roc_t['threshold'])
# Add prediction probability to dataframe
data['pred_proba'] = result.predict(data[train_cols])
# Find optimal probability threshold
threshold = Find_Optimal_Cutoff(data['admit'], data['pred_proba'])
print threshold
# [0.31762762459360921]
# Find prediction to the dataframe applying threshold
data['pred'] = data['pred_proba'].map(lambda x: 1 if x > threshold else 0)
# Print confusion Matrix
from sklearn.metrics import confusion_matrix
confusion_matrix(data['admit'], data['pred'])
# array([[175, 98],
# [ 46, 81]])
関連
-
[解決済み] django.db.migrations.exceptions.InconsistentMigrationHistory
-
[解決済み] dict を txt ファイルに書き、それを読み取る?
-
[解決済み] DataFrameに日付間の日数カラムを追加する pandas
-
[解決済み] ファブリック経由でデプロイユーザとしてvirtualenvを有効化する
-
[解決済み] あるオブジェクトが数であるかどうかを確認する、最もパイソン的な方法は何でしょうか?
-
[解決済み] Jupyter (IPython)ノートブックのセッションをpickleして保存する方法
-
[解決済み] djangoフレームワークでフォームフィールドから値を取得するには?
-
[解決済み] PySparkでデータフレームのカラムをString型からDouble型に変更する方法は?
-
[解決済み] pycharmがタブをスペースに自動変換する
-
[解決済み] Pythonの文字列書式をリストで使う
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み] PythonでファイルのMD5チェックサムを計算するには?重複
-
[解決済み] PythonでSVGからPNGに変換する
-
[解決済み] Django のテストデータベースをメモリ上だけで動作させるには?
-
[解決済み] dict を txt ファイルに書き、それを読み取る?
-
[解決済み] データフレームをソートした後にインデックスを更新する
-
[解決済み] ファブリック経由でデプロイユーザとしてvirtualenvを有効化する
-
[解決済み] python-requests モジュールからのすべてのリクエストをログに記録します。
-
[解決済み] subprocess.run()の出力を抑制またはキャプチャするには?
-
[解決済み] Pythonで、ウェブサイトが404か200かを確認するためにurllibをどのように使用しますか?
-
[解決済み] 単純な文字列からtimedeltaオブジェクトを作成する方法