pythonセルフテスト100問
Pythonの仕事を探しているなら、面接ではおそらくPython関連の質問をされるでしょう。
この記事では、Web資料の収集を通じて、100のpython面接の質問と回答をリストアップしています。必要に応じて読み、テストすることができます。
パイソン基礎
Q1.Pythonとは何ですか?
Pythonは、オブジェクト指向、対話型、インタプリタ型のコンピュータ・プログラミング言語です。Pythonは非常に読みやすく設計されており、句読点の代わりに英語のキーワードを使用し、他の言語よりもシンプルな構文構造を持っています。
Q2.
1) pythonはインタプリタ型言語なので、pythonを使用する際にコンパイルする必要はない
2) 変数と類似の変数を、変数の型を繰り返すことなく宣言できること。
3) Pythonは、クラスの定義だけでなく、組み合わせや継承も可能なので、オブジェクト指向プログラミングに適しています。
4) 関数は変数に代入したり、他の関数から返したり、関数に渡したりすることができ、クラスは第一級のオブジェクトである。
5) Webアプリケーション、自動化、科学的モデリング、ビッグデータアプリケーションなど、多くのドメインで使用されている。
Q3. Pythonでサポートされているデータ型にはどのようなものがありますか?
Pythonは5つのデータ型に対応しています。
1) 数値 - 数値を保持するためのもの。
a=7.0
2) 文字列 - 文字列は文字の並びであり、一重引用符または二重引用符で囲んで宣言します。
title="Data123"
3) リスト - リストは順序付けられた値の集まりで、角括弧でリストを宣言します。
colors=['red','green','blue'] とする。
タイプ(色)
<class 'list'>
4) タプル - タプルはリストと同様に、順序付けられた値のコレクションです。違いは、タプルは不変であり、タプル内の値を変更することはできないということです。
(1,2,3,abc)
5) 辞書 - 辞書は、リスト以外にPythonで最も柔軟な組み込みデータ構造タイプです。
リストは順序付けられたオブジェクトの組み合わせであり、辞書は順序付けされていないオブジェクトのコレクションです。
この2つの違いは、辞書の要素はオフセットではなくキーでアクセスされることです。
辞書は "{ }" で識別されます。辞書は、インデックス(キー)とそれに対応する値(値)から構成されています。
dict = {}です。
dict['one'] = 'これは1つです'
dict[2] = 'これは2' です。
tinydict = {'name':'john','code':5762,'dept':'sales'}.
print(dict['one']) # キー'one'の値を出力する。
print(dict[2]) # キー2の値を出力する。
print(tinydict) # 完全な辞書を出力する。
print(tinydict.keys()) # すべてのキーを出力する
print(tinydict.values()) # 全ての値を出力する
Q4. リストとタプルの違いは何ですか?
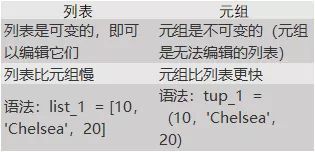
Q5. Pythonのモジュールとは何ですか?
モジュールはPythonスクリプトで、通常、import文、関数、クラス、変数定義、Python実行可能コードを拡張子".py"でファイル内に含んでいます。
Q6.Pythonのインタプリタにはどのような種類があり、どのような特徴がありますか?
CPythonです。このインタプリタはC言語で開発されているため、CPythonと呼ばれています。指定された行の下でpythonを実行するとCPythonインタプリタが起動し、CPythonは最も広く使われているPythonインタプリタです。
IPython IPythonはCPythonをベースにした対話型インタプリタで、つまり、IPythonは対話の方法が強化されているだけです。
PyPy PyPyも実行速度を重視したPythonインタプリタです。PyPyはJIT技術を使ってPythonの世代を動的にコンパイルするため、Pythonコードの実行速度を大幅に向上させることができます。
Jython Jythonは、Javaプラットフォーム上で動作するPythonインタプリタであり、Pythonコードを直接Javaバイトコードにコンパイルして実行することが可能です。
IronPython。IronPythonはJythonに似ていますが、Microsoft .Netプラットフォームで動作するPythonインタプリタであり、Pythonのコードを直接.Netにコンパイルします。
Q7. Pythonのスライシングとは何ですか?
Pythonはリスト、文字、プリミティブなどのシーケンスにマッチする順序付きシーケンスのスライスをサポートしています。
Pythonのスライスの形式。[開始 : 終了 : ステップ] です。
Start: 開始インデックス、0から始まり、-1は終了を意味する; End: 終了インデックス; Step: ステップの長さ
end-start=positive, left-to-right, =negative, reverse。
注:スライスされた結果は終了インデックスを含まない、つまり最後のビットを含まない、-1が最後の位置インデックスを表す
str1 = 'abcdefghijklmnopqrstuvwxyz' です。
str1[2:6]の場合
'cdef'
Q8. Pythonの%Sとは何ですか?
Pythonは値を文字列としてフォーマットすることをサポートしています。これには非常に複雑な式を含めることができますが、最も基本的な使い方は、値を%sプレースホルダの文字列に挿入することです。
名前 = raw_input("who are you? ")
print "こんにちは %s" % (名前,)
Q9. Pythonプログラミングにおける関数とは何ですか?
関数は、コードのブロックを表すオブジェクトであり、再利用可能なエンティティです。
プログラムにモジュール性をもたらし、より高度なコードの再利用性を提供する。
Pythonは、print()などの多くの組み込み関数と、ユーザー定義関数を作成する機能を提供しています。
Q10. Pythonの基本的な関数の種類はいくつありますか?
Pythonには、組み込みとユーザー定義の2種類の基本的な関数があります。
組み込み関数は、print()、dir()、len()、abs()などのPythonの言語の一部です。
Q11. Pythonで関数を書くにはどうしたらいいのでしょうか?
Pythonの関数は、以下の方法で作成することができます。
1)defで関数を定義し、関数名をリンクさせる。
2) 引数を渡し、括弧で囲み、コロンで終端を示す。
3) 実行に必要な Python 文を追加する。
Q12. ディープコピーとシャローコピーの違いは何ですか?
ディープコピーとは、あるオブジェクトを別のオブジェクトにコピーすることです。つまり、あるオブジェクトのコピーに変更を加えても、元のオブジェクトには影響がありません。
Pythonでは、関数deepcopy()を使って、モジュールcopyをインポートして、次のようにディープコピーを行います。
インポートコピー
b=copy.deepcopy(a)
一方、シャローコピーは、あるオブジェクトの参照を別のオブジェクトにコピーするため、コピーで変更しても元のオブジェクトに影響する。シャローコピーを行うには、下図のように関数function()を使用します。
b=copy.copy(a)
Q13. Pythonにおける関数呼び出し、呼び出し可能なオブジェクトとは何ですか?
Pythonの関数は、呼び出し可能なオブジェクトとみなされます。関数は、いくつかの引数を許容し、タプルの形で値または複数の値を返すことができます。関数に加えて、Pythonにはクラスや同じクラスに収まるクラスのインスタンスなど、他の構成要素もあります。
Q14. PythonのPassとContinueはどう違うのですか?
continue文は、次の反復からループを再開させます。pass文は、何もしないことを指示し、残りのコードは通常通り実行されます。
Q15. 環境変数PYTHONPATHは何のためにあるのですか?
PYTHONPATH - PATHのように動作します。この変数は、インポートされたプログラムのモジュールファイルがどこにあるかをPythonインタープリタに知らせます。PythonソースライブラリディレクトリとPythonソースコードを含むディレクトリを含む必要があります。
Q16. pythonstartup, pythoncaseok, pythonhome, pythonstartup 環境変数の目的は何ですか?
PYTHONSTARTUP - Pythonのソースコードを含む初期化ファイルへのパスが含まれています。これはインタープリターが起動するたびに実行されます。Unix では .pythonrc.py という名前で、ユーティリティをロードしたり PYTHONPATH を変更するためのコマンドを含んでいます。
PYTHONCASEOK - Windows で、import 文の中で大文字と小文字の区別なく一致するものを探すよう Python に指示するために使用されます。この変数を有効にするには、任意の値を設定します。
PYTHONHOME - これもモジュール検索パスです。モジュール・ライブラリの切り替えを容易にするため、通常は PYTHONSTARTUP または PYTHONPATH ディレクトリに埋め込まれています。
Q17. Pythonでマルチスレッドを実装するにはどうしたらよいですか?
Pythonは、主にthreadとthreadingという2つのモジュールによってマルチスレッドのサポートを実装しています。
python の thread モジュールはより低レベルのモジュールで、python の threading モジュールは thread をより簡単に使用するためのラッピングモジュールです。ただし、python(cpython)はGILの関係でスレッドを使用してCPUリソースをフル活用することができないので、マルチコアCPUの演算能力をフル活用したい場合はマルチプロセッシングモジュール(Windowsでは多くの問題がある)を使用する必要があります。
python 3.x では、python 2.x の機能的な thread モジュールの start_new_thread() 関数から離れました。python 3.x では threading モジュールを介して新しいスレッドを作成する方法が 2 つあります。
1) threading.Thread(Target=executable Method)経由 - つまり、Threadオブジェクトに実行可能なメソッド(またはオブジェクト)を渡します。
2) threading.Threadを継承してサブクラスを定義し、run()メソッドをオーバーライドする。2番目のメソッドでは、オーバーライドしなければならないメソッドはrun()だけです。
Q18. pythonで三項演算子を使うにはどうしたらいいですか?
三項演算子は、条件文を表示するために使用される演算子です。これは真か偽のどちらかの値を含み、それに対して文を評価する必要があります。
三項演算子は、次のように与えられます。
[on_true] if [expression] else [on_false] x, y = 25,50big =x if x <y else y
式はx <y else yと同じように計算され、この場合、x <y が真なら big = x、不正なら big = y が結果として返される。
Q19. Tkinterとは何ですか?
TKinterはGUIを作成するためのPythonのライブラリとして知られています。TKinterはボタン、ラベル、テキストボックスなどの様々なGUIツールやウィンドウコンポーネントをサポートしています。これらのツールやコンポーネントはそれぞれ異なる特性を持っており、例えば、GUIを作成するために使用することができます。これらのツールや成果物は、寸法、色、フォントなど、異なるプロパティを持っています。
問20)Pythonの継承について
継承は、あるクラスが他のクラスのすべてのメンバー(プロパティやメソッドなど)を取得することを可能にします。継承はコードの再利用を可能にし、アプリケーションの作成と保守を容易にします。
Pythonがサポートするさまざまなタイプの継承。
1) 単一継承 - 派生クラスは単一スーパークラスのメンバを取得します。
2) 多段階継承 - 派生クラス d1 は基底クラス base1 から、d2 は基底クラス base2 から継承される。
3) 階層的継承 - ベースクラスから任意の数のサブクラスを継承することができる。
4) 多重継承 - 派生クラスは複数のベースクラスから継承される。
Q21. .pycファイルと.pyファイルの違いについて教えてください。
どちらのファイルもバイトコードを保持していますが、.pycファイルはプラットフォームに依存しないバイトコードを持つPythonファイルのコンパイルバージョンなので、.pyc形式のファイルをサポートしているどのプラットフォームでも実行できます。
Q22. 酸洗除去とは何ですか?
Pickleモジュールは、任意のPythonオブジェクトを取り込んで文字列表現に変換し、dump関数を使ってファイルにダンプする処理をpicklingと呼びます。保存した文字列表現から元のPythonオブジェクトを取り出す処理を unpicklingと呼びます。
Q23. Pythonでファイルに関連付けられているモジュールの名前を言ってください。
Pythonには、ファイルシステム上のテキストファイルやバイナリファイルを操作するために使用できるライブラリ/モジュールの関数が用意されています。これらを使って、ファイルの作成、内容の更新、コピーや削除などの操作を行います。これらのライブラリは、os、os.path、およびshutilです。
Q24. with文の使い方を説明しなさい。
Pythonでは、通常、ファイルを開き、ファイルに存在するデータを処理し、close()メソッドを呼び出さずにファイルを閉じるために"with"文が使用されています。
Q25. Pythonがサポートしているファイル操作モードをすべて説明しなさい。
Pythonでは、ファイルを開くために3つのメソッドを使用することができます。それらは
1) フラグ "r", "w", "rw", "a", 読み取り専用モード、書き込み専用モード、読み取り/書き込みモード、追加モードの指定によるものです。
2) "t"オプションを指定することで、上記のどのモードでもテキストファイルを開くことができるようになります。
3) "r", "w", "rw" and "a" で、前のモードは "rt", "wt", "rwt", "at" になります。バイナリファイルは "b" と "r", "w", "rw", "a" のオプションを指定すれば、上記のどのモードでも開くことが可能です。"と"a"ですから、先行するモードは"rb"、"wb"、"rwb"、"ab"となるわけですね。
Q26. Pythonは何種類の配列をサポートしていますか?
Pythonは7つのシーケンスタイプをサポートしています。それらは str, list, tuple, unicode, byte array, xrange, buffer です。xrange は python 3.5.X で非推奨です。
Q27. Pythonでパターンマッチを行うにはどうしたらよいですか?
正規表現 (RE) は、与えられた文字列の特定の "part" にマッチする式を指定することができます。例えば、1つの文字や数字、電話番号や電子メールアドレスなどにマッチする正規表現を定義することができます。Pythonの"re"モジュールは正規表現のパターンを提供し、Python 2.5以降で導入されました。"re"モジュールは、テキスト文字列を検索したり、テキスト文字列を置換したり、定義されたパターンに基づいて分割するためのメソッドを提供します。
Q28. Pythonはメモリ管理をどのように行っているのですか?
Pythonのメモリは、Pythonのプライベートヒープ空間によって管理されています。すべてのPythonオブジェクトとデータ構造は、プライベートヒープに配置されます。プログラマはこのプライベートヒープにアクセスすることはできません。インタープリタがこれを処理します。Pythonオブジェクトに対するPythonヒープ空間の割り当ては、Pythonメモリマネージャによって行われます。Pythonはまた、すべての未使用メモリを回収して解放し、ヒープスペースで使用できるようにするガベージコレクタを内蔵しています。
Q29. テキストファイルの内容を逆順に表示するにはどうしたらいいですか?
1) 与えられたファイルをリストに変換する
2) reverse()を使って、リストを反転させる (例)
for reverse in reverse(list(open("file-name", "r"))).
print()
Q30. 負の指数とは
Pythonの配列は正のインデックスと負のインデックスの両方を持つことができます。正のインデックスの場合、0が最初のインデックス、1が2番目のインデックス、そして以下同様です。負のインデックスでは、( - 1)が最後のインデックス、( - 2)が最後から2番目のインデックス、といった具合になります。
Q31. Python の "re" モジュールの split()、sub()、subn() メソッドについて説明しなさい。
Pythonの"re"モジュールは、文字列を変更するための3つのメソッドを提供します。
1) split() - 正規表現パターンを使って、与えられた文字列をリストに分割します。
2) sub() - 正規表現パターンにマッチするすべての部分文字列を見つけ出し、異なる文字列に置き換えます。
3) subn() - sub() と同様で、新しい文字列と置換番号を返します。
Q32. Python Flaskにおけるデータベース接続について説明してください。
Flaskはデータベース駆動型アプリケーション(RDBS)をサポートします。Flaskは3つの方法でデータベースへのリクエストを可能にします。
1) before_request():リクエストの前に呼び、引数を渡さない。
2) after_request():リクエストの後に呼び出され、クライアントに送信されるレスポンスを渡します。
3) teardown_request():例外が発生し、応答が保証されない場合に呼び出される。レスポンスが構築された後に呼び出される。これらはリクエストを変更することはできず、その値は無視されます。
Q33. rangeとxrangeの違いは何ですか?
xrangeとrangeは、整数のリストを生成するという点で、機能的にはほとんど同じです。唯一の違いは、range は Python のリストオブジェクトを返し、xrange は xrange オブジェクトを返すことです。
Q34. Pythonの"call by value"とは何ですか?
call-by-valueでは、関数内で対応する変数の引数に式や値が束縛されていても、Pythonはその変数を関数レベルのスコープでローカルとして扱います。その変数に加えられたいかなる変更もローカルのままであり、その関数の外には反映されません。
Q35. Pythonのquot;call by reference"とは何ですか?
参考までに、quot;参照呼び出しとquot;参照渡しは同じように使うことができます。参照渡しの場合、引数は単に関数のコピーではなく、関数への暗黙の参照として使用することができます。この場合、引数への変更は呼び出し側からも見えるようになります。
この方式は、ローカルコピーを作成する必要性がなくなるため、時間的・空間的な効率も上がるという利点がある。逆にデメリットは、関数呼び出し中に誤って変数が変更されてしまう可能性があることです。
Q36. LambdaとDefの主な違いは何ですか?
def は関数を生成し、後でそれを呼び出すための名前を指定します。lambda は関数オブジェクトを形成して戻ります。lambda はリストと辞書での使用をサポートしています。
Q37. ascii、unicode、utf-8、gbkの違いは何ですか?
ASCII:1バイトのエンコードを使用しているため、その範囲は基本的にアルファベットと数字、一部の特殊記号のみで、文字数は256文字と少ないです。
ユニコード:世界中のすべてのバイトを表現できる。
GBK:漢字の符号化にのみ使用され、GBKは「拡張漢字内部符号」と呼ばれ、2バイトの符号化を使用します。
UTF-8:Unicodeの可変長文字コードで、ユニコードとも呼ばれます。
Q38. Pythonが終了するときに、すべてのメモリがアンアロケートされないのはなぜか?
Python が終了するとき、特に他のオブジェクトへの循環参照を持つ Python モジュールや、グローバル名前空間から参照されるオブジェクトは、常に割り当て解除や解放が行われるとは限りません。python はそれ自身の効率的なクリーンアップメカニズムを持っているので、メモリのこれらの部分は、終了時に他のすべてのオブジェクトをアンアロケート/破壊しようとし、保持することができません。
Q 39. Python の引数渡しの仕組みについて説明します。
Python は関数に引数を渡すために参照渡しを使用します。関数内で引数を変更すると、関数呼び出しに影響します。これはPythonのデフォルトの操作です。しかし、文字列、数値、タプルなどのリテラルな引数を渡す場合は、値で渡され、これはそれらが不変であるためです。
Q40. モンキーパッチとは何ですか?
実行時にクラスまたはモジュールを動的に修正すること。
クラスA
def func(self):
print("こんにちは")
def monkey(self):
プリント "こんにちは、モンキー"。
m.A.func = 猿
a = m.A()
a.func()
こんにちは、モンキー
Q41. ビッグデータのためのファイル読み込み
1)ジェネレータgeneratorを使用する
2) 反復的な探索のためのイテレータ: for line in file
Q42.findとgrep
grepコマンドは強力なテキスト検索ツールです。grepは正規表現が可能な内容文字列を検索し、テキストファイルのパターン検索を可能にします。パターンが見つかった場合、grep はそのパターンを含むすべての行を表示します。find は、特定のディレクトリに一致するファイルを検索するためによく使用されますが、特定のユーザーが所有するファイルを検索するために使用することも可能です。
Q43. オンラインサービスの場合、様々な理由でハングアップする可能性がありますが?
スーパーバイザは、Linuxのバックグラウンドプロセスを管理するための優れたツールです。
ファイルを変更するたびに、service supervisord restart on linux を実行する。
Q44.pythonの動作を効率的にする方法
ジェネレータの使用、重要なコードには外部関数パッケージ(Cython、pylnlne、pypy、pyrex)の使用、ループの最適化 - ループ内の変数のプロパティへのアクセスを避けるようにする。
Q45. Linuxの共通コマンド
ls、help、cd、more、clear、mkdir、pwd、rm、grep、find、mv、su、date
Q46. Pythonのyieldの使い方
yieldは、関数が最後に返したときに関数本体のどこにいたかを記憶するための、単純なジェネレータです。ジェネレータの2回目(またはn回目)の呼び出しは、その関数にジャンプします(またはn回目の呼び出しはその関数にジャンプします)。
Q47. 配列、チェーン、キュー、スタックの違いについて説明しなさい。
アレイとチェーンは、データの保存方法の概念です。キューとスタックは、データのアクセス方法を表す概念で、キューは先入れ先出し、スタックは後入れ先出しで、キューとスタックは配列とチェーンで実装できます。
Q48. 知っているURLアドレスを使って、画像をローカルに保存するにはどうしたらよいですか?
以下のコードを用いて、URLアドレスから画像をローカルに保存します。
urllib.requestをインポートする
urllib.request.urlretrieve("URL", "local-filename.jpg")
Q49. 任意のURLやウェブページのGoogleキャッシュの時間軸を取得するにはどうしたらよいですか?
以下のURL形式を使用してください。
http://webcache.googleusercontent.com/search?q=cache:URLGOESHERE URLGOESHERE"をキャッシュを取得したいページやサイトの正しいURLに置き換えて、時間を確認するようにしてください。
例えば http://edureka.co のGoogle Webcache時代のものであれば、以下のようなURLになります。
http://webcache.googleusercontent.com/search?q=cache:edureka.co
Q50. IMDbのトップ250ムービーのページから、映画名、年、レーティングのフィールドのみデータを削除する必要があります。
from bs4 import BeautifulSoup
インポートリクエスト
インポートシステム
url = 'http://www.imdb.com/chart/top'
レスポンス =requests.get(url)
スープ =BeautifulSoup(response.text)です。
tr =soup.findChildren("tr")
tr =iter(tr)
次(tr)
フォームムービー
タイトル =movie.find('td', {'class': 'titleColumn'} ).find('a').contents[0] (タイトル)
年 =movie.find('td', {'class': 'titleColumn'} ).find('span', {'class': 'secondaryInfo'}).contents[0] (年号を指定する場合は、'span'を指定してください。
評価 =movie.find('td', {'class': 'ratingColumn imdbRating'} ).find('strong').contents[0] (評価欄がない場合、評価欄はありません。)
行 =タイトル +' - '+年 +' '+' '+評価
print(行)
上記のコードは、IMDbのトップ250リストからデータを削除するのに役立ちます。
Q51. argsと*kwargsの使い分けについて教えてください。
関数に渡す引数の数がわからないとき、たとえばリストやタプルを渡すときは、*args を使用します。
def func(*args):
for i in args:
print(i)
func(3,2,1,4,7)
3
2
1
4
7
いくつ渡せばいいかわからないときにキーワード引数を集めるには、**kwargs を使います。
def func(**kwargs):
for i in kwargs:
print(i,kwargs[i])を実行します。
func(a=1,b=2,c=7)
a.1
b.2
c.7
Q52. Pythonでファイルを削除する方法を教えてください。
os.remove (ファイル名) または os.unlink (ファイル名) というコマンドを使用します。
Q53. C言語からPythonで書かれたモジュールにアクセスする方法を説明してください。
Pythonで書かれたモジュールにC言語からアクセスするには、以下の方法があります。
モジュール = = PyImport_ImportModule("<modulename>")
Q54. Pythonで//演算子を使うか?
2つのオペランドを割るための階差演算子で、結果は商となり、小数点の前の数字だけが表示されます。たとえば、10 // 5 = 2 や 10.0 // 5.0 = 2.0 といった具合です。
Q55. 文字列から先頭のスペースを取り除くにはどうしたらよいですか?
文字列中の先行する空白とは、文字列中の空白でない最初の文字の前に現れる空白のことです。これを文字列から取り除くには、Istrip()というメソッドを使います。
' Data123 '.lstrip()
結果
'Data123 '
最初の文字列には、先頭と末尾の文字が含まれています。Istrip()を呼び出すと先頭のスペースが削除され、末尾のスペースを削除したい場合は、rstrip()メソッドを使用できます。
'Data123 '.rstrip()
'データ123'
Q56. Pythonでフィボナッチ級数を出力するにはどうしたらよいですか?
a,b = 0, 1
while b<100:
プリント(b)
a, b = b, a+b
Q57. Pythonで文字列を整数型変数に変換するにはどうすればよいですか?
文字列が数字のみを含む場合、関数 int() を使って整数に変換することができます。
int('22')
変数の型を確認しましょう。
タイプ('22')
<class'str'>
タイプ(int('22'))
<class'int'>
Q58. Pythonで乱数を生成するにはどうしたらいいですか?
乱数を生成するには、randomモジュールから関数random()をインポートすればよい。
from random import random
ランダム()
0.013501571090371978
また、関数randint()も使えます。これは区間を2つ引数にとり、その区間内の乱数整数を返します。
from random import randint
randint(2,7)
4
Q59. 文字列の最初の文字を大文字にするにはどうしたらよいですか?
最も簡単な方法は、capitalize()メソッドを使用することです。
'daxie'.capitalize()
'ダクシー'
Q60. 文字列に含まれるすべての文字が英数字であることを確認するにはどうしたらよいですか?
この質問には、isalnum()メソッドを使用します。
'DATA123'.isalnum()
真
'DATA123!'.isalnum()です。
偽
他にも使える方法があります。
'123'.isdigit()# で数字だけの文字列かどうかをチェックします。
真
'123'.isnumeric()# ユニコード・オブジェクトの場合のみ
真
'data'.islower()# すべて小文字かどうか
真
'Data'.isupper()# すべて大文字かどうか
偽
Q61.Pythonの連結とは何ですか?
PythonのConcatenationは、2つの配列を結合することで、+演算子を使って行います。
'22' + '33'
'2233'
[1,2,3]+[4,5,6]
[1, 2,3, 4, 5, 6]
(2,3)+(4)
TypeError トレースバック (最新のコールバック)
<module> の中の <ipython-input-7-69a1660f2fc5> です。
----> 1 (2,3)+(4)
TypeError: タプルにのみ連結可能 ("int" ではありません)
(4)が整数として扱われるため、エラーで実行されます。これを修正して再実行します。
(2,3)+(4,)
(2, 3,4)
Q62. 再帰とは何ですか?
関数を呼び出す過程で、その関数自体が直接または間接的に再帰的に呼び出されます。しかし、デッドループを避けるためには、例として終了条件が必要である。
def facto(n):
if n==1: 1を返す
return n*facto(n-1)
ファクト(5)
120
Q63. 発電機とは何ですか?
ジェネレータは、反復のために一連の値を生成するもので、この点でも反復可能なオブジェクトと言えます。forループが進むにつれて次の要素を計算し、適切な条件でforループを終了させます。値を1つずつ生成する関数を定義し、それをforループで反復処理する。
def squares(n):
i=1
while(i<=n):
i**2
i+=1
for i in squares(5):
print(i)
1
4
9
16
25
Q64.イテレータとは何ですか?
イテレータとは、コレクションの要素にアクセスするための方法です。イテレータオブジェクトは、コレクションの最初の要素から、すべての要素にアクセスするまでアクセスされます。イテレータは前に進むことだけが可能で、後ろに戻ることはできません。イテレータを作成するには、inter() 関数を使用します。
odds=iter([1,2,3,4,5])
# オブジェクトを取得するたびに、next()関数を呼び出す
次のオッズ
1
次(オッズ)
2
次のオッズ
3
次ページ(オッズ)
4
次のオッズ
5
Q65. ジェネレータとイテレータの違いについて教えてください。
1) ジェネレータを使用する場合は関数を作成し、イテレータを使用する場合は組み込み関数の iter() と next() を使用します。
2) ジェネレータでは、一度に1つのオブジェクトを生成/返却するためにキーワード「yield」を使用します。
3) ジェネレータにいくつの 'yield' ステートメントがあるか、これはカスタマイズ可能です。
4) ジェネレーターは、「yield」がループを一時停止するたびに、ローカル変数の状態を保存する。一方、イテレータはローカル変数を使用せず、イテレートするためのイテレート可能なオブジェクトを必要とするだけです。
5) クラスを使って独自のイテレータを実装することは可能ですが、ジェネレータはできません。
6) ジェネレーターはより高速で、よりすっきりとしたシンプルな構文を持っています。
7) イテレータはよりメモリ効率が良い。
Q66. 関数zip()は何をしているのか?
Python初心者はこの関数に馴染みがないかもしれません。zip()はタプルに対するイテレータを返します。
リスト(zip(['a','b','c'],[1,2,3]))
[('a',1), ('b',2), ('c',3)] となります。
ここでは、zip()関数が2つのリストのデータ項目をペアにして、タプルを作成するために使用しています。
Q67. Pythonを使って、現在どのディレクトリにいるのかを調べるにはどうしたらよいでしょうか?
関数/メソッドgetcwd()を使って、モジュールosからインポートすればいいのです。
インポート os
os.getcwd()
'C:\\Users\\\37410\\\Desktop\\\code'
Q68.文字列の長さはどのように計算するのですか?
これも比較的簡単で、長さを計算したい文字列の上で関数len()を呼び出すだけです。
len('データ123')
8
Q69. 最後のオブジェクトをリストから削除するにはどうすればよいですか?
リストから最後のオブジェクトまたはobjを削除して返します。
list.pop (obj = list [-1])
Q70. Pythonで関数指向プログラミングを実装する方法をいくつか説明します。
リストを反復処理するときに便利なメソッドがあることがあります。
1) filter()
フィルタとは、条件付きロジックに基づき、ある値をフィルタリングするものです。
list(filter(lambda x: x> 5, range(8)))
[6,7]
2) map()
Map はイテラブルの各要素に関数を適用します。
list(map(lambda x: x ** 2, range(8)))
[0,1,4,9,16,25,36,49]
3) reduce()
Reduce は、単一の値に到達する前に、シーケンスの順序を反復的に減少させます。
from functools import reduce
reduce (lambda x, y: xy, [1,2,3,4,5])
-13
Q71. 数値のリストの合計を計算するPythonプログラムを作成せよ。
def list_sum(num_List): if len(num_List) == 1.
return num_List [0]
さもなければ
return num_List [0] + list_sum (num_List [1:])
print(list_sum([3,4,5,6,11]))
29
Q72. ファイルからランダムな行を読み出すPythonプログラムを書いてください。
インポートランダム
def random_line (fname).
lines = open(fname).read().splitlines()。
return random.choice(行)
print(random_line('test.txt'))を実行します。
Q73. テキストファイルの行数を数えるPythonプログラムを書いてください。
def file_lengthy (fname).
open(fname) as f.
for i, l in enumerate(f).
パス
戻り値 i + 1
print("file of lines:", file_lengthy("test.txt"))
Q74. ファイル内の大文字の数をカウントするPythonのロジックを書いてください。
インポート os
os.chdir('C:\Userslifei ㊙Desktop')
をopen('Today.txt')とし、todayとします。
count=0
for i in today.read():
if i.isupper():
count+=1
print(count)
Q75.Pythonで数値データセットのソートアルゴリズムを書きたい
Pythonでリストをソートするには、次のコードを使用します。
リスト = ["1", "4", "0", "6", "9" ]である。
list = [int(i) for i in list] です。
list.sort()
プリント(リスト)
Django関連
Q76. Djangoのアーキテクチャについて説明または解説してください。
Djangoのフレームワークは、MVCの設計に従っており、正式な名前を持っている:MVT、Mはモデルと綴られ、MVCのMと同じ機能は、データ処理を担当し、組み込みORMフレームワーク、Vはビューと綴られ、MVCのCと同じ機能は、HttpRequest、ビジネス処理、戻りHttpResponse受信、Tはテンプレートと綴られて、MVCのVと同じ機能は、戻り、テンプレートエンジンを内蔵しhtmlの構築をカプセル化する責任があります。
Q77.Django、Pyramid、Flaskの違いについて
Flaskはマイクロフレームワークであり、主に小規模でシンプルな要件のアプリケーションに使用されます。Pyramidは大規模なアプリケーション向けで、データベース、URL構造、テンプレートスタイルなど、開発者がプロジェクトに適したツールを使用できるような柔軟性を持っています。Django は Pyramid のような大規模なアプリケーションにも使うことができます。ORM も含まれています。
Q78. Djangoのアーキテクチャについて議論している
Djangoのアーキテクチャ
開発者はモデル、ビュー、テンプレートを提供し、それを Django がユーザに提供するための URL にマッピングします。
Q79. Djangoでデータベースをセットアップする方法を説明してください。
Django はデフォルトのデータベースとして SQLite を使い、データをファイルシステム上の1つのファイルとして保存します。
PostgreSQL, MySQL, Oracle, MSSQL などのデータベースサーバを持っていて、 SQLite の代わりにそれを使いたい場合は、データベースの管理ツールで Django プロジェクト用に新しいデータベースを作成してください。
いずれにせよ、(空の) データベースを設置したら、あとはそれをどう使うかを Django に伝えるだけです。これはプロジェクトの settings.py ファイルのソースです。
settings.py ファイルに以下の行を追加します。
DATABASES = {'default': {'ENGINE': 'django.db.backends.sqlite3', 'NAME': os.path.join(BASE_DIR, 'db.sqlite3')です。
Q80. DjangoでVIEWの書き方の例をあげてください。
これは、Django でビューを書くときの方法です。
from django.http import HttpResponse
インポート datetime
def Current_datetime(request):
今すぐ =datetime.datetime.now()
html ="<html><body>It is now %s</body></html>"%now
return HttpResponse(html)
現在の日付と時刻をHTML文書として返します。
Q81.Djangoのテンプレートの構成要素について言及します。
テンプレートとは、単純なテキストファイルのことです。XML、CSV、HTMLなど、テキストベースのあらゆる形式で作成することができます。テンプレートには、テンプレートが評価されたときに値に置き換えられる変数と、テンプレートのロジックを制御するタグ(%tag%)が含まれています。

Q82. Djangoフレームワークにおけるセッションの使用について説明してください。
Django は、サイト訪問者ごとにデータの保存と取得を可能にするセッションを提供します。 django は、クライアント側にセッション ID クッキーを置き、サーバ側にすべての関連データを保存することで、クッキーの送受信処理を抽象化します。
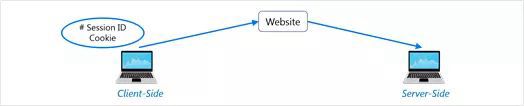
つまり、データそのものはクライアント側には保存されないんですね。セキュリティの観点からは、それで問題ないでしょう。
Q83. Djangoの継承スタイルを列挙せよ
Django では、3 つの可能な継承スタイルがあります。
抽象ベースクラス: 各子モデルで型付けされたくない情報を親クラスだけに持たせたい場合に使用します。
マルチテーブル継承:既存のモデルをサブクラス化し、各モデルが独自のデータベーステーブルを持つ必要がある場合。
プロキシモデル。モデルのフィールドを変更せずに、モデルのPythonレベルの動作だけを変更したい。
データ解析
Q84. Pythonのmap関数とは何ですか?
map関数は、第1引数として与えられた関数を、第2引数として与えられたiterableの全要素に実行します。与えられた関数が1つ以上の引数を取る場合、多くの反復が行われます。
Q85. NumPyの配列で、N個の最大値のインデックスを得るにはどうしたらよいですか?
以下のコードを用いて、NumPy配列中のN個の最大値のインデックスを得ることができます。
npとしてimportnumpy
arr = np.array([1、3、2、4、5])
print(arr.argsort()[-3:][::-1])
4 3 1
Q86.Python/NumPyでパーセンタイルを計算するにはどうしたらいいですか?
npとしてimportnumpy
a =np.array([1,2,3,4,5])です。
p =np.percentile(a, 50) #50パーセンタイル、例えば中央値を返します。
print(p)
3
Q87. Pythonのリストにおいて、NumPyの配列は(ネストされた)どのような利点がありますか?
1) Pythonのリストは効率的な汎用コンテナである。
挿入、削除、追加、結合を(かなり)効率的にサポートし、Pythonのリスト派生機能により構築と操作が容易になりました。
2)いくつかの制限がある
また、異なる型のオブジェクトを含むことができるため、Pythonは各要素の型情報を保存し、動作時に各要素に対して型ディスパッチコードを実行しなければなりません。
3) NumPy は効率的なだけでなく、利便性も高い
ベクトルや行列の演算を多く取得できるので、時には無駄な作業を省くことができます。
4) NumPyの配列はより速い
NumPy、FFT、畳み込み、高速探索、基本統計、線形代数、ヒストグラム、その他ビルトインで使用できます。
Q88. デコレータの使い方を説明してください
Pythonのデコレーターは、関数やクラスのコードを修正したり、注入したりするために使用されます。デコレータを使用すると、クラスまたは関数のメソッド呼び出しをラップして、元のコードが実行される前または後にコードの一部を実行することができます。デコレータは、パーミッションのチェック、メソッドに渡される引数の変更や追跡、特定のメソッドの呼び出しのログ取得などに使用することができます。
Q89. NumPyとSciPyの違いは何ですか?
1) 理想の世界では、NumPyは配列データ型と最も基本的な操作(インデックス付け、ソート、リシェイプ、基本的な要素関数など)だけを含んでいます。
2) すべての数値コードはSciPyに存在する。しかし、NumPy の重要な目標は互換性であり、NumPy はその前身がサポートするすべての機能を保持しようとするものである。
3) その結果、NumPy には、SciPy に属するのがより適切であるにもかかわらず、いくつかの線形代数関数が含まれている。いずれにせよ、SciPy には、他の多くの数値計算アルゴリズムと同様に、線形代数モジュールのより完全な機能版が含まれています。
4) 科学計算のために python を使っているならば、NumPy と SciPy をインストールすべきです。
Q90. NumPy / SciPyを使って3Dプロット/ビジュアライゼーションを作成するにはどうしたらよいですか?
matplotlibはmplot3dサブパッケージで基本的な3Dプロットを提供し、Mayaviは強力なVTKエンジンを使って様々な高品質の3D視覚化機能を提供します。
クローラー&スカラーフレームワーク
Q91.scrapyとscrapy-redisの違いは何ですか?また、redisデータベースを選択した理由は何ですか?
1) scrapyはPythonのクローラーフレームワークで、非常に効率的にクロールを行い、カスタマイズ性も高いですが、配布はサポートしていません。
これに対し、redisデータベースをベースとし、scrapyフレームワークの上で動作するコンポーネント群であるscrapy-redisは、Slaver側でアイテムキュー、リクエストキュー、マスター側のredisデータベースのリクエストフィンガープリントコレクションを共有し、分散ポリシーをサポートできるようにしたものです。
2) redisはマスタースレーブ同期をサポートし、データはメモリにキャッシュされるため、redisをベースにした分散クローラーは、リクエストやデータを高頻度で読み込むのに非常に効率的です。
Q92. これまでに使用したことのあるクローラーフレームワークやモジュールがあれば教えてください。
Pythonにはurllib、urllib2が付属しています。
サードパーティ:リクエスト
フレームワーク Scrapy
urllibとurllib2モジュールはどちらもURLのリクエストに関連する操作を行いますが、提供する機能は異なります。
urllib2.: urllib2.urlopen は Request オブジェクトか URL を受け取りますが (Request オブジェクトを受け取るときに URL のヘッダを設定するために使用します)、 urllib.urlopen は URL しか受け取らないのに対して、 urllib2.urlopen は URL を受け取ります。
urllibにはurlencodeがありますが、urllib2にはないので、いつもurllib, urllib2が一緒に使われることが多いです。
scrapyは、ダウンローダー、パーサー、ロギング、例外処理などがパッケージされたフレームワークで、マルチスレッドによるねじれた処理方法をベースにしており、固定された単一サイトのクロール開発には、利点がありますが、複数サイトのクロールでは100サイト、並行処理、分散処理で、柔軟性が十分ではなく、調整とブラケットに不便があります。
要求は、HTTPライブラリは、それだけでHTTP要求のために、要求を行うために使用され、それは強力なライブラリは、ダウンロード、すべて自分自身で解析し、より柔軟で、高い同時性と分散配置も非常に柔軟で、関数がより良い達成することができますです。
Q93. 一般的なmysqlのエンジンは何ですか?また、それぞれのエンジンの違いについて教えてください。
MyISAMとInnoDBの2つのエンジンは、主に次のような大きな違いがあります。
1) InnoDBはトランザクションをサポートしているが、MyISAMはサポートしていない、これは非常に重要なことである。トランザクションは非常に重要である。
一部のカラムの追加、削除、変更などでは、どのエラーでもロールバックできるレベルの処理ですが、MyISAMでは
はできません。
2) MyISAMはクエリや挿入ベースのアプリケーションに適しており、InnoDBは頻繁に修正を行うアプリケーションに適しています。
より安全なアプリケーションを提供します。
3) InnoDBは外部キーをサポートするが、MyISAMはしない。
4) MyISAM はデフォルトエンジンであり、InnoDB は指定する必要がある。
5) InnoDB は FULLTEXT タイプのインデックスをサポートしません。
6) InnoDB は、select count(*) from table, InnoDB; のように、テーブル内の行数を保存しない。
テーブル全体をスキャンして行数を計算するが、MyISAM は単に保存された行数を読み取るだけである
できます。count(*) ステートメントに where 条件が含まれている場合、MyISAM もテーブル全体をスキャンする必要があることに注意してください。
7) 自己増殖するフィールドの場合、InnoDBではそのフィールドのみのインデックスを格納する必要がありますが、MyISAMでは
テーブルでは、他のフィールドとのジョイントインデックスを作成することができます。
8) テーブル全体を空にする場合、InnoDB は行ごとに削除するため非常に遅く、MyISAM は再削除する。
テーブルを構築する。
9) InnoDB は行ロック (場合によってはテーブル全体をロック、例えば update table set a=1 where) をサポートします。
user like '%lee%'
Q94. scrapyフレームワークの動作の仕組みについて説明してください。
リクエストはエンジンによってスケジューラに渡され、リクエストキューに入れられ、それが終わると
スケジューラは、リクエストキュー内のリクエストをダウンローダーに渡し、リクエストに対応するレスポンスリソースをフェッチし、レスポンスを独自のパースメソッドに渡して抽出します。
1) 必要なデータが抽出された場合、パイプラインファイルに渡して処理する。
2) urlが抽出された場合、リクエストキューにリクエストが無くなるまで、前のステップ(urlリクエストを送信し、エンジンはスケジューラにリクエストをキューに渡す...)を続け、プロセスが終了します。
Q95. 連想クエリとはどのようなもので、どのようなものですか?
複数のテーブルを結合してクエリーを行う。主に内部結合、左結合、右結合、完全結合(外部結合)。
Q96. クローラは複数のプロセスで書いた方が良いのでしょうか?それとも、複数のスレッドを使った方が良いのでしょうか?なぜでしょうか?
IOを多用するコード(ファイル処理、Webクローラーなど)では、マルチスレッドによる効率化が有効です(シングルスレッドでIO処理を行うとIO待ちが発生し、無駄な時間の浪費を招きます)。
スレッドAが待機している間に自動的にスレッドBに切り替わり、CPUリソースを無駄にしないことでより効率的にプログラムを実行することができる)。
実際のデータ収集作業では、ネットワークの速度やレスポンスと、自機のハードウェアの両方を考慮して、マルチプロセスやマルチスレッドを設定する必要があります。
Q97. データベースの最適化?
1) インデックス、SQL文の最適化、遅いクエリの分析。
2) SSDの使用、ディスクキューイング技術(RAID0、RAID1、RDID5)の使用など、ハードウェアを最適化する。
3) MySQL独自の内部テーブルパーティショニング技術を使って、データを異なるファイルにレイヤー分けすることで、磁気
ディスクの読み取り効率
4) 適切なテーブルエンジンの選択、パラメータ単位での最適化。
5) アーキテクチャレベルのキャッシュ、静的および分散キャッシュの実行。
6) 頻繁にアクセスするデータを保存するために、NoSQLなどの高速なストレージを使用する。
Q98.分散型クローラーで解決できる主な問題は何ですか?
1) ip
2)帯域幅
3) CPU
4) io
Q99. クロール中のCAPTCHAはどのように処理されるのですか?
1) scrapy には、以下のものが付属しています。
2)有償インターフェース
Q100. よくあるアンチクローラーとその対処法は?
1) ヘッダー経由のクローラー対策
ユーザーリクエストのヘッダからのクローリング対策は、最も一般的なクローリング対策である。クローラーに直接Headerを追加したり、ブラウザのUser-AgentをクローラーのHeaderにコピーしたり、Refererの値をターゲットのウェブサイトのドメインに変更したりすることができます。
2) ユーザーの行動に基づくクローラー対策
同一IPが短時間に何度も同じページを訪れたり、同一アカウントが短時間に何度も同じ操作を行うなど、ユーザーの行動を検知することで、そのような行動を防止します。
ほとんどのサイトが前者の状況にあり、IPプロキシの利用が解決策となります。
ウェブ上で公開されているプロキシIPをクロールする専用のクローラーを書き、それらを検知してすべて保存することができます。
多数のプロキシ ip があれば、数回のリクエストごとに一つの ip を変更することができます。これは requests や urllib2 で簡単にできるので、最初のアンチクローラーを回避することが簡単にできます。
2つ目のケースは、各リクエストの後に数秒のランダムな間隔で次のリクエストを行うことができます。
ロジックホールのあるサイトでは、同じアカウントで短時間に何度もリクエストできないという制約を、何度かリクエストしてログインからログアウトし、ログインし直してリクエストを続けることで回避しているところもあります。
3) 動的ページのクローラー対策
まず、Fiddlerを使ってWebリクエストを解析し、ajaxリクエストを見つけ、さらに特定のパラメータとレスポンスの特定の意味を解析できれば、上記のような方法が使えるようになります。
requestsやurllib2で直接ajaxリクエストをシミュレートし、レスポンスのjsonをパースして必要なデータを取得します。
しかし、サイトによってはajaxリクエストのパラメータをすべて暗号化してしまい、必要なデータのリクエストを構築する方法がない。
この場合、selenium + phantomJSを使い、ブラウザカーネルを呼び出し、phantomJSでjsを実行し、人間の行動をシミュレートしてページ内のjsスクリプトをトリガーするのです。
最後に、Pythonの学習に役立つ学習チュートリアルをご紹介します!
初心者におすすめのPython基礎チュートリアル。その他のPythonビデオチュートリアル - Bサイトをフォローする。Pythonラーナーズ
関連
-
[解決済み】 python : 整数が必要です (str型を取得)
-
[解決済み】mean, nanmeanとwarning。空のスライスの平均
-
[解決済み】OpenCV Python cv2.perspectiveTransform。
-
[解決済み] エラー 特異な行列
-
[解決済み] Python - 'str' オブジェクトに 'close' 属性がありません。
-
[解決済み] ImportError: sqlalchemy という名前のモジュールがありません。
-
[解決済み] Matlabのセルアレイに相当するものは何ですか?
-
error: 'wblog/' has not a commit checked out
-
AttributeError: 'lxml.etree._Element' オブジェクトに属性 'translate' がない。
-
[解決済み] PyTorchテンソルのリサイズ
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み] TypeError: unsupported operand type(s) for +: 'NoneType' and 'str'」を修正するにはどうしたらいいですか?
-
[解決済み] AtributeError: 'module' オブジェクトに 'plt' 属性がない - Seaborn
-
[解決済み] LEFT JOIN Django ORM
-
[解決済み] 複数の凡例エントリを持つ Matplotlib ヒストグラム
-
[解決済み] Django - そのようなテーブルがない例外
-
ubuntuでspyderを起動すると「カーネルを起動中にエラーが発生しました。
-
flask web development create virtual blog post data bug AttributeError: 'NoneType' object has no attribute 'encode' solution
-
ImportError: Bad magic number in 'csv': b'\x03xf3rın'
-
[解決済み] PythonでGoogleを検索する
-
[解決済み] python3がcoloramaを認識しないのはなぜですか?