Python VS VBAでExcelのテキストボックスのコンポーネントを読み込む
2022-02-28 23:11:55
<ブロッククオート
著者 リトルミン
PythonがExcelからテキストボックスを読み込む
基本要件
今日、私はこのようなExcelファイルのテキストボックス内のテキストを読み取るために非常に奇妙な問題を見ました。

openxlpyなら読めると思ったのですが、openxlpyの公式ドキュメントをチェックしても対応するAPIが見つからず、何人かの偉い人に相談しても、同様の問題には対処していないとのことでした。
ガッカリだ。もっと上手にデータを解析して、これを読み取る方法を自分で書いてみるよ。
処理コード
xlsxファイルは、基本的にxml形式のzipアーカイブです。ファイルを解凍し、xmlパースを行って適切なデータを抽出するだけです。
xmlのパースにxpathとしてlxmlを使おうと思ったのですが、実際にテストしてみると、これらのxmlファイルは名前空間が多く、パースが非常に複雑で、一般的なxmlパースライブラリをいくつか試してみましたが、スムーズにパースできるものの、regularと比べると不便だと思い、結局xmlパースには正規表現を使ってみることにしました。
最終的な処理コードは以下の通りです。
import re
import os
import shutil
from zipfile import ZipFile
def read_xlsx_textbox_text(xlsx_file):
tempdir = tempfile.gettempdir()
basename = os.path.basename(xlsx_file)
xml_names = []
with ZipFile(xlsx_file) as zip_file:
for name in zip_file.namelist():
if name.startswith("xl/drawings/drawing"):
zip_file.extract(name, tempdir)
destname = f"{tempdir}/{name}"
xml_names.append(destname)
result = []
for xml_name in xml_names:
with open(xml_name, encoding="utf-8") as f:
text = f.read()
lines = re.findall("
result = read_xlsx_textbox_text("test.xlsx")
print(result)
Result.
What is JSON?
It is a data format; for example, we now specify that there is a txt text file to store the grades of a class; then, we specify that the format of the student grades in this text file is the first line, which is a row of headers (name, class, grade, subject, grade), and then, each line is a student's grade. The format in which this information is stored in the text file, then, is actually a data format.
Student Class Year Subject Grade
Zhang San Class 1 Freshman Senior Math 90
Li 4 Class 2 Freshman High Math 80
ok, corresponding to JSON, it actually also represents a data format, the so-called data format, is the form of data organization. For example, the student results just described, using JSON format to represent the words, as follows.
[{"Student":"Zhang San", "Class":"Class I", "Grade":"Freshman", "Subject":"Advanced Math", "Grade ":90}, {"Student":"Li Si", "Class":"Class 2", "Grade":"Freshman", "Subject":"Advanced Math" ;, "Grade":80}]
In fact, JSON, very simple, not at all complicated, is the same batch of data, a different form of data representation.
JSON's data syntax is actually quite simple: if it contains multiple data entities, such as multiple student grades, then you need to use the array representation, which is []. For a single data entity, such as a student's grades, then a {} is used to encapsulate the data. For each field in the data entity and the corresponding value, a key:value representation is used, with commas separating multiple key-value pairs; multiple {} representations are separated by commas between data entities.
...
So we're well on our way to reading the text of all the text boxes from an Excel file.
Note: If you have any other special needs, you can modify the code according to the actual situation, or you can contact the author of this article (Little Ming) to customize it accordingly.
Read the text box contents of an xls file
The above method, only supports reading xlsx format files, if we want to read xls format, we need to do the format conversion first.
Full code.
import win32com.client as win32
def read_xls_textbox_text(xls_file):
excel_app = win32.gencache.EnsureDispatch('Excel.Application')
# excel_app.DisplayAlerts = False
try:
wb = excel_app.Workbooks.Open(xls_file)
xlsx_file = xls_file+"x"
wb.SaveAs(xlsx_file, FileFormat=51)
finally:
excel_app.Quit()
return read_xlsx_textbox_text(xlsx_file)
If you want to not be prompted when an xlsx file with the same name exists, just turn off the comment
Test reading.
print(read_xls_textbox_text(r"E:\tmp\test2.xls"))
Result.
Where do we get our data from?
Internet industry: websites, apps, systems (trading systems.)
Traditional industry: telecommunications, people's Internet access, phone calls, texting, etc. data
Data sources: websites, apps
All have to send requests to our backend to get data and execute business logic; app gets data of products to be shown; sends requests to backend for transaction and checkout
Backend servers, such as Tomcat, Jetty; however, in fact, in the case of a large number of users, high concurrency (more than 10,000 visits per second), usually do not directly use Tomcat to receive requests. In such cases, Nginx is usually used to receive requests, and the backend is connected to a Tomcat cluster/Jetty cluster for load balancing under high concurrent access.
For example, Nginx, or Tomcat, after you configure it appropriately, all request data is stored as logs; the backend system that receives the requests (J2EE, PHP, Ruby On Rails), can also follow your specifications, and every time you receive a request, or every time you execute a business logic, you will type a log into the log file.
The website/app will send requests to the backend server, which will usually be received by Nginx and forwarded
...
xls format batch to xlsx
Suppose we have a batch of xls files that we want to batch convert to xlsx.
 I implemented this by converting the entire folder before closing the app, which is relatively faster to process, but probably more memory intensive, with the following code.
I implemented this by converting the entire folder before closing the app, which is relatively faster to process, but probably more memory intensive, with the following code.
import win32com.client as win32 # Import the module
from pathlib import Path
import os
def format_conversion(xls_path, output_path):
if not os.path.exists(output_path):
os.makedirs(output_path)
excel_app = win32.gencache.EnsureDispatch('Excel.Application')
try:
for filename in Path(xls_path).glob("[! ~]*.xls"):
dest_name = f"{output_path}/{filename.name}x"
wb = excel_app.Workbooks.Open(filename)
wb.SaveAs(dest_name, FileFormat=51)
print(dest_name, "Save complete")
finally:
excel_app.Quit()
To test.
excel_path = r"F:\excel document"
output_path = r"E:\tmp\excel"
format_conversion(excel_path, output_path)
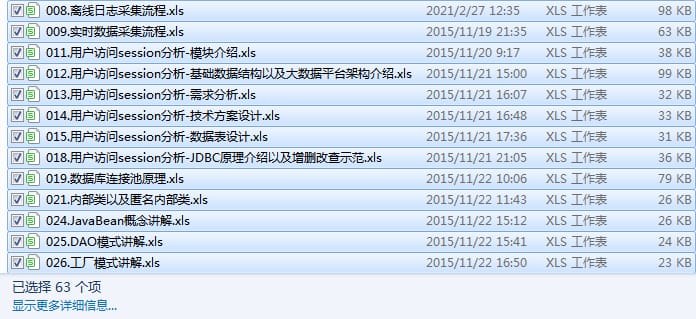
Result.
E:\tmp\excel/008.offline log collection process.xlsx Save complete
E:\tmp\excel/009.Real-time data collection process.xlsx Save complete
E:\tmp\excel/011.User access session analysis - module introduction.xlsx Save complete
E:\tmp\excel/012.User access session analysis-basic data structure and big data platform architecture introduction.xlsx Save as complete
E:\tmp\excel/013.User access session analysis-requirement analysis.xlsx Save to finish
E:\tmp\excel/014.User access session analysis - technical solution design.xlsx Save to finish
E:\tmp\excel/015.User access session analysis-Data table design.xlsx Save as complete
E:\tmp\excel/018.User access session analysis - JDBC principle introduction and demonstration of adding, deleting, changing and checking.xlsx Save as complete
E:\tmp\excel/019.Database connection pooling principle.xlsx Save to finish
...
Batch extraction of text box text from xlsx files
Above we have got a folder of xlsx files, our requirement is to extract the text box content of each xlsx file in this folder and save it as a corresponding txt format.
Processing code.
from pathlib import Path
xlsx_path = r"E:\tmp\excel"
for filename in Path(xlsx_path).glob("[! ~]*.xlsx"):
filename = str(filename)
destname = filename.replace(".xlsx", ".txt")
print(filename, destname)
txt = read_xlsx_textbox_text(filename)
with open(destname, "w") as f:
f.write(txt)
After execution, the corresponding txt file has been successfully obtained as follows.
 Demand escalation
The above read method merges all the textbox contents of the entire excel file together, but sometimes we have textboxes in multiple sheets of our excel file, and we want to be able to distinguish between the different sheets: the
Demand escalation
The above read method merges all the textbox contents of the entire excel file together, but sometimes we have textboxes in multiple sheets of our excel file, and we want to be able to distinguish between the different sheets: the
 Here we improve our read method so that it returns the text of the text box corresponding to each sheet name, testing it first.
First unpack the required files.
Here we improve our read method so that it returns the text of the text box corresponding to each sheet name, testing it first.
First unpack the required files.
from zipfile import ZipFile
from pathlib import Path
import shutil
import os
import tempfile
import re
xlsx_file = "test3.xlsx"
tempdir = tempfile.gettempdir()
basename = os.path.basename(xlsx_file)
xml_names = []
sheets_names = None
ids = []
with ZipFile(xlsx_file) as zip_file:
for name in zip_file.namelist():
if name.startswith("xl/drawings/drawing"):
zip_file.extract(name, tempdir)
destname = f"{tempdir}/{name}"
xml_names.append(destname)
elif name == "xl/workbook.xml":
zip_file.extract(name, tempdir)
sheets_names = f"{tempdir}/{name}"
elif name.startswith("xl/worksheets/_rels/sheet"):
tmp = name.lstrip("xl/worksheets/_rels/sheet")
ids.append(int(tmp[:tmp.find(". ")])-1)
print(xml_names, sheets_names, ids)
Result.
['C:\\Users\\\Think\\AppData\\\\Local\\\Temp/xl/drawings/drawing1.xml', 'C:\\Users\\\\Think\\\AppData\\\\\Local\\\Temp/xl/drawings/drawing2. xml', 'C:\\Users\\\Think\AppData\\\Local\\\Temp/xl/drawings/drawing3.xml', 'C:\\Users\\\Think\\AppData\\\\Local\\Temp/xl/drawings/ drawing4.xml', 'C:\Users\\\Think\AppData\\\Local\\\Temp/xl/drawings/drawing5.xml'] C:\Users\\Think\AppData\\Local\Temp/xl/workbook.xml [ 0, 1, 2, 4, 5]
To read the sheet name.
with open(sheets_names, encoding="utf-8") as f:
text = f.read()
sheet_names = re.findall(
'
'
, text)
tmp = []
for inx in ids:
tmp.append(sheet_names[inx])
sheet_names = tmp
sheet_names
Result.
['JSON', 'database connection pool', 'real-time data collection', 'factory design pattern', 'page conversion rate']
Parsing.
result = {}
for sheet_name, xml_name in zip(sheet_names, xml_names):
with open(xml_name, encoding="utf-8") as f:
xml = f.read()
lines = re.findall("
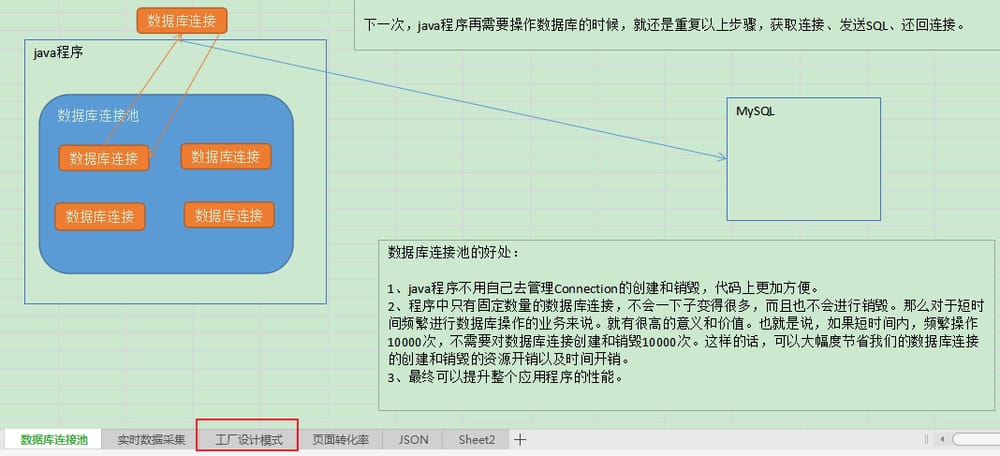
{'JSON': 'What is JSON? ....' ,
'Database connection pool': 'java program \n database connection \n database connection \n database connection \n MySQL...' ,
'Real-time data collection': '... Real-time data, usually read from a distributed message queue cluster, such as Kafka ....' ,
'Factory design pattern': 'Possible problems if there is no factory pattern: ....' ,
'Page conversion rate': 'User behavior analysis big data platform \n\n page single-hop conversion rate, ....'}
You can see that the content of the text box corresponding to each sheet has been read smoothly, and one by one.
Read the text of the text box for each sheet separately
Let's consolidate and wrap the above procedure into one method.
import re
import os
from zipfile import ZipFile
import tempfile
def read_xlsx_textbox_text(xlsx_file, combine=False):
tempdir = tempfile.gettempdir()
basename = os.path.basename(xlsx_file)
xml_names = []
sheets_names = None
ids = []
with ZipFile(xlsx_file) as zip_file:
for name in zip_file.namelist():
if name.startswith("xl/drawings/drawing"):
zip_file.extract(name, tempdir)
destname = f"{tempdir}/{name}"
xml_names.append(destname)
elif name == "xl/workbook.xml":
zip_file.extract(name, tempdir)
sheets_names = f"{tempdir}/{name}"
elif name.startswith("xl/worksheets/_rels/sheet"):
tmp = name.lstrip("xl/worksheets/_rels/sheet")
ids.append(int(tmp[:tmp.find(". ")])-1)
with open(sheets_names, encoding="utf-8") as f:
text = f.read()
sheet_names = re.findall(
'
'
, text)
tmp = []
for inx in ids:
tmp.append(sheet_names[inx])
sheet_names = tmp
result = {}
for sheet_name, xml_name in zip(sheet_names, xml_names):
with open(xml_name, encoding="utf-8") as f:
xml = f.read()
lines = re.findall("
Called as.
result = read_xlsx_textbox_text("test3.xlsx")
print(result)
from pathlib import Path
import os
xlsx_path = r"E:\tmp\excel"
for filename in Path(xlsx_path).glob("[! ~]*.xlsx"):
dest = filename.with_suffix("")
if not os.path.exists(dest):
os.mkdir(dest)
filename = str(filename)
print(filename, dest)
result = read_xlsx_textbox_text(filename)
for txtname, txt in result.items():
with open(f"{dest}/{txtname}", "w") as f:
f.write(txt)
print(f"\t{dest}/{txtname}")
Tested successfully creating a directory for each excel file, with each directory having the corresponding sheet name file based on which sheets exist in the text box.
Solving requirements using Python calls to VBA
The official VBA documentation is located at
https://docs.microsoft.com/zh-cn/office/vba/api/overview/excel
On the whole, the above method of parsing xml by itself is still quite troublesome, but after writing the above method, I had an idea. And Python can be fully compatible with VBA code, so the problem is simple. With VBA, not only is the code simple, but you don't have to think about formatting, and you can solve the problem directly by reading the code as follows
import win32com.client as win32
def read_excel_textbox_text(excel_file, app=None, combine=False):
if app is None:
excel_app = win32.gencache.EnsureDispatch('Excel.Application')
else:
excel_app = app
wb = excel_app.Workbooks.Open(excel_file)
result = {}
for sht in wb:
Count == 0. if sht:
Continue
lines = []
for shp in sht:
Shapes: try:
text = shp.TextFrame2.TextRange.
lines.append(text)
except Exception as e:
pass
result[sht.Name] = "\n".join(lines)
if app is None:
excel_app.Quit()
if combine:
return "\n".join(result.values())
return result
Test reads.
result = read_excel_textbox_text(r'F:\jupyter\test\extract word image\test3.xlsx')
print(result)
 Read the results smoothly.
Batch processing.
Read the results smoothly.
Batch processing.
from pathlib import Path
import os
xlsx_path = r"E:\tmp\excel"
app = win32.gencache.EnsureDispatch('Excel.Application')
try:
for filename in Path(xlsx_path).glob("[! ~]*.xls"):
dest = filename.with_suffix("")
if not os.path.exists(dest):
os.mkdir(dest)
filename = str(filename)
print(filename, dest)
result = read_excel_textbox_text(filename, app)
for txtname, txt in result.items():
with open(f"{dest}/{txtname}", "w") as f:
f.write(txt)
print(f"\t{dest}/{txtname}")
finally:
app.Quit()
After testing, the drawbacks of VBA processing are also obvious, with 63 files taking 25 seconds, while parsing xml directly takes only 259 milliseconds, not an order of magnitude difference in performance.
Solving requirements using xlwings
Apple computers do not support VBA, and the above code for calling VBA does not work for Apple computers, but fortunately xlwings has a new property text for accessing text box text in version 0.21.4.
As on Windows
Pywin32
and on Mac
appscript
The smart wrapper for xlwings, which already enables access to textbox text on Mac systems via appscript, is
import xlwings as xw
app = xw.App(visible=True, add_book=False)
wb = app.books.open(r'test3.xlsx')
for sht in wb.sheets:
print("-------------", sht.name)
for shp in sht.shapes:
if hasattr(shp, 'text') and shp.text:
print(shp.text)
wb.close()
app.quit()
Note: If your xlwings do not have this attribute, please note the following upgrade.
pip install xlwings -U
Summary
Reading data from excel is basically nothing that VBA can't do, and it's easy to call VBA in python, just use pywin32. Of course, 2007's xlsx is essentially a compressed package in xml format, and there is no data that can't be read by parsing xml text, but the code is incredibly hard to write, and of course you have to know more about the storage principles of xlsx.
The advantages and disadvantages of VBA versus parsing xml directly are clear.
VBA is an API directly supported by excel applications, the code is relatively simple to write, but the implementation is inefficient. VBA is not available for Apple computers and can be implemented using methods already encapsulated by xlwings.
Parsing xml files directly requires a better understanding of excel's storage format and is laborious to code, but extremely efficient to execute.
What do you think as a reader? You are welcome to post your thoughts in the comments section below.
result = read_xlsx_textbox_text("test.xlsx")
print(result)
関連
-
[解決済み】「RuntimeError: dictionary changed size during iteration」エラーを回避する方法とは?
-
[解決済み】終了コード -1073741515 (0xC0000135)でプロセス終了)
-
[解決済み】TypeError: int() の引数は文字列、バイトのようなオブジェクト、または数値でなければならず、'list' ではありません。
-
python-DataFrame-Error: ValueError: DataFrame のコンストラクタが正しく呼び出されていない!
-
[解決済み] Pythonで関数を繰り返す
-
[解決済み] Matplotlibで、fig.add_subplot(111)の引数はどういう意味ですか?
-
[解決済み] インデックスの配列を1-hotエンコードされたnumpy配列に変換します。
-
[解決済み] Pythonでリストをフォーマットして各要素を別行動で表示するには?[重複]。
-
[解決済み] Pythonで配列のリストを作成する
-
[解決済み] Pythonで配列の要素をカウントする【重複】について
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
Pythonの非常に便利な2つのデコレーターを解説
-
[解決済み】TypeError: '<=' は 'str' と 'int' のインスタンスの間でサポートされていない [重複].
-
[解決済み] テスト
-
[解決済み] トークン・エラーです。複数行のステートメントでEOF
-
[解決済み] ValueError: データがバイナリでなく、pos_label が指定されていない。
-
[解決済み] Plotly Dash ドロップダウンメニュー python
-
[解決済み] pythonw.exe か python.exe?
-
pip install MySQL-python reports "EnvironmentError: mysql_config not found" (環境エラー:mysql_configが見つかりません。
-
python3 reports AttributeError: モジュール 'sys' has no attribute 'setdefaultencoding'.
-
[解決済み] cv2 python で画像のクローンを作成する