Python crawl 楽しくて実用的な小説
2022-02-26 09:05:45
職場で釣りをしませんか?魚に手軽に触れるために、今日はクロールペンコートノベルのプログラムを自作してみました。まあ、実際はpythonの勉強と共有が目的なんですけどね。
1. まず、関連するモジュールをインポートする
import os
import requests
from bs4 import BeautifulSoup
# Declare the request headers
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36'
}
# Create the folder where the novel text is stored
if not os.path.exists('. /novel'):
os.mkdir('. /novel/')
# Access the site and get the page data
response = requests.get('http://www.biquw.com/book/1/').text
print(response)
2. サイトにリクエストを送信し、サイトデータを取得する
Webサイトのリンクの最後の桁は本のid値で、1桁が小説に対応し、idが1の小説を例にとって説明します。
サイトに入ると、章立てのリストがあるので、まず小説リスト名のクロールを完了させる
#### Rewrite the access code
```python
response = requests.get('http://www.biquw.com/book/1/')
response.encoding = response.apparent_encoding
print(response.text)
'''
The Chinese data returned this way is the correct one
'''
<イグ
この時点で、学生の皆さんは問題にお気づきかもしれません。普通にサイトを見に行ったら、返ってくるデータが文字化けしているのはなぜだろう?
これは、htmlページのエンコード形式と、pythonでアクセスしてデータを取得する際に使用するデコード形式が異なるためです。Pythonのデフォルトのデコード方式はutf-8ですが、ページのエンコーディングはGBKやGB2312かもしれないので、ページのデコード方式に合わせてPythonのコードを非常に特殊なものにする必要があります。
'''
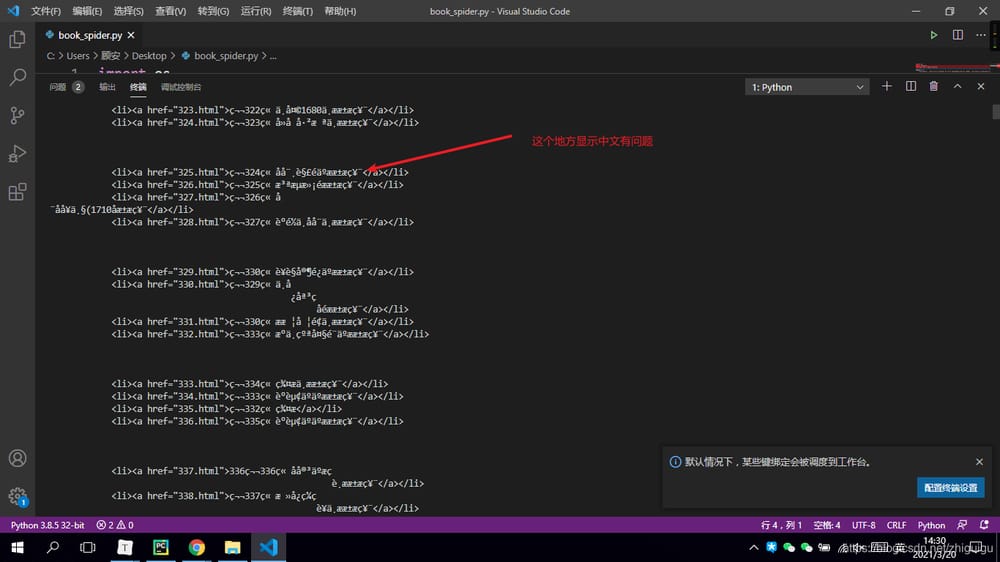
According to the above image, the data is stored in the a tag. a's parent tag is li, li's parent tag is ul, and above the ul tag is a div tag. So if you want to get the novel chapter data of the whole page, then you need to get the div tag first. And the div tag contains a class attribute, we can get the specified div tag through the class attribute, see the code for details~
'''
# lxml: html parsing library convert html code to python object, python can control html code
soup = BeautifulSoup(response.text, 'lxml')
book_list = soup.find('div', class_='book_list').find_all('a')
# soup object returns a list after getting bulk data, we can iterate over the list to extract it
for book in book_list:
book_name = book.text
# After getting the list data, you need to get the link to the article details page, the link is in the href attribute of the a tag
book_url = book['href']
book_info_html = requests.get('http://www.biquw.com/book/1/' + book_url, headers=headers)
book_info_html.encoding = book_info_html.apparent_encoding
soup = BeautifulSoup(book_info_html.text, 'lxml')
info = soup.find('div', id='htmlContent')
print(info.text)
with open('. /novel/' + book_name + '.txt', 'a', encoding='utf-8') as f:
f.write(info.text)
3. データを取得した後、ページからデータを抽出する
正しくデコードしてページデータを取得したら、いよいよ静的ページ解析の仕上げです。ページデータ全体から欲しいデータを取得する必要があります(チャプターリストのデータ)。
- まず、ブラウザを開きます
- F12キーを押して、デベロッパーツールを表示させます。
- 要素セレクタの確認
- ページ内に欲しいデータを選択し、要素を配置する
-
データが存在する要素のタグを確認する
'''
According to the above image, the data is stored in the a tag. a's parent tag is li, li's parent tag is ul, and above the ul tag is a div tag. So if you want to get the novel chapter data of the whole page, then you need to get the div tag first. And the div tag contains a class attribute, we can get the specified div tag through the class attribute, see the code for details~
'''
# lxml: html parsing library convert html code to python object, python can control html code
soup = BeautifulSoup(response.text, 'lxml')
book_list = soup.find('div', class_='book_list').find_all('a')
# soup object returns a list after getting bulk data, we can iterate over the list to extract it
for book in book_list:
book_name = book.text
# After getting the list data, you need to get the link to the article details page, the link is in the href attribute of the a tag
book_url = book['href']
4. 小説詳細ページへのリンクを取得した後、詳細ページに再度アクセスし、記事データを取得する
book_info_html = requests.get('http://www.biquw.com/book/1/' + book_url, headers=headers)
book_info_html.encoding = book_info_html.apparent_encoding
soup = BeautifulSoup(book_info_html.text, 'lxml')
5. 小説詳細ページの静的ページ解析
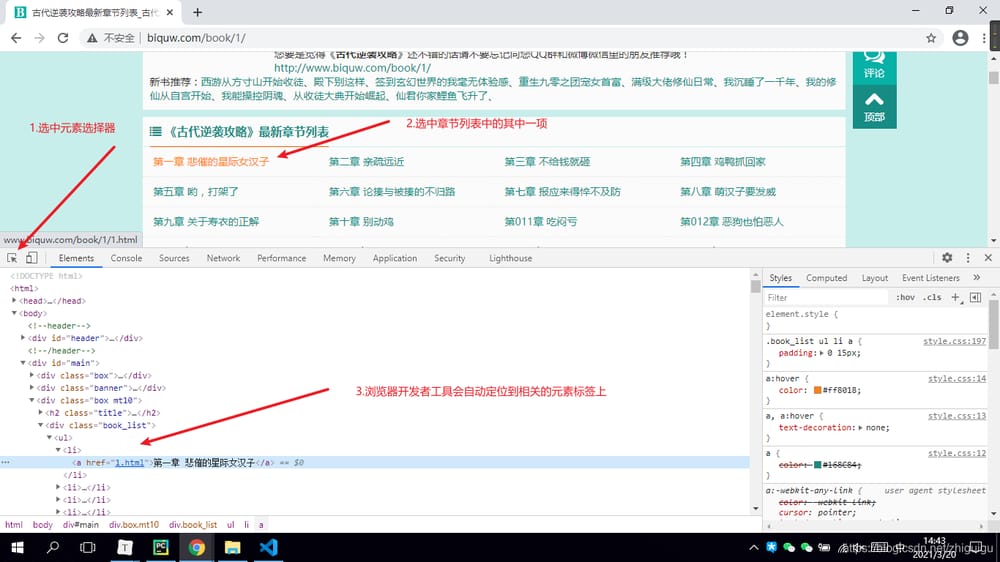
info = soup.find('div', id='htmlContent')
print(info.text)
6. データダウンロード
with open('. /novel/' + book_name + '.txt', 'a', encoding='utf-8') as f:
f.write(info.text)
最後に、このコードがどのように機能するかを見てみましょう。
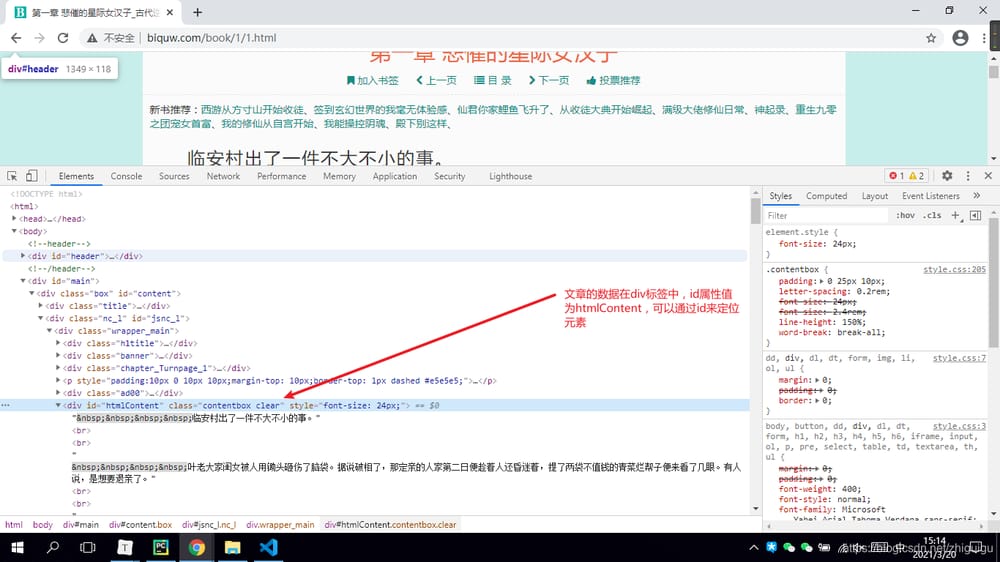
クロールされたデータ
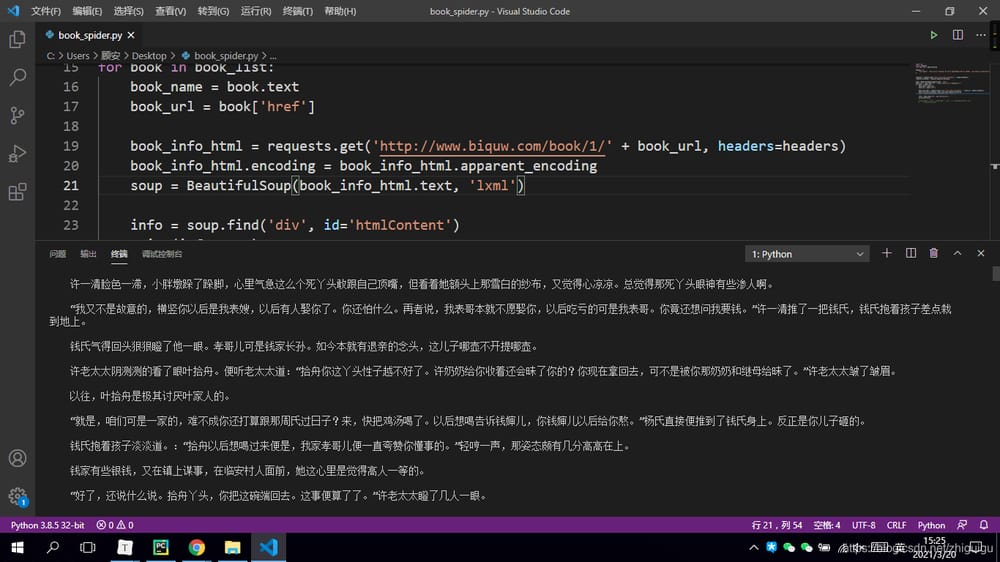
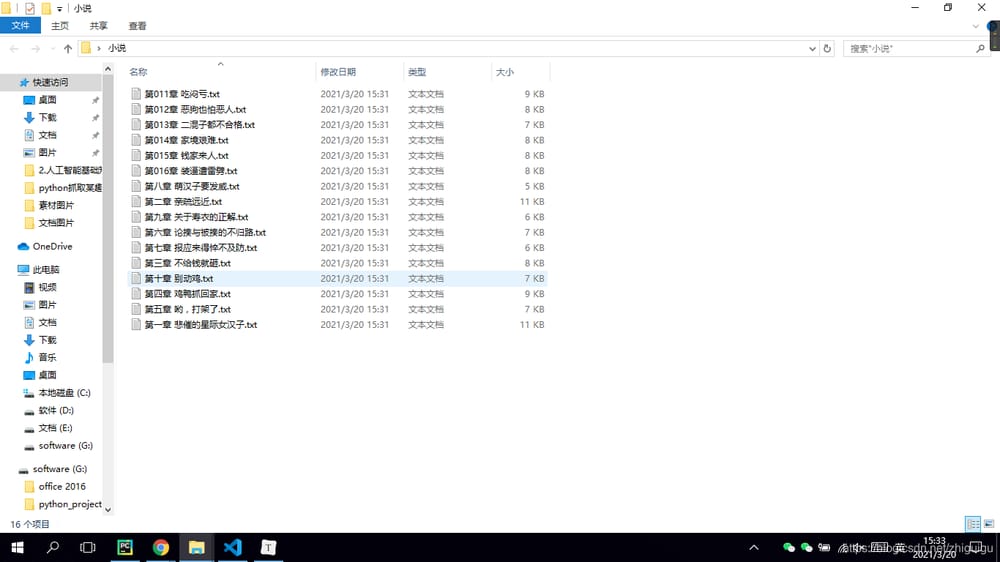
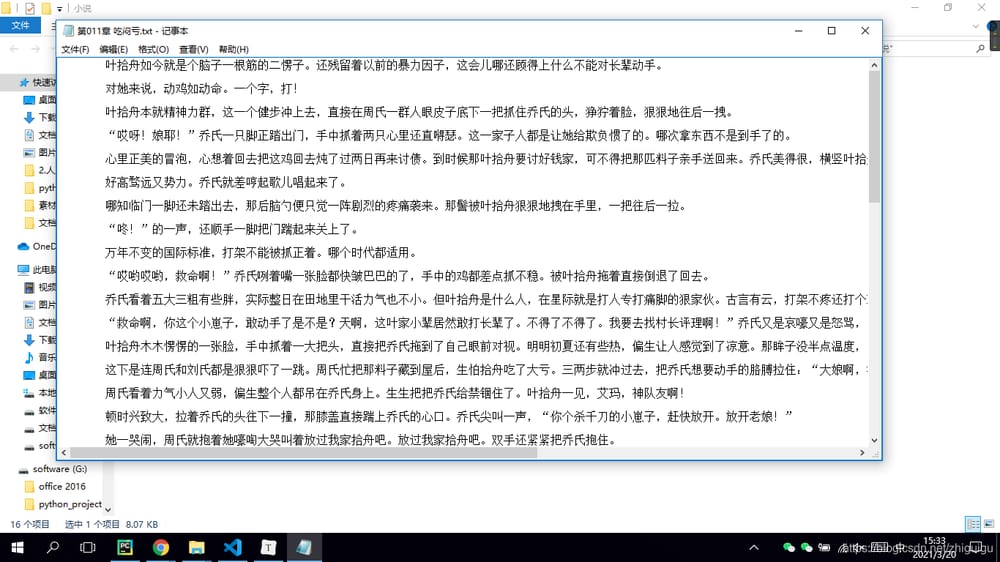
関連
-
[解決済み] [Solved] Map to List エラー。シリーズオブジェクトを呼び出すことはできません
-
[解決済み】divisi2のインストール時にVisual C++ for pythonがexit status 2で失敗する。
-
[解決済み] Pandasをインポートするとエラーが発生する AttributeError: モジュール 'pandas' にはiPython Notebookの属性 'core' がない
-
[解決済み] PythonでXMLをきれいに印刷する
-
[解決済み] 「ゼロで割っていない時に「ログでゼロで割るが発生しました。
-
[解決済み] IOError: [Errno 22] invalid mode ('r') or filename: 'c:\Python27╱test.txt' [duplicate].
-
[解決済み] AtributeError: 'module' オブジェクトに 'plt' 属性がない - Seaborn
-
[解決済み] Pycharm エラー Django はこの環境ではインポートできません。
-
[解決済み] mongodb: 存在しない場合は挿入する
-
TypeError: 'NoneType' オブジェクトが呼び出し可能でない場合の解決策を文書化する。
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み】AttributeError: 'module'オブジェクトには属性がありません。
-
[解決済み】pythonで添え字を印刷する
-
[解決済み】Python TypeError: object.__format__ に渡される空でないフォーマット文字列
-
pycharmでtensorflowを使う方法を教えます。
-
Pythonデータ分析における欠損値の扱い方8つの方法を解説
-
[解決済み] matplotlib を使って画像をグレースケールで表示する
-
[解決済み] ImportError: pymongo'という名前のモジュールがありません。
-
[解決済み] argsortを降順で使用することは可能ですか?
-
[解決済み] エラー例外はBaseExceptionから派生する場合でも、派生しなければならない (Python 2.7)
-
[解決済み] dict_keys' オブジェクトを取得すると、リストへのキャストにもかかわらずインデックスがサポートされない