Python正規表現ガイド
この記事では、Pythonの正規表現のサポートについて説明します。正規表現の基本から、Python正規表現標準ライブラリの完全な紹介とその使用例について説明します。この記事では、効率的な正規表現の書き方や、正規表現の最適化については扱いませんので、それらのトピックについては他のチュートリアルを参照してください。
注:この記事はPython 2.4に基づいています。分からない用語があったら、Googleやwiki Baiduで調べることを忘れないでください、WHATEVER。
1. 正規表現の基本
1.1. 簡単な紹介
正規表現はPythonの一部ではありません。正規表現は文字列を処理するための強力なツールで、独自の構文と、strに付属するメソッドほど効率的ではないかもしれませんが、非常に強力な別の処理エンジンを持っています。このおかげで、正規表現の構文は、それを提供するすべての言語で同じです。唯一の違いは、異なるプログラミング言語の実装でサポートされている構文の数です。しかし、心配しないでください。サポートされていない構文は、通常、一般的でない部分なのです。他の言語ですでに正規表現を使ったことがある人は、それを見るだけで正規表現を使い始めることができます。
正規表現を使ったマッチングの流れを以下の図に示します。
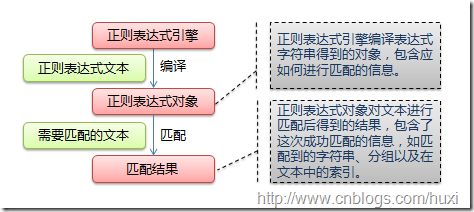
正規表現の一般的なマッチング処理は、式を取り出してテキスト中の文字と順に比較し、すべての文字が一致すればマッチング成功、一致しない文字があればマッチング失敗となるものです。式の中に量詞や境界線がある場合は少し処理が異なりますが、以下の例や使用頻度を上げることで容易に理解できます。
Pythonでサポートされている正規表現のメタキャラクタと構文の一覧を下図に示します。
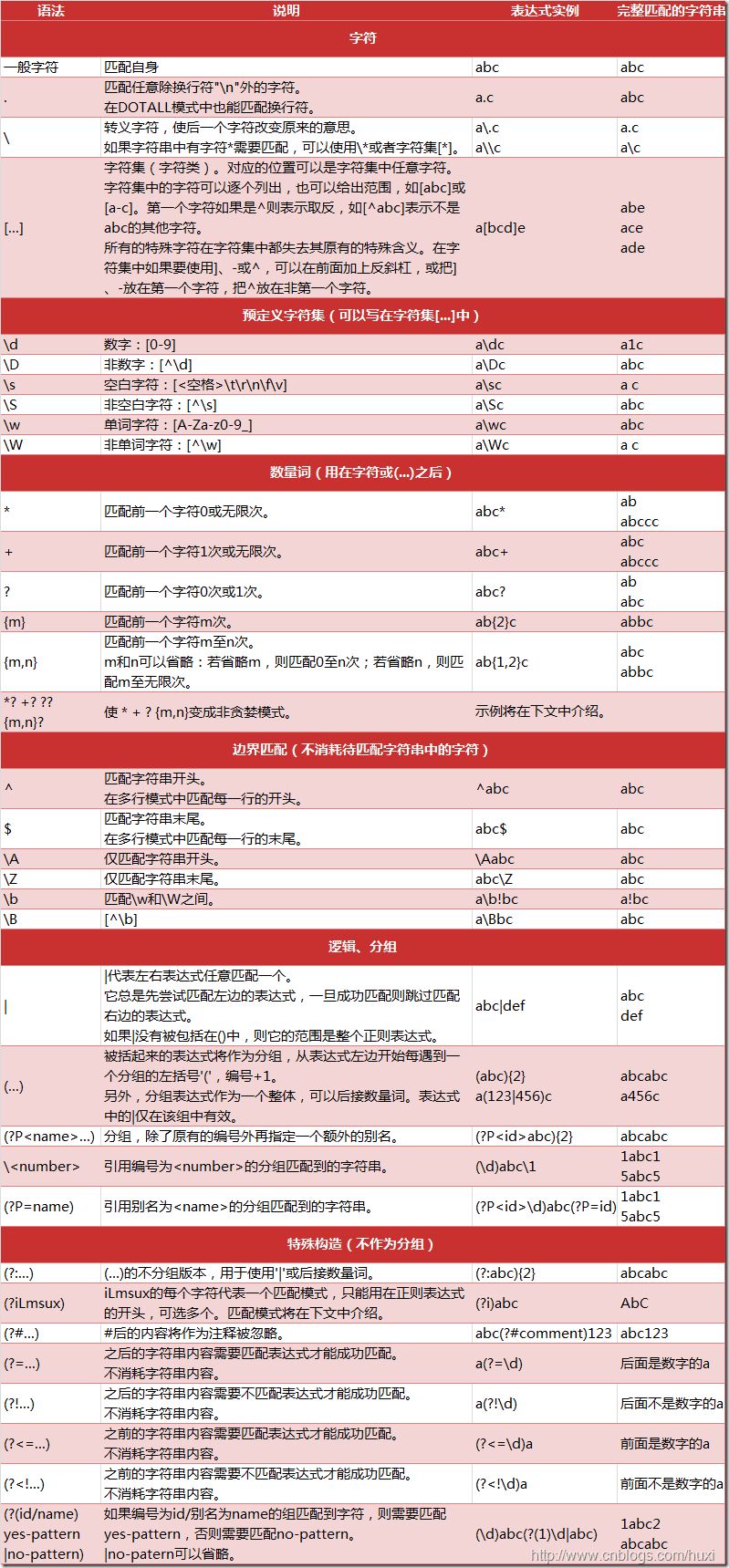
1.2. 量子詞の欲張りモードと非欲張りモード
Pythonの数量子はデフォルトで greedy (いくつかの言語ではnon-greedy)で、常にできるだけ多くの文字にマッチしようとします。一方、non-greedyは常にできるだけ少ない文字にマッチしようとします。例えば、正規表現 "ab*" は、 "abbbc" を見つけるために使用されます。また、欲張りでない量詞 "ab*? " ならば "a" を見つけます。
1.3. バックスラッシュのバグ
多くのプログラミング言語と同様に、正規表現のエスケープ文字として" \" を使用すると、バックスラッシュのトラブルが発生することがあります。テキスト中の "\" という文字にマッチさせたい場合、プログラミング言語の表現を用いた正規表現では、4つのバックスラッシュ "\ \`` が必要になります:最初の2つと最後の2つはプログラミング言語ではバックスラッシュにエスケープし、正規表現ではバックスラッシュにエスケープします。同様に、" \d" で数字をマッチングさせる場合は、r" \d" と書くことができるのです。ネイティブの文字列なら、バックスラッシュを見逃す心配もないし、直感的に式を書ける。
1.4. パターンマッチング
正規表現では、大文字小文字を無視する、複数行のマッチングなど、多くの利用可能なマッチングパターンを提供します。これは、Patternクラスのファクトリーメソッド re.compile(pattern[, flags]) でまとめてカバーされています。
2. reモジュール
2.1. reを始める
Pythonはreモジュールを通して正規表現のサポートを提供します。reの一般的な使用手順は、まず正規表現の文字列形式をPatternインスタンスにコンパイルし、次にPatternインスタンスでテキストを処理してマッチするもの(Matchインスタンス)を取得し、最後にMatchインスタンスで情報を取得して他の操作を行うというものです。
# encoding: UTF-8
import re
# Compile regular expressions into Pattern objects
pattern = re.compile(r'hello')
# Use Pattern to match text, get match result, return None if unable to match
match = pattern.match('hello world!')
if match:
# Use Match to get group information
print match.group()
### Output ###
# hello
re.compile(strPattern[,flag])とします。
このメソッドは Pattern クラスのファクトリーメソッドで、文字列形式の正規表現を Pattern オブジェクトにコンパイルするために使用されます。2番目のパラメータ flag はマッチパターンであり、例えば re.I | re.M のように、プレースまたは演算子 '|' とともに使用して両方を示すことができる値を取ります。あるいは、regex文字列でパターンを指定することもできます。例えば re.compile('pattern', re.I | re.M) は re.compile('(?im)pattern' ) と等価です。
オプションの値は
I(re.IGNORECASE): 大文字小文字を無視する(以下、括弧内にフルケース) M(MULTILINE): 複数行モード、'^' と '$' の挙動を変更する (上記) S(DOTALL): 任意のマッチモードをポイント、 '. の挙動を変更する。 の動作を変更する L(LOCALE): 現在のロケールに応じて意図した文字クラスを作る U(UNICODE): unicodeで定義された文字属性に応じて意図した文字クラスを作る X(VERBOSE): 詳細モード。このモードの正規表現は複数行にでき、空白文字を無視し、コメントを含むことができます。次の2つの正規表現は等価です。
a = re.compile(r"""\d + # the integral part
\. # the decimal point
\d * # some fractional digits""", re.X)
b = re.compile(r"\d+\. \d*")
reは正規表現を完成させるための多数のモジュール式メソッドを提供します。これらのメソッドは、パターンインスタンスの対応するメソッドを使用して置き換えることができます。ただし、re.compile()のコードを1行少なく書くことができるという利点があるだけで、コンパイルされたパターンオブジェクトを再利用することはできません。これらのメソッドは Pattern クラスのインスタンスメソッドのセクションで一緒に紹介されます。たとえば、上記の例は次のように省略することができます。
m = re.match(r'hello', 'hello world!')
print m.group()
また、reモジュールにはescape(string)というメソッドがあり、これは文字列中の*/+/? などの正規表現のメタ文字を返す前に使うもので、多くのメタ文字にマッチさせたいときに便利です。
2.2. マッチ
Matchオブジェクトはマッチの結果であり、マッチに関する多くの情報を含んでいます。これらの情報は、Matchが提供する読み取り可能なプロパティやメソッドを使って取得することが可能です。
属性です。
文字列。re: マッチングに使用するPatternオブジェクト pos: 検索を開始するテキスト内の正規表現のインデックス。この値は、Pattern.match() および Pattern.seach() メソッドの同名の引数と同じである。テキスト中の正規表現の検索終了位置のインデックス。この値は、Pattern.match() および Pattern.seach() メソッドの同名の引数と同じです。 lastindex: テキスト内で最後にキャプチャされたグループ化のインデックスです。キャプチャしたグループがない場合はNoneとなる。 lastgroup: 最後にキャプチャしたグループのエイリアス。グループに別名がない場合、またはキャプチャしたグループがない場合は、Noneになります。
メソッドです。
group([group1, ...]) とします。
複数の引数を指定した場合はタプルとして返します。group1には数字かエイリアスを使用できます。数字0はマッチした部分文字列全体を表します。
グループ化された全てのインターセプト文字列をタプルとして返す。group(1,2,...last) を呼ぶのと同じです。 default は、インターセプトされた文字列を持たないグループをこの値に置き換えることを意味し、デフォルトはNoneです。 groupdict([default]):
エイリアスをキーとし、インターセプトされたグループの部分文字列を値とする辞書を返す。エイリアスのないグループは含まれない。デフォルトは上記と同じ。 start([group]):
指定されたグループによってインターセプトされた部分文字列の開始インデックス(部分文字列の最初の文字のインデックス)を返します。
文字列中の指定されたグループに含まれる部分文字列の終了インデックス(部分文字列の最後の文字のインデックス+1)を返します。
return(start(group), end(group)). expand(テンプレート):
テンプレートにマッチしたグループを代入して返す。\テンプレート内のグループを指すのに使えるのは \id または \g<id>, \g<name> で、数字の0は使えません。 \id は \g<id> と同じですが、统一は10番目のグループと見なされ、もし统一に0を付けて表現したい場合は \g<1> 0 のみ使用することができます。
import re
m = re.match(r'(\w+) (\w+)(?P<sign>. *)', 'hello world!')
print "m.string:", m.string
print "m.re:", m.re
print "m.pos:", m.pos
print "m.endpos:", m.endpos
print "m.lastindex:", m.lastindex
print "m.lastgroup:", m.lastgroup
print "m.group(1,2):", m.group(1, 2)
print "m.groups():", m.groups()
print "m.groupdict():", m.groupdict()
print "m.start(2):", m.start(2)
print "m.end(2):", m.end(2)
print "m.span(2):", m.span(2)
print r"m.expand(r'\2 \1\3'):", m.expand(r'\2 \1\1\3')
### output ###
### m.string: hello world!
### m.re: <_sre.SRE_Pattern object at 0x016E1A38>
# m.pos: 0
# m.endpos: 12
# m.lastindex: 3
# m.lastgroup: sign
# m.group(1,2): ('hello', 'world')
# m.groups(): ('hello', 'world', '!')
# m.groupdict(): {'sign': '!}
# m.start(2): 6
# m.end(2): 11
# m.span(2): (6, 11)
# m.expand(r'\2 \1\3'): world hello!
2.3. パターン
Pattern オブジェクトはコンパイルされた正規表現で、Pattern が提供する一連のメソッドによってテキストとマッチングさせることができます。
パターンは直接インスタンス化することはできず、re.compile()を使用して構築する必要があります。
Patternは、式に関する情報を取得するためのいくつかの読み取り可能なプロパティを提供します。
パターン。コンパイル時に使用する式の文字列 flags: コンパイル時に使用するマッチングパターン。数値形式。式中のエイリアスを持つグループのエイリアスをキー、グループの番号を値とする辞書、エイリアスのないグループは含まれない。
import re
p = re.compile(r'(\w+) (\w+)(?P<sign>. *)', re.DOTALL)
print "p.pattern:", p.pattern
print "p.flags:", p.flags
print "p.groups:", p.groups
print "p.groupindex:", p.groupindex
### output ###
### p.pattern: (\w+) (\w+)(?P<sign>. *)
### p.flags: 16
# p.groups: 3
# p.groupindex: {'sign': 3}
インスタンスメソッド[ | re module method ]。
match(string[, pos[, endpos]]) | re.match(pattern, string[, flags]):
このメソッドは、string の pos 添え字からパターンとのマッチングを試みます。string の末尾でパターンがまだマッチング可能な場合、Match オブジェクトを返します。マッチング中にパターンにマッチングできない場合、またはマッチングが終了する前に endpos に達した場合、 None を返します。
posとendposのデフォルト値はそれぞれ0とlen(string)です。re.match()ではこの二つの引数は指定できず、引数flagsでパターンをコンパイルする際にマッチパターンを指定することになります。
注意:この方法は完全一致ではありません。パターンの末尾に文字列が残っていても、成功したとみなされます。完全一致させるには、式の最後にバウンダリーマッチ「$」を追加します。
例については、サブセクション2.1を参照してください。 search(string[, pos[, endpos]]) | re.search(pattern, string[, flags]).search(pattern, string[, flags]).search(string[, pos[, endpos]):
このメソッドは、文字列の中からうまくマッチングできる部分文字列を探すために使用されます。文字列の pos 添え字からパターンとのマッチングを試み、文字列の末尾でまだマッチング可能であれば Match オブジェクトを返します。マッチング不可能な場合は pos に 1 を加えて再試行し、pos=endpos までマッチング不可能な場合は None を返します。
posとendposのデフォルト値は0とlen(string))です。re.search()ではこの2つのパラメータを指定できず、flagsパラメータはパターンのコンパイル時にマッチするパターンを指定するために使用されます。
# encoding: UTF-8
import re
# Compile regular expressions into Pattern objects
pattern = re.compile(r'world')
# Use search() to find a matching substring, and return None if no substring exists that can match
# In this example, match() does not match successfully
match = pattern.search('hello world!')
if match:
# Use Match to get the grouping information
print match.group()
### Output ###
# world
split(string[, maxsplit]) | re.split(pattern, string[, maxsplit]):
マッチング可能な部分文字列で分割された文字列のリストを返す。maxsplitは、すべての分割ではなく、最大分割数を指定するために使用される。
import re
p = re.compile(r'\d+')
print p.split('one1two2three3four4')
### output ###
# ['one', 'two', 'three', 'four', '']
findall(string[, pos[, endpos]]) | re.findall(pattern, string[, flags]):
文字列を検索し、マッチするすべての部分文字列をリストとして返す。
import re
p = re.compile(r'\d+')
print p.findall('one1two2three3four4')
### output ###
### ['1', '2', '3', '4']
finditer(string[, pos[, endpos]]) | re.finditer(pattern, string[, flags]):
文字列を検索し、各マッチ結果(Matchオブジェクト)に順番にアクセスするイテレータを返します。
import re
p = re.compile(r'\d+')
for m in p.finditer('one1two2three3four4'):
print m.group(),
### output ###
### 1 2 3 4
sub(repl, string[, count]) | re.sub(pattern, repl, string[, count]):
文字列中の一致する部分文字列を repl で置き換えた後、置き換えられた文字列を返します。
replが文字列の場合、グループ分けを参照するために \id または \g<id>, \g<name> を使用できますが、0番を参照することはできません。
replがメソッドの場合、このメソッドは引数(Matchオブジェクト)を1つだけ取り、置換用の文字列を返す必要があります(返された文字列の中でグループ化を再度参照することはできません)。
count は置換の最大数を指定するために用いられ、指定しない場合は全てとなる。
import re
p = re.compile(r'(\w+) (\w+)')
s = 'i say, hello world!'
print p.sub(r'\2 \1', s)
def func(m):
return m.group(1).title() + ' ' + m.group(2).title()
print p.sub(func, s)
### output ###
### say i, world hello!
### # I Say, Hello World!
subn(repl, string[, count]) |re.sub(pattern, repl, string[, count]):
sub(repl, string[, count]), 置換数)を返す。
import re
p = re.compile(r'(\w+) (\w+)')
s = 'i say, hello world!'
print p.subn(r'\2 \1', s)
def func(m):
return m.group(1).title() + ' ' + m.group(2).title()
print p.subn(func, s)
### output ###
# ('say i, world hello!', 2)
# ('I Say, Hello World!', 2)
以上が、Pythonの正規表現への対応です。正規表現に習熟することはプログラマにとって必須のスキルであり、最近では文字列を扱わないプログラムはないでしょう。筆者も紳士に励まされながら、初級編に突入です(^_^)
また、図中の特殊な構成は例として示されておらず、これらを使った正規表現もやや難解です。興味のある方は、abcで始まらない単語にマッチする方法を考えてみてください^_^。
関連
-
[解決済み] [Solved] ImportError: libSM.so.6: cannot open shared object file: そのようなファイルまたはディレクトリはありません
-
[解決済み】super()がエラーで失敗する。親がオブジェクトを継承していない場合、TypeError "argument 1 must be type, not classobj" が発生する。
-
[解決済み] Python2.6.6でValueError: 0 length field name in formatが発生した。
-
[解決済み】pygletとpygameのどちらで始める?[クローズド]
-
[解決済み] Pythonで同じ長さの複数のリストをインターリーブする
-
[解決済み] Python 3.1でunichrが使用できない
-
[解決済み] 「カスタムスロットで「TypeError: ネイティブのQtシグナルは呼び出し可能ではありません。
-
ノード名やサービス名が提供されていない、あるいは不明である。
-
Python 3.6: "Guess the Number Game" TypeError: '<' は 'str' と 'int' のインスタンスの間でサポートされていません。
-
python TypeError: 'NoneType' オブジェクトは添え字を付けられません。
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み】お使いのCPUは、このTensorFlowバイナリが使用するようにコンパイルされていない命令をサポートしています。AVX AVX2
-
[解決済み] Tensorflow Slim: TypeError: 期待されたのはint32ですが、代わりに'_Message'型のTensorを含むリストが表示されました。
-
[解決済み] Python MySQLdb の問題 (TypeError: %d format: 数値が必要で、str ではありません)
-
[解決済み] Pythonの「範囲」を使った2桁の数え方
-
[解決済み] Python スコアボード
-
[解決済み] pyodbc.connect のタイムアウト引数は、SQL Server への呼び出しでは無視されます。
-
[解決済み] Python の ElementTree を XML ファイルにきれいに印刷するにはどうしたらいいですか?
-
[解決済み] ValueError: dictにfieldnamesにないフィールドが含まれている。
-
[解決済み] TypeError: キャラクタバッファオブジェクトが必要です。
-
Pyinstaller を使って Python プログラムをパッケージングしてみる 発生した問題のまとめ