pythonの中国語エンコード文字化け問題の解決方法
前文です。
中国語のエンコーディングは常にプログラマの頭痛の種であり、Python 2の文字エンコーディングは新参者を狂わせるのに十分なものです。この記事では、Python 2と3における文字エンコーディングと様々なエンコーディングの問題を平易な言葉で説明しようと思います。
I. 文字エンコーディングとは
文字コードとは何かを正確に理解しないことには、文字コードの問題を徹底的に解決することはできない。コンピュータはその性質上 0と1しか認識しない2進法 ハードディスクを分解してみると、いわゆる0と1の数字は見えません。見えるのは滑らかな光沢のあるディスクだけです。十分に大きなルーペを使うと、ディスクの表面には無数の凹凸成分があることがわかります。** 凹んでいるのが0、飛び出しているのが1です。** これがコンピュータのやり方です これがコンピュータによる2進法の表現方法なのです。 /これがコンピュータが2進法を表現する方法です。 {コンピュータはこうして2進数を表現する。 1. ASCII
さて、ここで最初の問題に直面する。それは、英語のような人間の言葉を、どうやってコンピューターに理解させるか、ということだ。英語を例にとると、英語には 英字(大文字・小文字)、句読点、特殊記号 . これらの文字や記号に一定の数値を与え、その数値を2進数に変換すれば、コンピュータは当然これらの記号を正しく読み取ることができ、その数値を用いることで、コンピュータは2進数を数値に対応する文字に変換し、人間が読めるように表示することができるようになるのです。そこで、7桁または8桁の2進数の組み合わせで128個または256個の文字を表現するASCIIというものが生まれました。これにより、ほとんどの場合、英語から2進数への変換が容易になった。
2. GB2312
しかし、コンピューターはアメリカ人が発明したものですが、世界中の人が使っています。ここで、また新たな問題が発生する。 コンピュータに中国語を理解させるには 中国語をコンピュータに理解させるには?ASCIIコードでは明らかに解決できない。この問題を解決するために、中国国家標準化局は1980年に「情報交換のための中国語文字エンコーディングの文字セット"」を発行し、GB2312というエンコーディングを提案した。GBKは、GB2312-1980国家標準に対応する内部コード規格と互換性を持ちながら、文字レパートリーレベルではISO/IEC10646-1およびGB13000-1のすべての日中韓(CJK)文字、合計20902文字をサポートします。こうすることで <マーク 漢字のコンピュータ処理
3. ユニコード
英語と中国語の問題が解決された今、新たな問題が浮上してきた。世界には、英語や中国語だけでなく、アラビア語、スペイン語、日本語、韓国語など、実に多くの国がある。それぞれの言語に対応した符号化方式を作るのは難しいのだろうか?このような状況を踏まえて、新しい符号化方式が誕生した。それがユニコードです。 Unicodeはユニコード、ユニコードとも呼ばれ、各言語の各文字に統一された固有のバイナリコードを設定し、言語間やプラットフォーム間のテキスト変換・処理の要件を満たすものです。 Unicodeは、ヨーロッパ、アフリカ、中東、アジアの言語(東アジアの絵文字や韓国の碑文も含む)をサポートしています。これにより、英語、中国語、日本語、韓国語のいずれを使用している場合でも、すべてUnicodeコードに含まれ、固有のバイナリコードに対応するようになります。そうすれば、みんながハッピーになれる。 <マーク みんながユニコードを使っている限り、トランスコードで困ることはもうないだろう
4. UTF-8
しかし、Unicodeはより多くの文字を含んでいるため、以下のようなことが考えられます。 それは <マーク パース効率 で、UnicodeはISO Latin-1文字セットを上位バイトを追加して拡張しているので、その上位バイトのビットが0のとき、下位バイトはISO Latin-1文字となります。ASCIIで表現できる文字にUnicodeを使用すると、UnicodeはASCIIの2倍の容量を消費し、ハイバイトの0はASCIIには無意味なので効率的ではありません。この問題を解決するために、いくつかの中間フォーマットの文字セットが登場し、それらは <マーク 一般的な変換形式 . 私たちが最もよく使うフォーマットはUTF-8で、これはこの変換フォーマットの一つです。UTF-8が実際にどのように効率を向上させるかについてはここでは触れません。ただ、それらがどのように関係し合っているかを知っておく必要があります。
要約すると
1. 英字を扱うため、ASCIIコードを生成する。
/{br
2. 中国語の文字を扱うため、GB2312 を生成しました。
3. 国字を扱うために、Unicodeが作られた。
/4.
4. Unicode の保存と転送のパフォーマンスを向上させるために、Unicode の実装である UTF-8 が作成されました。
II. Python2における文字エンコーディング
1. Python2 のデフォルトの文字エンコーディングは ASCII です。 というのは、Pythonはエンコーディングの種類を指定しない限り、データをデフォルトでASCIIとして扱うということです。この問題の最も直接的な現れとして、漢字を含むpythonファイルを書くと、実行時にエラーが表示されることが挙げられます。図に示すように


この問題の原因は、Python2はpythonスクリプト全体をASCIIとして扱っており、ここに"小明"のように漢字がある場合、ASCIIでは漢字を扱えないことがわかっているので、このエラーが発生するのです。 解決方法は <マーク ファイルの先頭に1行のエンコーディング宣言を追加する 図に示すように
# -*- coding: utf-8 -*-

こうすることで、Pythonはこのスクリプトを処理する際に、スクリプト全体をUTF-8のエンコーディングで処理し、漢字を正しくパースすることができるようになります。
2. Python2にはstrとunicodeの文字列がある .
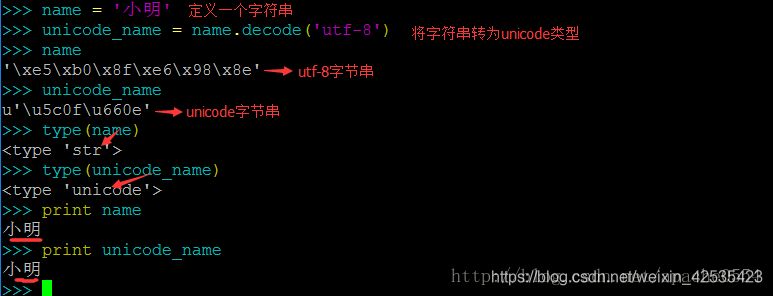
上の図は、Python2における2種類の文字列を表しています。
name変数には"Xiao Ming"という文字列が与えられます。
unicode_nameは、変数nameのユニコード形式です。ここでは、後で詳しく説明するdecode()メソッドを使っています。
両者はターミナルで異なるバイト列を返し、typeは異なるデータ型を返しますが、printは同じ出力をします。
これは Python における文字列の標準的な形式を意味し、文字列がどのようなエンコーディングであっても Python ではバイト文字列として表現されることを意味します。 バイト列はエンコードされていないもので、最終的にコンピュータに渡されるデータの形に相当する。
3. Python2はunicodeのバイト列を直接見ることができます。
上の画像では、unicode_nameと入力したときの戻り値がunicodeのバイト列になっており、直接見ることができるようになっています。そして、その中にある python3 では、ユニコード・バイト列を直接見ることはできません。 Python3はデフォルトでunicodeエンコードを使用しており、unicodeバイト列はそのまま中国語として処理されるためです。
まとめると
1. Python2 のデフォルトの文字エンコーディングは ASCII です。
2. Python2にはstrの型としてstrとunicodeがありますが、strには様々なエンコーディングの違いがあり、unicodeはエンコーディングなしの標準的な形です。
3. Python2は、ユニコードのバイト列を直接見ることができます。
III. decode()メソッドとencode()メソッド
このセクションの舞台を整えるために前述したことをすべて述べたので、ここからはPython2で文字エンコーディングを扱うことになります。 まず、Pythonが提供するエンコーディング変換のための2つのメソッド、decode()とencode()について学びましょう。
decode()メソッドは、他のエンコードされた文字をUnicodeエンコードされた文字に変換します。
/{br
encode()メソッドは、Unicodeでエンコードされた文字を他のエンコードされた文字に変換するメソッドです。
さっそくですが、本題に入りましょう。
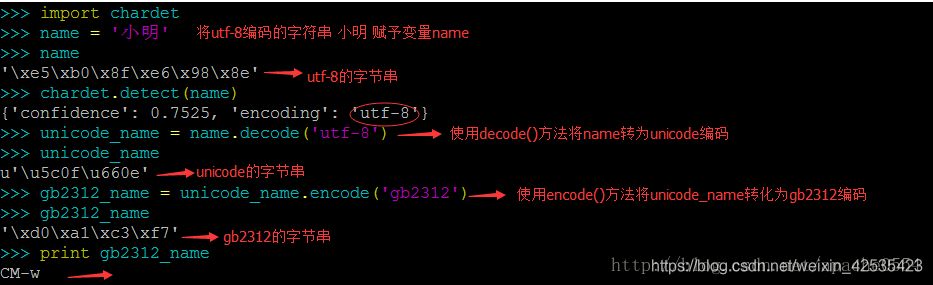
chardetモジュールは文字列のエンコーディングを検出します。もし持っていなければ、pip install chardetでインストールできます。
まず、なぜ name="Xiaoming" が Xiaoming なのかを説明します。 utf-8でエンコードされた文字 . Ubuntu 14.04 を使用しているため、デフォルトの文字エンコーディングは UTF-8 で、ターミナルに中国語を入力すると、その文字が は自動的にその中国語の文字をUTF-8エンコーディングでPythonに渡します。 . ですから、もしあなたのシステムがWindowsオペレーティングシステムで、ほとんどの場合Windowsのデフォルトのシステムエンコーディングがgb2312であれば、Windows環境での上記のテストにおける文字"小明"はgb2312エンコーディングになります。
上図では、utf-8でエンコードされた名前をdecode()メソッドでunicode_nameに変換し、unicode_nameをencode()メソッドでgb2312_nameに変換し、printでgb2312エンコード文字を出力していますが、おかしな出力になっていますね。これは、次のような理由によるものです。 私のOSはUTF-8エンコーディングなので、当然gb2312エンコーディングの文字は正しくパースできません。 gb2312のバイト列をwindowsに入れると、目的の中国語/strongを取得することができます。

いわゆる文字化けは、基本的にシステムのエンコーディングと提供された文字のエンコーディングの間に矛盾があるために起こるものですが、例を挙げてみましょう。
は、utf-8では1100001としてXiaomingのコンピュータに格納されています。
Xiaohongのコンピュータには、gb2312の文字Aも11000010として格納されています。
シャオミンとシャオホンが情報を交換する際、それぞれのコンピュータは相手から渡されたAをA文字と認識せず、B文字と勘違いする可能性があるのだそうです。
ですから、OSにある文字を正しく出力してもらうためには、その文字の文字コードを知ることに加えて、自分のシステムが使っている文字コードも知る必要があるのです。もし、システムがUTF-8エンコーディングを使っていても、gb2312文字を扱っていれば、いわゆる"garbled code"が発生することになるのです。
ヒント decode()メソッドは、例えばu'小明'のように文字列にuを追加するのと同じです。

要約すると
- Python2は文字エンコーディングの変換にunicodeを"middleman"として使用します。
- システムの文字エンコーディングを把握し(Linuxのデフォルトはutf-8、WindowsのデフォルトはGB2312)、それに従って処理すること。
IV. 文字コードの一例
Linux OSでpython2を使ってNetEaseのホームページのタイトルを取得し、正しい中国語で表示する。
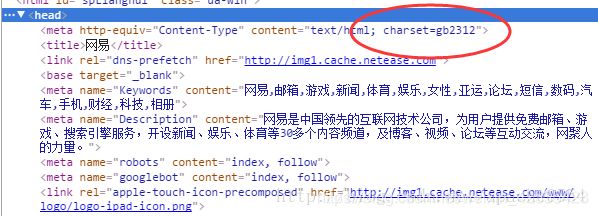
163のホームページは文字コードにgb2312を使用していますが、Linuxのデフォルトの文字コードはUTF-8であることは先に述べましたので、直接抽出した場合に文字化けの問題が発生しないかどうかをテストしてみましょう。

確かに抽出されたタイトルは、ページが文字コードとしてgb2312と宣言していたために正しく表示されないことがわかりました。一方、私のシステムのデフォルトの文字コードはUTF-8らしいので、タイトルをUTF-8に変換する必要がありました。
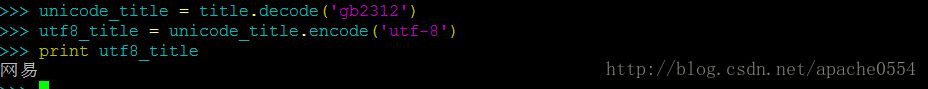
実は、utf-8はunicode文字コードに属するので、Linuxではunicodeでエンコードされた文字を直接プリントアウトすることができます。例えば
![]()
では、Windows上のPython2でもう一つ実験してみましょう。今度はBaiduのホームページのタイトルに切り替えてみます。
今回、Webページの文字コードがutf-8であることがわかったので、Windowsで文字化けするかというと、以下のようになります。
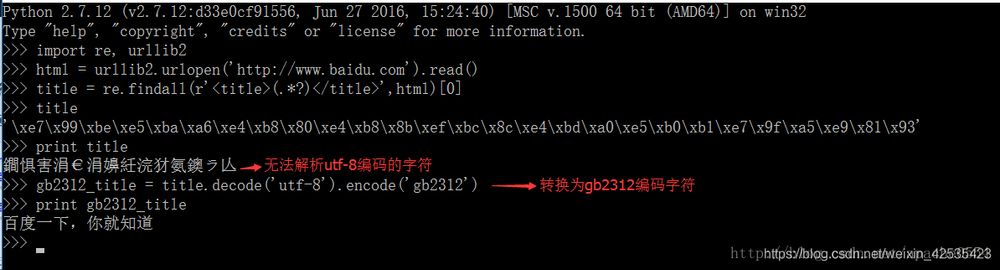
そこで、改めて強調するのは は、基本的にシステムのエンコーディングと提供された文字のエンコーディングの間に矛盾があるためです。
Pyhon3では、文字エンコーディングが大幅に改善されましたが、その中でも特に以下の点が改善されました。
- Python 3 の source.pyファイルのデフォルトのエンコーディングはUTF-8です。 ということで、Python3ではpyスクリプトにコーディング宣言を書く必要がなく、pythonに渡される文字はシステムのデフォルトエンコードの影響を受けなくなり、一律unicodeでエンコードされるようになりました。
- 文字列とバイト列を区別する Bytesは2.xのstrと似ていますが、エンコーディングにいろいろと違いがあります。bytesはデコードによってstrに変換され、strはエンコーディングによってbytesに変換されます。
追記:多くの初心者が悩む小さな問題がありますので、画像で見てみましょう
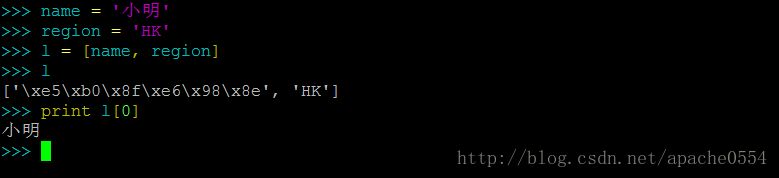
漢字がリスト(またはタプル、ディクト)の中に現れるとき、次のことがわかります。 は漢字としてではなく、バイト文字列として表示されます。 . しかし、リストから文字列を抽出して印刷すると、普通に中国語として表示される。バイト列は Python におけるすべての文字の "natural" 形式なので、次のことができます。 単に、リストで示されるバイト列は、コンピュータが見るためのものであることを意味します .
これはpython中国語エンコード文字化け問題の解決についてのこの記事の終わりです、より関連するpython中国語エンコード文字化けコンテンツはBinaryDevelopの過去の記事を検索してくださいまたは、次の関連記事を閲覧し続けるあなたが将来的にBinaryDevelopをよりサポートすることを願っています!
関連
-
[解決済み] numpy.random.multivariate_normal(mean, cov[, size]) を用いて複数サンプルを描画する。
-
[解決済み] Flaskアプリを実行しようとすると、"Address already in use "と表示される。
-
[解決済み] Python Quicksort Runtime Error: cmp で最大再帰深度を超えました。
-
[解決済み] ビジュアルインデントのため、継続行がアンダーインデントになっています」エラーが発生する
-
[解決済み] sdl2 - ImportError: DLL のロードに失敗しました。CRITICAL] [App] Window を取得できません、中止してください。
-
[解決済み] ImportError: dateutil.parserという名前のモジュールはありません。
-
[解決済み] Pythonで空のオブジェクトを作成する
-
[解決済み] Python3でモジュールに属性がないエラーが発生する
-
[解決済み] typeError: isinstance() arg 2 must be type or tuple of types >>.
-
[解決済み] パイソン 複数の関数を同時に実行する
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み】TypeError: 'float'オブジェクトは反復可能ではない
-
[解決済み] Pythonのラムダを複数行で記述する方法は?重複している] [重複している] [重複している] [重複している
-
レポート libc++abi.dylib: NSException 型の捕捉されない例外で終了する pycharm
-
[解決済み] ImportError: google.protobufという名前のモジュールはありません。
-
[解決済み] AttributeError: 'NoneType' オブジェクトには 'lower' 属性がない python
-
[解決済み] bs4.element.Tagから項目を取得する。
-
[解決済み] tensorflow:AttributeError: 'module' オブジェクトに 'mul' 属性がない。
-
[解決済み] 任意のデータを使って matplotlib で 4d プロットを作成する方法
-
pipのpythonバージョン10.1では、Could not install packages due to anEnvironmentErrorというエラーが発生します。[WinError 5] アクセスが拒否されました。
-
AttributeError module pandas has no attribute dataframe