[解決済み] Python 3.x の整数に対して、ビットシフトより速い Times-two?
質問
のソースを見ていたら ソート済みコンテナ を見て驚きました。 この行 :
self._load, self._twice, self._half = load, load * 2, load >> 1
ここで
load
は整数です。なぜあるところではビットシフトを使い、別のところでは乗算を使うのでしょうか?ビットシフトの方が2で割る積分より速いのは合理的だと思いますが、なぜ乗算もシフトに置き換えないのでしょうか?以下のようなケースでベンチマークをとってみました。
- (回、割算)
- (シフト、shift)
- (回、シフト)
- (シフト、ディバイド)
で、#3が他の選択肢より一貫して高速であることがわかりました。
# self._load, self._twice, self._half = load, load * 2, load >> 1
import random
import timeit
import pandas as pd
x = random.randint(10 ** 3, 10 ** 6)
def test_naive():
a, b, c = x, 2 * x, x // 2
def test_shift():
a, b, c = x, x << 1, x >> 1
def test_mixed():
a, b, c = x, x * 2, x >> 1
def test_mixed_swapped():
a, b, c = x, x << 1, x // 2
def observe(k):
print(k)
return {
'naive': timeit.timeit(test_naive),
'shift': timeit.timeit(test_shift),
'mixed': timeit.timeit(test_mixed),
'mixed_swapped': timeit.timeit(test_mixed_swapped),
}
def get_observations():
return pd.DataFrame([observe(k) for k in range(100)])
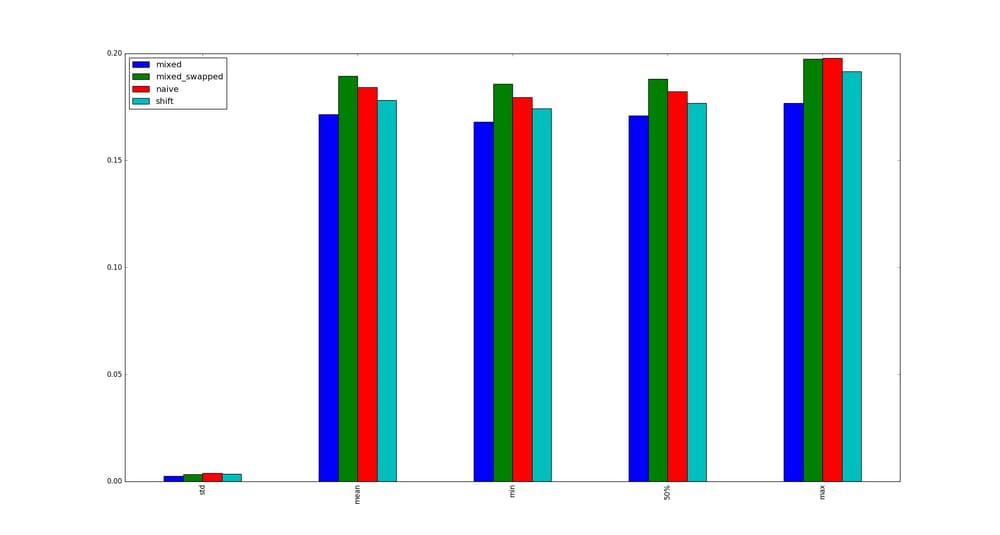
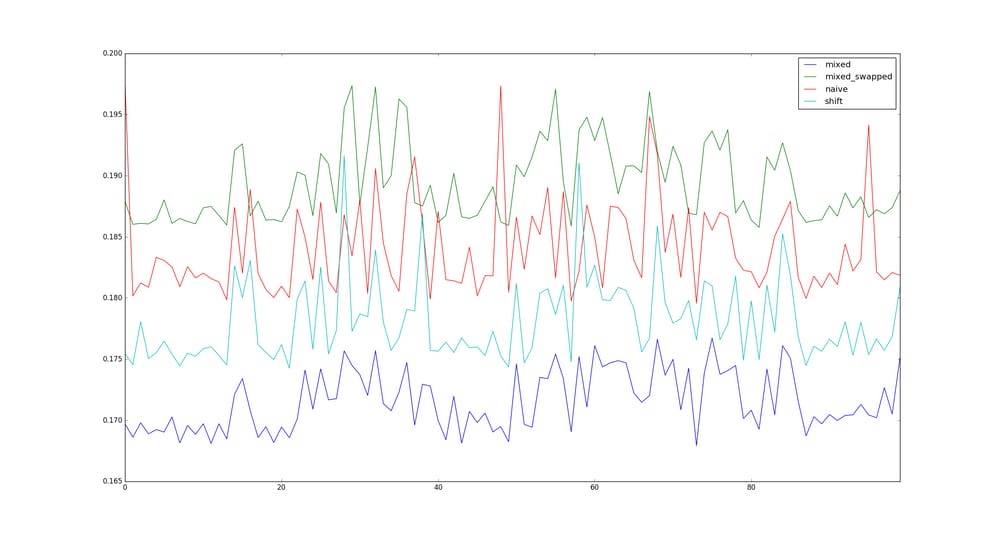
質問です。
私のテストは有効ですか?もしそうなら、なぜ (multiply, shift) は (shift, shift) よりも速いのでしょうか?
Ubuntu 14.04でPython 3.5を動かしています。
Edit
上記は質問文の原文です。Dan Getz氏が回答で素晴らしい説明をしています。
念のため、より大きなサイズのサンプルイラストを掲載します。
x
乗算の最適化が適用されない場合
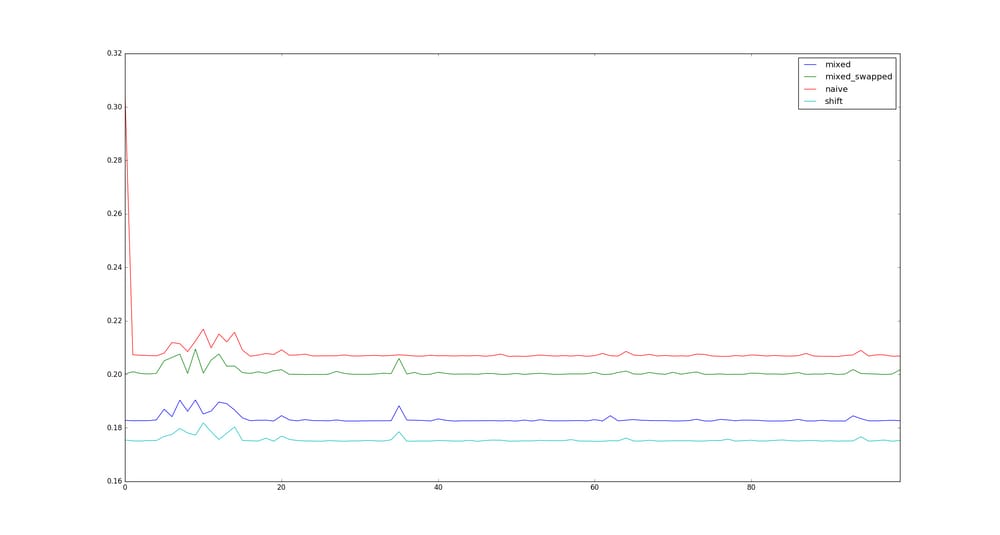
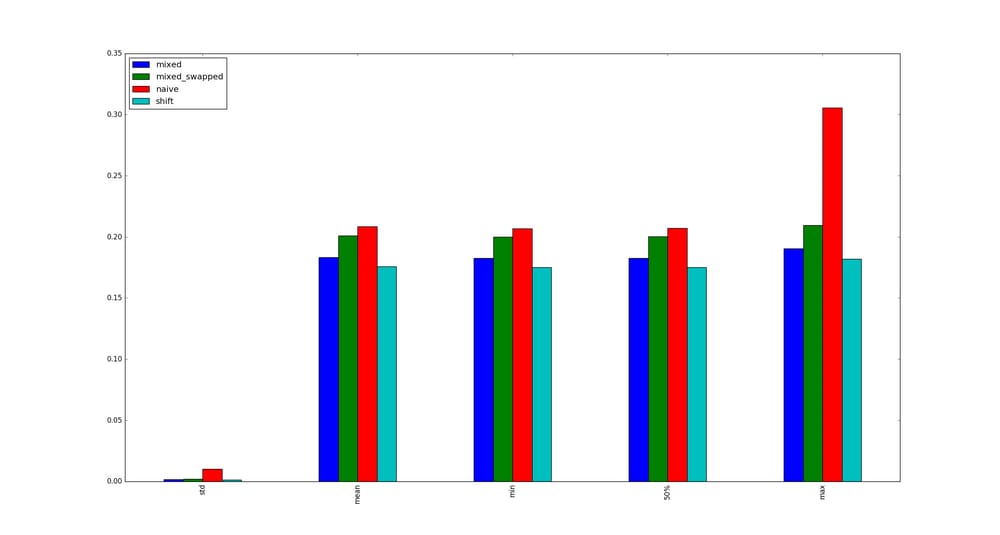
解決方法は?
これは、CPython 3.5では小さな数の掛け算が最適化され、小さな数による左シフトが最適化されないためと思われます。正の左シフトは常に計算の一部として結果を格納するために大きな整数オブジェクトを作成しますが、あなたがテストで使用した種類の乗算では、特別な最適化がこれを回避し、正しいサイズの整数オブジェクトを作成します。これは Pythonの整数型実装のソースコード .
Pythonの整数は任意精度のため、整数の "digits" の配列として保存され、整数の1桁あたりのビット数には制限があります。そのため、一般に整数を含む演算は単一演算ではなく、複数の "digits" がある場合を扱う必要があります。で
pyport.h
このビット制限
は次のように定義されています。
64ビットプラットフォームでは30ビット、それ以外では15ビット。(以下、説明を簡単にするために30ビットと呼ぶことにします)。しかし、もしあなたが32ビット用にコンパイルされたPythonを使用していた場合、ベンチマークの結果は
x
が32,768より小さいかどうか)
演算の入出力がこの30ビットの制限内に収まっていれば、一般的な方法ではなく、最適化された方法で演算を処理することができる。の冒頭は 整数乗算の実装 は次のとおりである。
static PyObject *
long_mul(PyLongObject *a, PyLongObject *b)
{
PyLongObject *z;
CHECK_BINOP(a, b);
/* fast path for single-digit multiplication */
if (Py_ABS(Py_SIZE(a)) <= 1 && Py_ABS(Py_SIZE(b)) <= 1) {
stwodigits v = (stwodigits)(MEDIUM_VALUE(a)) * MEDIUM_VALUE(b);
#ifdef HAVE_LONG_LONG
return PyLong_FromLongLong((PY_LONG_LONG)v);
#else
/* if we don't have long long then we're almost certainly
using 15-bit digits, so v will fit in a long. In the
unlikely event that we're using 30-bit digits on a platform
without long long, a large v will just cause us to fall
through to the general multiplication code below. */
if (v >= LONG_MIN && v <= LONG_MAX)
return PyLong_FromLong((long)v);
#endif
}
そのため、それぞれが30ビットの桁に収まる2つの整数を掛け合わせる場合、整数を配列として扱うのではなく、CPythonインタープリタによって直接掛け算として行われることになります。(
MEDIUM_VALUE()
を正の整数オブジェクトに対して呼び出すと、単純にその最初の30ビットの桁が取得されます)。結果が1つの30ビット桁に収まる場合は
PyLong_FromLongLong()
は比較的少ない操作でこれに気づき、1桁の整数オブジェクトを作成して保存します。
一方、左シフトはこのように最適化されておらず、左シフトのたびにシフトされる整数を配列として扱います。特に、以下のソースコードを見てください。
long_lshift()
小さいが正の左シフトの場合、2桁の整数オブジェクトが常に作成され、後でその長さが1に切り詰められる。
(での私のコメント
/*** ***/
)
static PyObject *
long_lshift(PyObject *v, PyObject *w)
{
/*** ... ***/
wordshift = shiftby / PyLong_SHIFT; /*** zero for small w ***/
remshift = shiftby - wordshift * PyLong_SHIFT; /*** w for small w ***/
oldsize = Py_ABS(Py_SIZE(a)); /*** 1 for small v > 0 ***/
newsize = oldsize + wordshift;
if (remshift)
++newsize; /*** here newsize becomes at least 2 for w > 0, v > 0 ***/
z = _PyLong_New(newsize);
/*** ... ***/
}
整数分割
整数の床分割が右シフトに比べてパフォーマンスが悪いというのは、あなたの(そして私の)予想に合っていたので、聞かれなかったのでしょう。しかし、小さな正の数を別の小さな正の数で割ることは、小さな乗算ほどには最適化されていません。すべての
//
は、商
と
という関数を使って余りを計算します。
long_divrem()
. この余りは,小さな約数に対して
乗算
であること、そして
は新しく割り当てられた整数オブジェクトに格納されます。
この場合、すぐに破棄される。
関連
-
Pythonの@decoratorsについてまとめてみました。
-
[解決済み] Pythonで2つのリストを連結する方法は?
-
[解決済み] 要素ごとの加算は、結合ループよりも分離ループの方がはるかに高速なのはなぜですか?
-
[解決済み] なぜC++はPythonよりもstdinからの行の読み込みが遅いのですか?
-
[解決済み] Pythonのswitch文の代用品?
-
[解決済み] <は<=より速いのか?
-
[解決済み] Collatz予想の検証を行うC++のコードは、なぜ手書きのアセンブリよりも高速に動作するのでしょうか?
-
[解決済み] なぜPythonのコードは関数の中でより速く実行されるのですか?
-
[解決済み] なぜ[]はlist()よりも速いのですか?
-
[解決済み】ビットシフト(bit-shift)演算子とは、どのようなもので、どのように機能するのですか?
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
ピロウズ画像色処理の具体的な活用方法
-
opencvとpillowを用いた顔認証システム(デモあり)
-
PythonはWordの読み書きの変更操作を実装している
-
python implement mysql add delete check change サンプルコード
-
Pythonの@decoratorsについてまとめてみました。
-
PythonでECDSAを実装する方法 知っていますか?
-
[解決済み】TypeError: re.findall()でバイトのようなオブジェクトに文字列パターンを使用することはできません。)
-
[解決済み】Python: OverflowError: 数学の範囲エラー
-
[解決済み】ValueError: pickleプロトコルがサポートされていません。3、python2 pickleはpython3 pickleでダンプしたファイルを読み込むことができない?
-
[解決済み】Flaskのテンプレートが見つからない【重複あり