pyfinanceパッケージによるPython株式所得分析
pyfinanceの紹介
datasets.py : 金融データのダウンロード(リクエストベースのデータクローラー、エクストラネットの制限によりダウンロードできなくなったデータもあります)。
general.py : アクティブシェア計算、リターン分布近似、トラッキングエラー最適化などの一般的な金融計算を行います。
ols.py: 回帰分析、pandasのローリングウィンドウ回帰をサポートします。
options.py: オプションデリバティブの計算と戦略分析。
returns.py: CAPMフレームワークによる金融時系列の統計分析。FactSet Research SystemsやZephyrなどのソフトウェアの機能を模倣し、スピードと柔軟性を向上させた設計になっています。
utils.py: インフラストラクチャ。

この記事では、株式投資分析におけるpyfinanceを紹介するreturnsモジュールを中心に、datasets、options、olsなどのモジュールについて紹介します。
リターンズモジュールの応用例
pyfinanceは比較的簡単にインストールでき、cmd(またはanacondaプロンプト)で "pip install pyfinance" と入力するだけです。 returnsは主にpandasと同等のTSeriesクラス(dataframeは未サポート)をベースとしています。 pandasのSeriesクラスを拡張してより高機能化し、証券投資分析におけるCAMP(資本資産価格モデル)フレームワークに基づいたパフォーマンス評価指標の算出をサポートするものと同義となります。returnsモジュールを参照する場合は、"from pyfinance import TSeries"を直接使用すればOKです。

データインタフェースとしてtushareを使用し、yieldデータをTSeriesに変換するデータフェッチ関数を定義し、TSeriesクラスの関数を直接使用します。
import pandas as pd
import numpy as np
from pyfinance import TSeries
import tushare as ts
def get_data(code,start='2011-01-01',end=''):
df=ts.get_k_data(code,start,end)
df.index=pd.to_datetime(df.date)
ret=df.close/df.close.shift(1)-1
# return TSeries sequence
return TSeries(ret.dropna())
# Get the Ping An of China data
tss=get_data('601318')
#tss.head()
歩留まり計算
pyfinanceのリターンは、年率リターン(anlzd_ret)、累積リターン(cuml_ret)、定期リターン(rollup)等を提供しています。ここでは、Ping An Bank株を例にして、イールドメトリクスを計算してみます。
#annualized return
anl_ret=tss.anlzd_ret()
#Cumulative return
cum_ret=tss.cuml_ret()
#Calculate the periodic rate of return
q_ret=tss.rollup('Q')
a_ret=tss.rollup('A')
print(f'Annualized return: {anl_ret*100:.2f}%')
print(f'Cumulative return: {cum_ret*100:.2f}%')
#print(f'Quarterly return: {q_ret.tail().round(4)}')
#print(f'Calendar year return: {a_ret.round(4)}')
出力結果です。
累積収益率:205.79パーセント
年率換算のリターン 12.24%
#Visualize quarterly (annual) returns
from pyecharts import Bar
attr=q_ret.index.strftime('%Y%m')
v1=(q_ret*100).round(2).values
bar=Bar('Ping An of China quarterly return %') bar.add('',attr,v1,)
bar
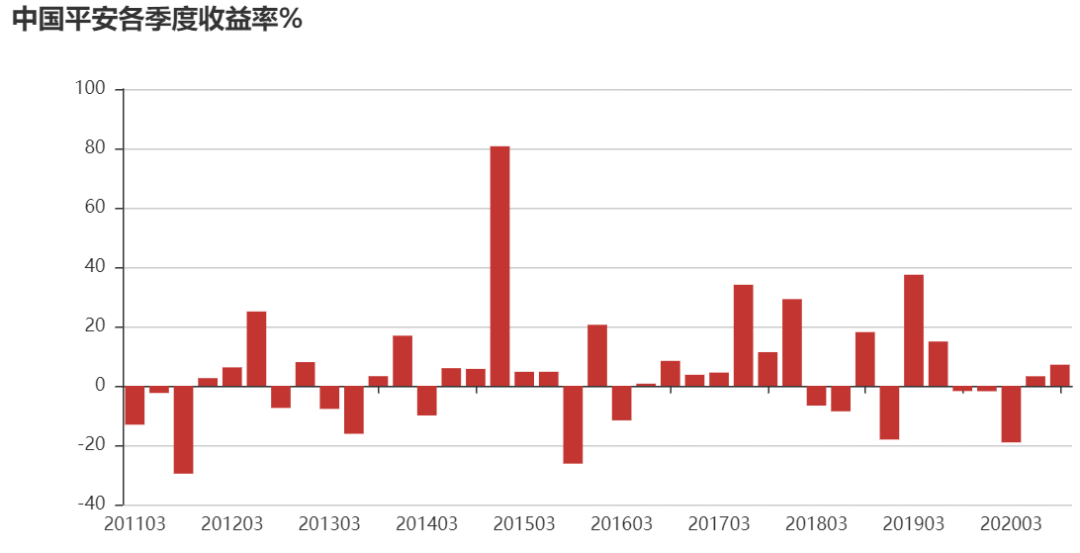
from pyecharts import Bar
attr=a_ret.index.strftime('%Y')
v1=(a_ret*100).round(2).values
bar=Bar('Ping An of China calendar year return %')
bar.add('',attr,v1,is_label_show=True,
is_splitline_show=False)
bar
CAPMモデル関連指標
CAPMモデルのα、β、回帰決定係数R2、t統計量、残差項を基に計算します。実際にはols回帰が主に使われているので、これらの動的なアルファ値やベータ値を得るには、さらにolsモジュールのローリング回帰関数(PandasRollingOLS)に頼りますが、その応用は次のツイートで説明します。
#Based on the CSI 300 index
#To ensure the length of both is the same, the index of Ping An of China is used as the benchmark
benchmark=get_data('hs300')
benchmark=benchmark.loc[tss.index]
alpha,beta,rsq=tss.alpha(benchmark),tss.beta(benchmark),tss.rsq(benchmark)
tstat_a,tstat_b=tss.tstat_alpha(benchmark),ttss.tstat_beta(benchmark)
print(f'alpha:{alpha:.4f},tstat: {tstat_a:.2f}')
print(f'beta :{beta:.4f}, t-statistic: {tstat_b:.2f}')
print(f'regression coefficient of determination R2: {tss.rsq(benchmark):.3f}')
alpha:0.0004, t-statistic:1.55。
ベータ値:1.0634、t統計量:60.09
回帰決定係数 R2: 0.606
リスク指標
リスク指標としては、主に標準偏差と最大リトレースメントがあります。標準偏差を計算する場合、pyfinanceのインストールパッケージがあるパスを開くか、Anacondaのインストールの場合、以下のパスに開いて、デフォルトのパラメータを変更する必要があることに注意してください。
c:\Anaconda3Libsite-packagespyfinance, open the returns source file, find anlzd_stdev and semi_stdev functions, and change the freq default None to 250 (the number of trading days in a year).
#annualized standard deviation
a_std=tss.anlzd_stdev()
#downstream standard deviation
s_std=tss.semi_stdev()
#max retracement
md=tss.max_drawdown()
print(f'Annualized standard deviation: {a_std*100:.2f}%')
print(f'downward bias standard deviation: {s_std*100:.2f}%')
print(f'Maximum retracement deviation: {md*100:.2f}%')
年率換算した標準偏差 31.37%
バイアス標準偏差を下げる。0.43%
最大リトレースメント偏差:-45.76%。
低スキューの標準偏差は、主にリターン分布の非対称性に対応するためのものです。リターン関数の分布が左スキューの場合、正規分布を用いるとリスクが過小評価されるため、推定にフルサンプルの標準偏差を用いた従来のシャープ比分母はあまり適切ではなく、リスクフリー投資リターンとの偏差を用いるべきとされています。
ベンチマーク比較指標
ベンチマーク比較指標は、中国平安社の個別銘柄を比較分析するためのベンチマークとして、CSI300指数などを指定するために必要です。
bat=tss.batting_avg(benchmark)
uc=tss.up_capture(benchmark)
dc=tss.down_capture(benchmark)
tc=uc/dc
pct_neg=tss.pct_negative()
pct_pos=tss.pct_positive()
print(f'Percentage of time above benchmark return: {bat*100:.2f}%')
print(f'Ratio of upward periods to benchmark returns: {uc*100:.2f}%')
print(f'Downside to benchmark return ratio: {dc*100:.2f}%')
print(f'Upside to Downside Ratio: {tc*100:.2f}%')
print(f'Individual stock downside (negative earnings) time ratio: {pct_neg*100:.2f}%')
print(f'Time share of individual stocks on the upside (positive returns): {pct_pos*100:.2f}%')
ベンチマークより高いリターンを得た時間の割合。47.83%
ベンチマークリターンに対する上昇期間の比率 111.70%
対ベンチマーク騰落率ダウンサイド期間:105.32%。
アップサイド期間とダウンサイド期間の比率。106.06%
個別銘柄のダウンサイド(マイナスリターン)期間比率:48.94%。
個別銘柄のアップサイド(プラスリターン)タイムシェア。50.00%
また、インフォメーション・レシオとトレイナー・インデックスは、特にファンド商品やポートフォリオのパフォーマンスを定量的に評価する際によく使われるベンチマーク比較評価指標である。
情報比率は、マーコウィッツの平均分散モデルに基づき、超過リスクによる超過リターンを測定し、アクティブリスク1単位あたりの超過リターンを表す。 ir = α ∕ ω(αはポートフォリオの超過リターン、ωはアクティブリスク)、分子αは真の期待リターンと価格モデルで計算したリターンの差、分子は残差項の標準偏差である残差リスクとする。
単位リスクあたりの超過リターンを示すトレイナー・レシオは、TR=(Rp-Rf)/βpで計算され、TRはトレイナー・パフォーマンス指数、Rpはポートフォリオの平均リターン、Rfは平均リスクフリーレート、βpはポートフォリオのシステマティックリスクです。
ir=tss.info_ratio(benchmark)
tr=tss.treynor_ratio(benchmark)
print(f'info ratio: {ir:.3f}')
print(f'Treynor index: {tr:.3f}')
情報量比率:0.433
トレイナー指数 0.096
リスク調整後リターン指標
リスク調整後リターン指標としては、シャープレシオ、ソルティーノレシオ、カルマルレシオがよく使われるが、いずれもリスク調整後リターン比率なので、分子はリターン指標、分母はリスク指標となる。
- シャープレシオ。リスク調整後リターン。= [E(Rp)-Rf]/σp で計算。E(Rp):ポートフォリオの期待ペイオフ、Rf:リスクフリーレート、σp:ポートフォリオの標準偏差。リスクの総量が1単位になるごとに、ポートフォリオがどれだけの超過利潤を生むかを計算する。
- ソルティーノ比(Sortino Ratio):シャープ比と同じ考え、コアは分母にあるダウンサイドボラティリティ(ダウンサイドリスク)の概念を適用し、標準偏差を計算するときに、平均を使用していませんが、設定した最小許容リターン(r_min)、戻り値のシリーズは、この最小リターンを超えるリターンの距離は0に従って計算されます、これ以下 この収量以下のリターンの2乗距離が標準偏差が半減となるように累積されています。これに対応して、ソルティーノレシオの分子も、ストラテジーリターンのうち、最小リターンを超える部分を使用する。シャープ比と比較して、ソルティーノ比は(左)テールの予想損失の分析をより重視し、シャープ比は全サンプルについて分析する。
- カルマー比(Calmar Ratio) :リターンと最大リトレースメントの関係を表し、年率リターンと過去の最大リトレースメントの比率として計算されます。カルマー比の値が大きいほど、ポートフォリオのパフォーマンスは良好です。
sr=tss.sharpe_ratio()
sor=tss.sortino_ratio(freq=250)
cr=tss.calmar_ratio()
print(f'Sharpe ratio: {sr:.2f}')
print(f'Sortino ratio: {sor:.2f}')
print(f'Karma ratio: {cr:.2f}')
シャープレシオ:0.33
ソルティーノレシオ:28.35
カルマ率:0.27
統合性能評価指標の分析例
以下は、上記の一般的に使用される指標を合成し、比較分析のために複数の個別銘柄にアクセスできるようにしたものです。
def performance(code,start='2011-01-01',end=''):
tss=get_data(code,start,end)
benchmark=get_data('hs300',start,end).loc[tss.index]
dd={}
#Returns
#annualized rate of return
dd['annualized_yield']=tss.anlzd_ret()
#Cumulative yield
dd['cumulative_ret']=tss.cuml_ret()
#alpha and beta
dd['alpha']=tss.alpha(benchmark)
dd['beta']=tss.beta(benchmark)
#risk metrics
#annualized standard deviation
dd['annualized standard deviation']=tss.anlzd_stdev()
#Downside standard deviation
dd['downside standard deviation']=tss.semi_stdev()
#Maximum retracement
dd['max_drawdown']=tss.max_drawdown()
#Information ratio and Traynor index
dd['info_ratio']=tss.info_ratio(benchmark)
dd['Treynor index']=tss.treynor_ratio(benchmark)
#Risk-adjusted return
dd['Sharpe ratio']=tss.sharpe_ratio()
dd['sortino_ratio']=tss.sortino_ratio(freq=250)
dd['calmar ratio']=tss.calmar_ratio()
df=pd.DataFrame(dd.values(),index=dd.keys()).round(4)
return df
複数銘柄のデータを取得し(ポートフォリオも構築)、比較することで性能評価指標を把握する。
#Get data for multiple stocks
df=pd.DataFrame(index=performance('601318').index)
stocks={'Ping An of China':'601318','Guizhou Maotai':'600519',\
'Haitian Flavor':'603288','Gree Electric':'000651',\
'Vanke A':'00002','BYD':'002594',\
'Yunnan Baiyao':'000538','Shuanghui Development':'000895',\
'Haier Zhijia':'600690','Tsingtao Beer':'600600'}
for name,code in stocks.items():
try:
df[name]=performance(code).values
except:
continue
d

まとめ
pyfinanceは、主にポートフォリオ投資管理およびパフォーマンス評価指標のために設計されたpythonパッケージで、CFAやFRMを受験する読者にとってかなり有用なものです。実際、pyfinanceのreturnsモジュールは、pandasのSeriesクラスを拡張し、ポートフォリオのリターン分析とパフォーマンス評価をサポートしています。この記事では、pyfinanceの"glue"言語について紹介します。この記事では、pyfinanceのreturnsモジュールの使い方に焦点を当て、他のモジュールについては以降のツイートで取り上げる予定です。
技術的な話
転載、ブックマーク、応援よろしくお願いします。

Pythonのpyfinanceパッケージを使って証券収益分析を行うという記事は以上です。Pythonのpyfinanceパッケージの詳細については、過去の記事を検索するか、以下の記事を引き続き閲覧してください。
関連
-
[解決済み】pytorchでmodel.eval()は何をするのですか?
-
[解決済み】入力配列を形状(3,1)から形状(3,)にブロードキャストできない。)
-
Pythonスクリプトフレームワークwebpyのurlマッピングの説明
-
[解決済み] Matplotlibです。"Unknown projection '3d'"エラー
-
[解決済み] S3からspark dataframe Pythonにparquetデータを読み込むには?
-
[解決済み] AttributeError: 'module' オブジェクト (scipy) には 'misc' 属性がありません。
-
[解決済み] sklearn classifier get ValueError: Bad input shape.
-
エラーです。/usr/bin/python3.6: '__main__' モジュールが '/home/user/object' に見当たりません。
-
urlエラーで最大再試行回数を超えました
-
Python OSError: [Errno 22] 無効な引数です。発生と解決
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み】AttributeError: 'Series'オブジェクトは'reshape'という属性を持っていない。
-
Python データ可視化 JupyterLab ユーティリティ拡張 Mito
-
モバイル・コンピュータゲーム向けPythonスクリプティング
-
[解決済み] Djangoです。フォームのメールフィールドは、アドレスがあっても 'this field cannot be null/this field cannot be blank' を返します。
-
[解決済み] TypeError: キャラクタバッファオブジェクトが必要です。
-
[解決済み] LEFT JOIN Django ORM
-
[解決済み] Pythonでvtkをstlに変換する方法は?
-
[解決済み] Pythonでazure SDKを使用できない
-
print を使用したエラー SyntaxError: print' の呼び出しに括弧がありません print("") のことですか?
-
Python:not supported between instances of 'NoneType' and 'int'