[解決済み] PyCharmとPySparkを連携させるには?
質問
私はapache sparkの初心者ですが、どうやらhomebrewでapache-sparkを私のmacbookにインストールしたようです。
Last login: Fri Jan 8 12:52:04 on console
user@MacBook-Pro-de-User-2:~$ pyspark
Python 2.7.10 (default, Jul 13 2015, 12:05:58)
[GCC 4.2.1 Compatible Apple LLVM 6.1.0 (clang-602.0.53)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
16/01/08 14:46:44 INFO SparkContext: Running Spark version 1.5.1
16/01/08 14:46:46 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
16/01/08 14:46:47 INFO SecurityManager: Changing view acls to: user
16/01/08 14:46:47 INFO SecurityManager: Changing modify acls to: user
16/01/08 14:46:47 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(user); users with modify permissions: Set(user)
16/01/08 14:46:50 INFO Slf4jLogger: Slf4jLogger started
16/01/08 14:46:50 INFO Remoting: Starting remoting
16/01/08 14:46:51 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://[email protected]:50199]
16/01/08 14:46:51 INFO Utils: Successfully started service 'sparkDriver' on port 50199.
16/01/08 14:46:51 INFO SparkEnv: Registering MapOutputTracker
16/01/08 14:46:51 INFO SparkEnv: Registering BlockManagerMaster
16/01/08 14:46:51 INFO DiskBlockManager: Created local directory at /private/var/folders/5x/k7n54drn1csc7w0j7vchjnmc0000gn/T/blockmgr-769e6f91-f0e7-49f9-b45d-1b6382637c95
16/01/08 14:46:51 INFO MemoryStore: MemoryStore started with capacity 530.0 MB
16/01/08 14:46:52 INFO HttpFileServer: HTTP File server directory is /private/var/folders/5x/k7n54drn1csc7w0j7vchjnmc0000gn/T/spark-8e4749ea-9ae7-4137-a0e1-52e410a8e4c5/httpd-1adcd424-c8e9-4e54-a45a-a735ade00393
16/01/08 14:46:52 INFO HttpServer: Starting HTTP Server
16/01/08 14:46:52 INFO Utils: Successfully started service 'HTTP file server' on port 50200.
16/01/08 14:46:52 INFO SparkEnv: Registering OutputCommitCoordinator
16/01/08 14:46:52 INFO Utils: Successfully started service 'SparkUI' on port 4040.
16/01/08 14:46:52 INFO SparkUI: Started SparkUI at http://192.168.1.64:4040
16/01/08 14:46:53 WARN MetricsSystem: Using default name DAGScheduler for source because spark.app.id is not set.
16/01/08 14:46:53 INFO Executor: Starting executor ID driver on host localhost
16/01/08 14:46:53 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 50201.
16/01/08 14:46:53 INFO NettyBlockTransferService: Server created on 50201
16/01/08 14:46:53 INFO BlockManagerMaster: Trying to register BlockManager
16/01/08 14:46:53 INFO BlockManagerMasterEndpoint: Registering block manager localhost:50201 with 530.0 MB RAM, BlockManagerId(driver, localhost, 50201)
16/01/08 14:46:53 INFO BlockManagerMaster: Registered BlockManager
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 1.5.1
/_/
Using Python version 2.7.10 (default, Jul 13 2015 12:05:58)
SparkContext available as sc, HiveContext available as sqlContext.
>>>
MLlibを使いこなすために,まずは遊んでみたいと思っています.しかし、私はPythonでスクリプトを書くためにPycharmを使用しています。問題は、Pycharmにアクセスしてpysparkを呼び出そうとすると、Pycharmがモジュールを見つけられないことです。以下のようにPycharmにパスを追加してみました。
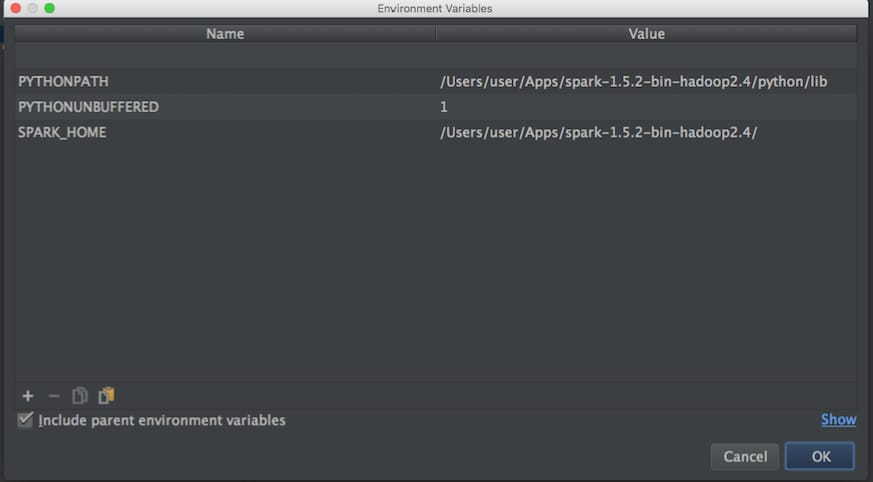
次に ブログ というのを試してみました。
import os
import sys
# Path for spark source folder
os.environ['SPARK_HOME']="/Users/user/Apps/spark-1.5.2-bin-hadoop2.4"
# Append pyspark to Python Path
sys.path.append("/Users/user/Apps/spark-1.5.2-bin-hadoop2.4/python/pyspark")
try:
from pyspark import SparkContext
from pyspark import SparkConf
print ("Successfully imported Spark Modules")
except ImportError as e:
print ("Can not import Spark Modules", e)
sys.exit(1)
PycharmでPySparkを使い始めることができないのですが、PyCharmとapache-pysparkを"link"する方法はありますか?
更新しました。
次に、Pycharmの環境変数を設定するために、apache-sparkとpython pathを検索します。
apache-sparkのパスを指定します。
user@MacBook-Pro-User-2:~$ brew info apache-spark
apache-spark: stable 1.6.0, HEAD
Engine for large-scale data processing
https://spark.apache.org/
/usr/local/Cellar/apache-spark/1.5.1 (649 files, 302.9M) *
Poured from bottle
From: https://github.com/Homebrew/homebrew/blob/master/Library/Formula/apache-spark.rb
pythonのパスです。
user@MacBook-Pro-User-2:~$ brew info python
python: stable 2.7.11 (bottled), HEAD
Interpreted, interactive, object-oriented programming language
https://www.python.org
/usr/local/Cellar/python/2.7.10_2 (4,965 files, 66.9M) *
そして、上記の内容で、以下のように環境変数を設定してみました。

Pycharmとpysparkを正しくリンクする方法について何か考えがありますか?
そして、上記の設定でpythonスクリプトを実行すると、このような例外が発生します。
/usr/local/Cellar/python/2.7.10_2/Frameworks/Python.framework/Versions/2.7/bin/python2.7 /Users/user/PycharmProjects/spark_examples/test_1.py
Traceback (most recent call last):
File "/Users/user/PycharmProjects/spark_examples/test_1.py", line 1, in <module>
from pyspark import SparkContext
ImportError: No module named pyspark
UPDATEです。 そこで、@zero323 さんの提案された以下の構成を試してみました。
構成1:
/usr/local/Cellar/apache-spark/1.5.1/

を出力します。
user@MacBook-Pro-de-User-2:/usr/local/Cellar/apache-spark/1.5.1$ ls
CHANGES.txt NOTICE libexec/
INSTALL_RECEIPT.json README.md
LICENSE bin/
構成2:
/usr/local/Cellar/apache-spark/1.5.1/libexec

を出力します。
user@MacBook-Pro-de-User-2:/usr/local/Cellar/apache-spark/1.5.1/libexec$ ls
R/ bin/ data/ examples/ python/
RELEASE conf/ ec2/ lib/ sbin/
どのように解決するのですか?
PySparkパッケージ(Spark 2.2.0以降)を使用する場合
と
SPARK-1267
がマージされることで、プロセスを簡略化できるはずです。
pip
Spark を PyCharm の開発に使っている環境にインストールすることで、プロセスを簡略化できるはずです。
- に移動します。 ファイル -> 設定 -> プロジェクト・インタープリター
-
インストールボタンをクリックし、PySparkを検索します。
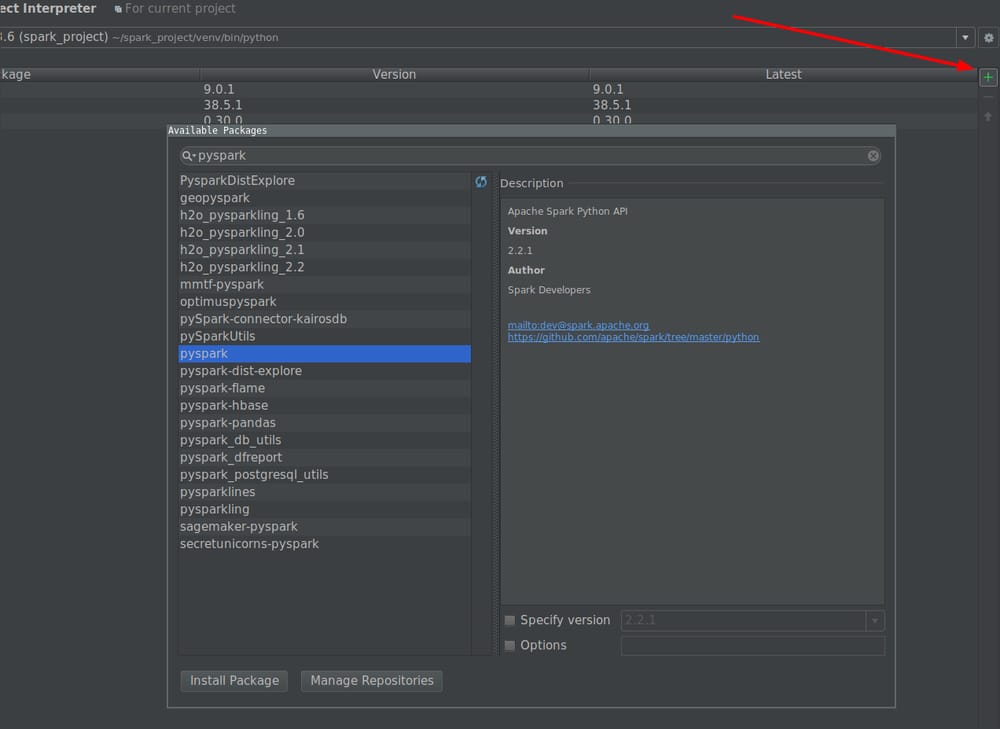
-
パッケージのインストールボタンをクリックします。
ユーザーが提供するSparkのインストールを手動で行う
実行設定の作成 :
- に移動します。 実行 -> 設定編集
- 新しいPythonの設定を追加する
- 設定 スクリプト のパスを設定し、実行したいスクリプトを指すようにします。
-
編集 環境変数 フィールドが少なくとも含まれるようにします。
-
SPARK_HOME- は、Sparkがインストールされているディレクトリを指している必要があります。このディレクトリには、次のようなディレクトリが含まれている必要があります。bin(ただしspark-submit,spark-shellなど)とconf(を含むspark-defaults.conf,spark-env.shなど) -
PYTHONPATH- を含む必要があります。$SPARK_HOME/pythonそして、オプションで$SPARK_HOME/python/lib/py4j-some-version.src.zipを使用することができます。some-versionは、指定されたSparkのインストールで使用されるPy4Jのバージョンに合わせる必要があります (0.8.2.1 - 1.5, 0.9 - 1.6, 0.10.3 - 2.0, 0.10.4 - 2.1, 0.10.4 - 2.2, 0.10.6 - 2.3, 0.10.7 - 2.4) 。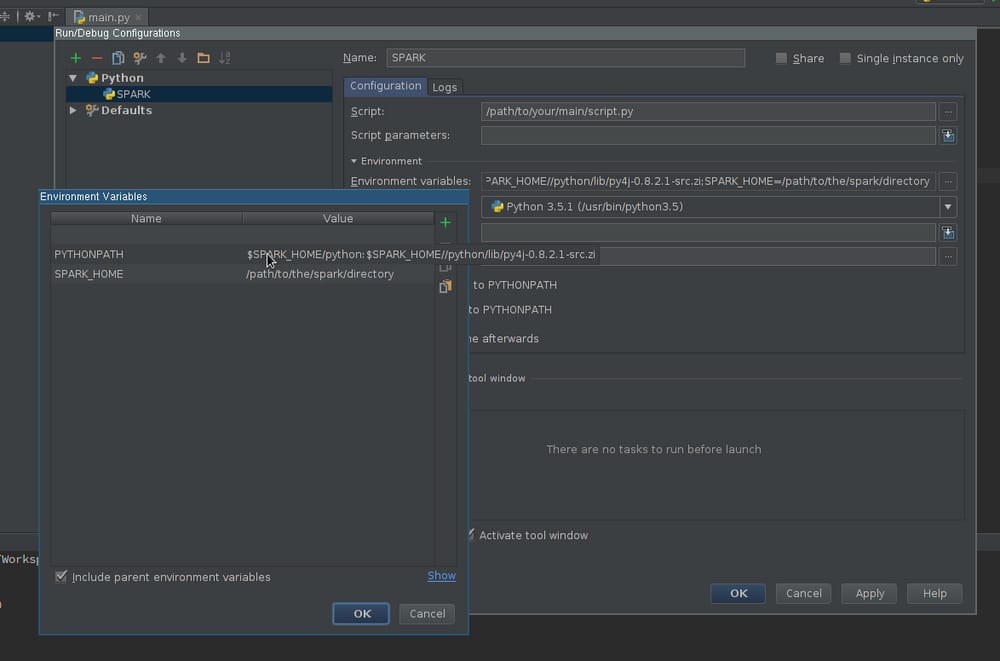
-
-
設定を適用する
インタプリタのパスにPySparkライブラリを追加する(コード補完に必須) :
- に移動します。 ファイル -> 設定 -> プロジェクト・インタープリター
- Sparkで使用したいインタプリタの設定を開く
-
インタープリターのパスを編集し、そのパスに
$SPARK_HOME/python(必要であればPy4Jも) - 設定の保存
オプションで
- インストールまたはパスへの追加 タイプのアノテーション は、より良い補完と静的エラー検出を得るためにインストールされたSparkのバージョンと一致します(免責事項 - 私はこのプロジェクトの著者です)。
最後に
新しく作成した設定を使って、スクリプトを実行します。
関連
-
[解決済み] プログラムの実行やシステムコマンドの呼び出しはどのように行うのですか?
-
[解決済み] リストのリストからフラットなリストを作るには?
-
[解決済み] リストが空かどうかを確認するにはどうすればよいですか?
-
[解決済み] pipでPythonの全パッケージをアップグレードする方法
-
[解決済み】ネストされたディレクトリを安全に作成するには?
-
[解決済み】2つの辞書を1つの式でマージする(辞書の和をとる)には?)
-
[解決済み] Jupyterノートブックでenv変数を設定する方法
-
[解決済み] django.db.migrations.exceptions.InconsistentMigrationHistory
-
[解決済み] Pythonの要素別タプル演算(sumなど
-
[解決済み] Alembicアップグレードスクリプトでインサートやアップデートを実行するにはどうすればよいですか?
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み] Pandasのデータフレームでタプルの列を分割するにはどうしたらいいですか?
-
[解決済み] なぜ(0-6)は-6=偽なのか?重複
-
[解決済み] Python 2.7サポート終了?
-
[解決済み] pandasのタイムゾーンに対応したDateTimeIndexを、特定のタイムゾーンに対応したナイーブなタイムスタンプに変換する。
-
[解決済み] Pythonでマルチプロセッシングキューを使うには?
-
[解決済み] djangoフレームワークでフォームフィールドから値を取得するには?
-
[解決済み] virtualenv の `--no-site-packages` オプションを元に戻す。
-
[解決済み] PySparkでデータフレームのカラムをString型からDouble型に変更する方法は?
-
[解決済み] PythonのRequestsモジュールを使ってWebサイトに "ログイン "するには?
-
[解決済み] 認証プラグイン 'caching_sha2_password' はサポートされていません。