predict_proba, predict, decision_function の scikit-learn toolkit での使用法。
sklearnで分類モデルを学習したら、次はモデルの予測値を検証することになります。分類モデルの場合、sklearn は通常 predict_proba, predict, decision_function の3つのメソッドを提供し、入力サンプルに対するモデルの判定を示します。
例として、sklearn では、学習済みの分類モデルに対して、学習サンプルのクラストークンを順番に保持する classes_ 属性を持ちます。ここでは、ロジスティック回帰分類器を用いて、分類器のclasses_属性を表示する例を示します。
1. まず、サンプルラベルが0から始まるシナリオの分類モデルの学習について見てみましょう。
import numpy as np
from sklearn.linear_model import LogisticRegression
x = np.array(
[
[-1, -1],
[-2, -1],
[1, 1],
[2, 1],
[-1, 1],
[-1, 2],
[1, -1],
[1, -2]
]
)
y = np.array([2, 2, 3, 3, 0, 0, 1, 1])
clf = LogisticRegression()
clf.fit(x, y)
print(clf.classes_)
"""
Output result: [0 1 2 3]
"""
2. ここでは、サンプルのラベルが0から始まらないシナリオでの分類モデルの学習について見てみましょう。
import numpy as np
from sklearn.linear_model import LogisticRegression
x = np.array(
[
[-1, -1],
[-2, -1],
[1, 1],
[2, 1],
[-1, 1],
[-1, 2],
[1, -1],
[1, -2]
]
)
y = np.array([6, 6, 2, 2, 4, 4, 8, 8])
clf = LogisticRegression()
clf.fit(x, y)
print(clf.classes_)
"""
Output result: [2 4 6 8]
"""
なお、上の2つの場合のclasses_propertyの出力の順番は、この後のpredict_proba, predict, decision_functionの出力の順番またはその組み合わせに対応する。
分類モデルclasses_のラベルの順番を理解した上で、分類モデルpredict_proba、predict、decision_functionの3つの関数の出力の意味と、それぞれの相関を見ていきましょう。
1. predict_proba: このモデルは、入力サンプルが各カテゴリに属する確率を確率和1で予測します。各位置の確率は、classes_の対応する位置のカテゴリラベルに対応します。上のカテゴリラベルが [2 4 6 8] である分類器を例にとり,分類モデルによって予測される確率を見ます.

入力 [-1, -1] は分類器の学習に使われるデータであり,学習データ [-1, -1] はクラス 6 に属します.predict_proba の出力確率において,確率の最大値は3番目の位置にあり,3番目の位置に対応する classes_ category も class 6 になっています.つまり、predict_probaの出力確率の最大値 インデックスの位置に対応するclass_要素が、サンプルの属するカテゴリであることがわかります。ここで、predictの予測結果とpredict_probaの予測結果が一致しているかどうかを見てみましょう。
2.予測する。 入力サンプルが属するカテゴリを予測し、カテゴリに属する場合は1を、属さない場合は0を出力するモデル。
前のステップで、predict_probaはサンプルが各カテゴリーに属する確率であり、最も高い確率を持つカテゴリーがサンプルの予測結果として使われることを学びました。

predictの予測結果はクラス6で、これはclass_の3番目の要素に対応し、またpredict_probaの3番目の要素で最も高い確率値に対応するものです。
分類モデルの場合、通常はモデルpredictの予測結果と予測確率predict_probaが分かれば十分ですが、分類モデル中のdecision_functionは何をしているのでしょうか。
3.decision_function。 ヘルプには、「あるサンプルの信頼度は、超平面に対するそのサンプルの符号付き距離である」と説明されています。これは、あるサンプルの信頼スコアは、超平面に対するそのサンプルの符号付き距離であることを意味します。トリックを拡大する、魂の3つの質問。彼は誰ですか?彼はどこから来たのか?彼はどこへ行くのか?
彼は誰ですか?
サポートベクターマシンSVMのdecision_functionの説明がどのようなものか見てみましょう。

評価サンプルXのdecision_function(これは言っていないのと同じです、ハハハ)と、もう一つは、decision_dunction_shape='ovr'の場合、出力のdecision_functionの形状は(n_samples、n_classes)、n_ samplesは入力サンプル数、n_classesは学習サンプルのクラス数です、と言われていることです。ここでもう一点、decision_dunction_shape='ovrとすると、出力decison_functionの形状は(n_samples, n_classes * (n_classes - 1) / 2)となることを付け加えます。ovr'と'ovo'ってなんでしたっけ?急がない、急がない。とりあえず、多階級化の訓練に使われることだけは知っておいてください。
大雑把に言うと、decison_functionは予測対象のサンプルから分類モデルの分離超平面のそれぞれまでの距離を表す指標です(直感的な説明方法が見つかりませんでした)。
どこから来たんだ?
この人は遠いSVMの星から来たと言われています。こいつは分離超平面に関係することができると書いてあります。SVMに詳しい方はご存知だと思いますが、SVMでは分離超平面はサポートベクトルによって選ばれ、分離超平面は学習サンプルを正と負に分け、サポートベクトルによって分離超平面が両方のクラスから遠く離れて選ばれるようになり、モデルの頑健性が高くなるのだそうです。
どこに行くんだ?
これだけ言われても、このdecison_functionというのは何をするものなのでしょうか?急がない、急がない。前出の'ovr'と'ovo'が何なのかを説明します。
SVMも同じで、前述のように超平面を分離することでサンプルを2面に分ける、つまり2値分類を行います。SVMも同様です。では、2値分類のアルゴリズムを多値分類のタスクに適用するにはどうすればよいのでしょうか。これが'ovr'と'ovo'が解決しようとしている問題です.
'ovr':正式名称はOne-vs-Restです。 一人の人間と、その反対側の集団が一戦交える(クラスターファック)のです。学習データに[0, 1, 2, 3]の4つのカテゴリがあるとすると、0, 1, 2, 3を正のサンプル、123, 023, 013, 012を負のサンプルとして4つの分類器を学習し、各分類器は0, 1, 2, 3という対応する正のクラスに属する確率を予測する。これは,1つの入力サンプルに対して4つの2値分類を行い,class_classに対応する出力のうち最も大きな値をとることに相当します.
ovo」:正式名称は「One-vs-One」です。 一人が反対側の人と一回ずつ別々に戦うことです(一対一、輪タク)。同様に、[0, 1, 2, 3]の4つのカテゴリでデータを学習する場合、カテゴリ0を陽性サンプル、カテゴリ1、カテゴリ2、カテゴリ3を陰性サンプルとして3つの分類器を学習し、カテゴリ1を陽性サンプル、カテゴリ0、カテゴリ2、カテゴリ3を陰性サンプルとして3つの分類器、、、というように学習する。カテゴリ0が正のサンプル、カテゴリ1が負のサンプル、カテゴリ1が正のサンプル、カテゴリ0が負のサンプルは本質的に同じなので、学習を繰り返す必要はない。
上記の説明から、学習サンプルがn_クラスある場合、「ovr」モデルはn_クラスの分類器を学習する必要があり、「ovo」モデルはn_クラス* (n_classes - 1) / 2の分類器を学習する必要があることがわかります。ここで,いくつの分離超平面を持つためにいくつの分類器が必要か,いくつの決定関数の値を持つためにいくつの分離超平面が必要か,という疑問が生じます.これは、"who is he?"の部分に相当します。 decision_functionの出力の形状を記述するセクションです。
本題に入り、decision_functionの実態を見てみましょう。
1. 二項対立型decison_function
2値分類モデルでは、decision_functionが返す配列の形状はサンプル数に等しく、つまり1サンプルで1つのdecision_functionの値が返されます。そして,この時点で decision_function_shape パラメータは失敗します.なぜなら,学習させるべき分類器は1つだけなので,ワンショットなのかグループショットなのかは問われないからです.ここで、SVMによる2値化分類の例で結果を確認しましょう。
import numpy as np
from sklearn.svm import SVC
x = np.array([[1,2,3],
[1,3,4],
[2,1,2],
[4,5,6],
[3,5,3],
[1,7,2]])
y = np.array([3, 3, 3, 2, 2, 2])
clf = SVC(probability=True)
clf.fit(x, y)
print(clf.decision_function(x))
# return array([2, 3]), where 2 is negetive and 3 is positive
print(clf.classes_)
二値分類の場合、分類モデルのdecision_functionが返す結果の形状はサンプル数と同じで、返す結果の値は、そのサンプルがPOSITIVE正サンプルであるとモデルが予測する信頼度を示しています。また、その 二項対立の場合のclass_の最初のラベルは陰性サンプルを、2番目のラベルは陽性サンプルを表しています。
学習セットに対するモデルのdecision_functionとpredict_procaba, predictの結果は以下の通りです。
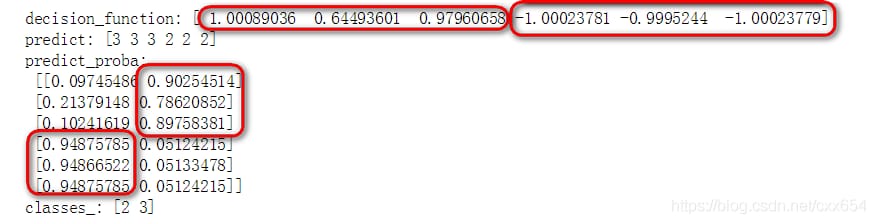
decision_functionは符号付きであることを思い出してください。0より大きいということは、正のサンプルは負のサンプルより信頼性が高く、そうでない場合は負のサンプルより信頼性が低いことを意味します。つまり、最初の3つのサンプルについては、decision_functionは正のサンプルの信頼度が高いとみなし、最後の3つのサンプルは負のサンプルの信頼度が高いとみなします。次にもう一度predictの結果を見てみると、最初の3つの予測は正のサンプル3( ps: 二項対立の場合の正のサンプルは、classes_の2番目のカテゴリに対応します。 predict_probaが予測するサンプルが属するカテゴリの確率を見ると、最初の3つのサンプルはカテゴリ3に属する確率が高く、最後の3つのサンプルはカテゴリ2に属する確率が高いことがわかります。
2. マルチカテゴリ判定機能
マルチクラスモデルでは、decision_functionが返す配列の形状は、使用するパターンが「ovr」か「ovo」かに応じて、それぞれn_classesとn_classes * (n_classes - 1) / 2の値を返す。 classes - 1) / 2の値を返す。ここで、SVMによる多階級化の例で結果を見てみましょう。
一対一の多階級化の例。
import matplotlib.pyplot as plt
import numpy as np
from sklearn.svm import SVC
X = np.array(
[
[-1, -1],
[-2, -1],
[1, 1],
[2, 1],
[-1, 1],
[-1, 2],
[1, -1],
[1, -2]
]
)
y = np.array([2, 2, 3, 3, 0, 0, 1, 1])
# SVC multi-classification model uses ovr mode by default
clf = SVC(probability=True, decision_function_shape="ovr")
clf.fit(x, y)
# Calculate the distance of the sample from each classification boundary
# One-vs-One determines the classification result of each classifier according to the decision_function scores [01, 02, 03, 12, 13, 23], and then votes
# One-vs-Rest selects the classification result with the largest score [0-Rest, 1-Rest, 2-Rest, 3-Rest] for decision_function
print("decision_function:\n", clf.decision_function(X))
# precidt predict the category of labels corresponding to the samples
print("predict:\n", clf.predict(X))
# predict_proba predicts the probability that the sample corresponds to each category
print("predict_proba:\n", clf.predict_proba(X)) # This is the score, the score of each classifier, take the class corresponding to the maximum score.
print("classes_:", clf.classes_)
学習セットに対するモデルのdecision_functionとpredict_procaba, predictの結果は以下の通りです。
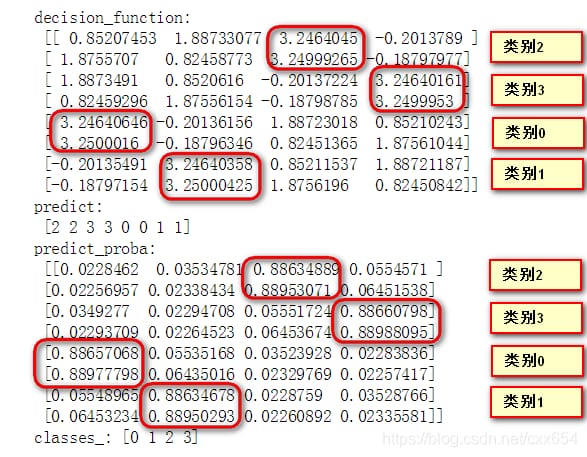
ovrシナリオでは、decision_function出力の最大値に対応する正のサンプルカテゴリが、decision_functionが最も信頼度が高いと見なす予測カテゴリとなります。ここで、One-vs-Oneシナリオでのマルチカテゴリー化を見てみましょう。
1対1の多階級化の例。
import matplotlib.pyplot as plt
import numpy as np
from sklearn.svm import SVC
X = np.array(
[
[-1, -1],
[-2, -1],
[1, 1],
[2, 1],
[-1, 1],
[-1, 2],
[1, -1],
[1, -2]
]
)
y = np.array([2, 2, 3, 3, 0, 0, 1, 1])
# SVC multi-classification model uses ovr mode by default
clf = SVC(probability=True, decision_function_shape="ovo")
clf.fit(x, y)
# Calculate the distance of the sample from each classification boundary
# One-vs-One determines the classification result of each classifier according to the scores of decision_function [01, 02, 03, 12, 13, 23], and then votes
# One-vs-Rest selects the classification result with the largest score [0-Rest, 1-Rest, 2-Rest, 3-Rest] for decision_function
print("decision_function:\n", clf.decision_function(X))
# precidt predict the category of labels corresponding to the samples
print("predict:\n", clf.predict(X))
# predict_proba predicts the probability that the sample corresponds to each category
print("predict_proba:\n", clf.predict_proba(X)) # This is the score, the score of each classifier, take the class corresponding to the maximum score.
print("classes_:", clf.classes_)
学習セットに対するモデルのdecision_functionとpredict_procaba, predictの結果は以下の通りです。
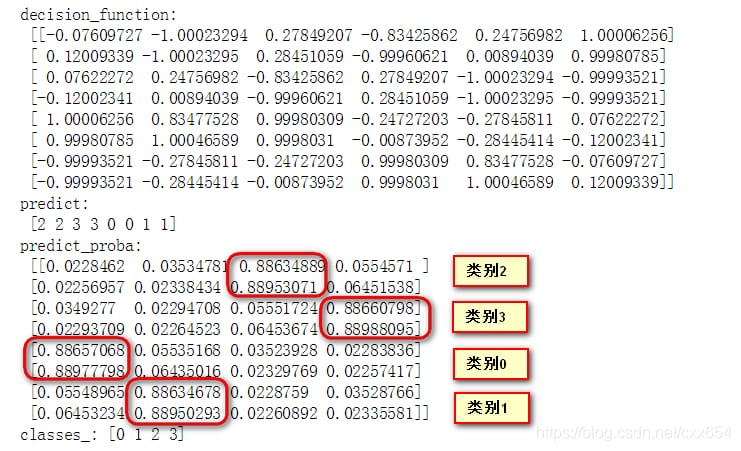
ovoモードでは、4クラスの学習データで、6つのdecision_functionの値を得るために6つの二項対立型分類器を学習する必要があります。classes_ のクラス順序に従って、6つの2値分類器は [01, 02, 03, 12, 13, 23] となり、最初の数字は正のクラスを、最後の数字は負のクラスを表します。decision_functionの出力の1行目を例にとります。
-0.07609727 corresponds to the 01 classifier, and the value is less than 0, then the classification result is the latter, i.e. category 1
-1.00023294 corresponds to the 02 classifier, and the value is less than 0, then the classification result is the latter, i.e. category 2
0.27849207 corresponds to the 03 classifier, and the value is greater than 0, then the classification result is the former, i.e. category 0
-0.834258626 corresponds to 12 classifiers and the value is less than 0, then the classification result is the latter, i.e. category 2
0.24756982 corresponds to 13 classifiers and the value is greater than 0, then the classification result is the former, i.e. category 1
1.00006256 corresponds to 23 classifiers, and the value is greater than 0, then the classification result is the former, i.e., category 2
Final number of votes: {category 0: 1, category 1: 2, category 2: 3, category 3: 0}
Voting on the above classification result, the majority wins, i.e. the final classification result is category 2.
decision_function、predict_procaba、predictのつながりは、おそらく上記から導き出されるものでしょう。
decision_function: 各分類器の分離超平面からの出力サンプルの信頼度,そこからpredictの予測値が推論されます.
predict_procaba: サンプルが各クラスに属する確率を出力し、それによってpredictの予測値を推論することができる。
predict: サンプルが特定のカテゴリに属するかどうかの予測値を出力します。
どのように機能するのですか?
ここまで言って、decision_function の意味を正確に理解した上で、decision_function を使って何ができるのでしょうか?(うまくいきませんね)。
SVM分類器では、予測したサンプルの確率値を出力するかどうかを制御するパラメータがproba関数にあり、サンプル予測結果の信頼度(単純に確率と理解してください)を得る方法がありません。しかしその後,分類器の性能を計算したいときには,しばしば ROC や AUC を用いる必要があることが分かっています.ROC曲線は分類器の予測結果のFPRとTPRの傾向を示し,AUCはROC曲線より下の面積を示す.つまり,ROC と AUC を求めるためには,FPR と TPR のセットを得ることが必要である.FPRとTPRの計算は通常、一組のサンプルの予測信頼度に基づいて行われ、異なる信頼度閾値を選択してそれぞれ一組のFPRとTPR値を取得し、ROCカーブを得る。しかし、先ほどdecision_functionの説明の際に述べたことを思い出してください。decision_functionは超平面から分離したサンプル間の距離を計測して信頼度を表しています。では、decision_functionの信頼度を用いてROCを計算することはできるのでしょうか。もちろん、答えはYESです。
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
from sklearn.svm import SVC
from sklearn.metrics import roc_curve, roc_auc_score, auc, plot_roc_curve
from sklearn.multiclass import OneVsOneClassifier, OneVsRestClassifier
from sklearn.preprocessing import label_binarize
from sklearn import datasets
from sklearn.model_selection import train_test_split
np.random.seed(100)
# Load iris datasets
iris = datasets.load_iris()
X = iris.data
y = iris.target
print(X.shape, y.shape)
n_samples, n_features = X.shape
# iris dataset adds noise, making the ROC not so perfect
X = np.c_[X, np.random.randn(n_samples, 50 * n_features)]
# y = label_binarize(y, classes=[0, 1, 2])
# n_classes = y.shape[1]
# Number of classes for training samples
n_classes = 3
# Divide the training set and test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.5, random_state=0)
print(X_train.shape, y_train.shape)
print(X_test.shape, y_test.shape)
# Train SVM classifier using One-vs-Rest model
clf = OneVsRestClassifier(SVC(kernel="linear"))
clf.fit(x_train, y_train)
# Calculate the decision value of the classifier on the test set
y_scores = clf.decision_function(X_test)
print(y_scores.shape)
# Plot the ROC curve for each category
fig, axes = plt.subplots(2, 2, figsize=(8, 8))
colors = ["r", "g", "b", "k"]
markers = ["o", "^", "v", "+"]
y_test = label_binarize(y_test, classes=clf.classes_)
for i in range(n_classes):
# Calculate FPR, TPR for each class
fpr, tpr, thr = roc_curve(y_test[:, i], y_scores[:, i])
# print("classes_{}, fpr: {}, tpr: {}, threshold: {}".format(i, fpr, tpr, thr))
# Plot the ROC curve and calculate the AUC value
axes[int(i / 2), i % 2].plot(fpr, tpr, color=colors[i], marker=markers[i], label="AUC: {:.2f}".format(auc(fpr, tpr)))
axes[int(i / 2), i % 2].set_xlabel("FPR")
axes[int(i / 2), i % 2].set_ylabel("TPR")
axes[int(i / 2), i % 2].set_title("Class_{}".format(clf.classes_[i]))
axes[int(i / 2), i % 2].legend(loc="lower right")
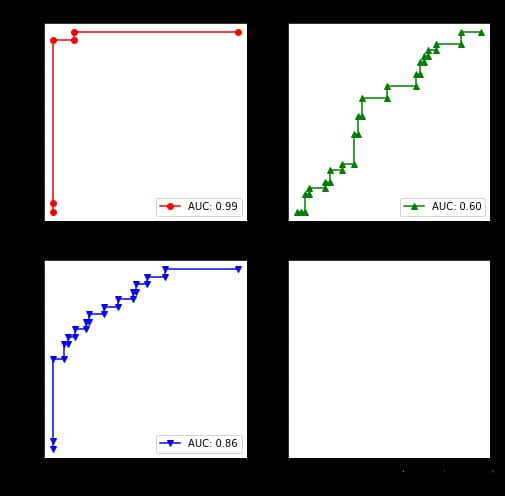
print("AUC:", roc_auc_score(y_test, clf.decision_function(X_test), multi_class="ovr", average=None))
出力は以下の通りです。AUCです。[0.99470899 0.5962963 0.8619281 ]
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
ハートビート・エフェクトのためのHTML+CSS
-
HTML ホテル フォームによるフィルタリング
-
HTML+cssのボックスモデル例(円、半円など)「border-radius」使いやすい
-
HTMLテーブルのテーブル分割とマージ(colspan, rowspan)
-
ランダム・ネームドロッパーを実装するためのhtmlサンプルコード
-
Html階層型ボックスシャドウ効果サンプルコード
-
QQの一時的なダイアログボックスをポップアップし、友人を追加せずにオンラインで話す効果を達成する方法
-
sublime / vscodeショートカットHTMLコード生成の実装
-
HTMLページを縮小した後にスクロールバーを表示するサンプルコード
-
html のリストボックス、テキストフィールド、ファイルフィールドのコード例