[解決済み] pandasのforループは本当にダメなのか?どのような場合に気をつけるべきですか?
質問
あなたは
for
ループは本当に悪いのでしょうか?もしそうでないなら、どのような状況で、より従来型の "ベクトル化された" アプローチを使うよりも良いのでしょうか?
1
私はベクトル化の概念と、pandasがベクトル化技術を使用して計算を高速化する方法についてよく知っています。ベクトル化された関数は、シリーズまたはDataFrame全体に対して操作をブロードキャストし、従来のデータに対する反復処理よりもはるかに大きなスピードアップを達成します。
しかし、多くのコード (Stack Overflow での回答も含む) が
for
ループとリスト内包を使用したデータ ループを含む問題の解決策を提供する多くのコード (Stack Overflow での回答を含む) を目にし、非常に驚きました。ドキュメントと API には、ループは悪いものであり、配列、系列、または DataFrame に対して反復処理を行うべきではありませんと書かれています。それなのに、ループベースのソリューションを提案するユーザーを時々見かけるのはなぜでしょうか?
1 - この質問はやや幅広く聞こえるのは事実ですが、実際には、次のような非常に特殊な状況があります。
for
ループの方が、従来通りデータを繰り返し処理するよりも良い場合があります。この投稿は、後世に残すためにこれを捕らえることを目的としています。
どのように解決するのですか?
TLDR; いいえ。
for
ループは、少なくとも、常に、ブランケット "悪い"ではありません。それはおそらく
より正確には、いくつかのベクトル化されたオペレーションは反復処理より遅いです。
と言う方が正確でしょう。いつ、なぜそうなるのかを知ることは、コードのパフォーマンスを最大限に引き出すための鍵です。一言で言えば、これらはベクトル化されたpandas関数の代替を検討する価値がある状況です。
- データが小さい場合(...何をしているかにもよりますが)。
-
を扱う場合
object/mixed dtypes -
を使用する場合
str/regex アクセサ関数
これらの状況を個別に検証してみましょう。
小さなデータでの反復処理とベクトル化
Pandasは "Convention Over Configuration" アプローチでAPIを設計しています。これは、同じAPIが幅広いデータとユースケースに対応するように適合されていることを意味します。
pandasの関数が呼び出されたとき、次のようなことが(とりわけ)関数によって内部的に処理され、動作が保証される必要があります。
- インデックス/軸のアライメント
- 混合データ型の処理
- 欠落データの処理
ほとんどすべての関数が、程度の差こそあれ、これらを処理する必要があります。
オーバーヘッド
. 数値関数の場合はオーバーヘッドが少なくなります(例えば。
Series.add
など)、文字列関数では顕著になります(例えば
Series.str.replace
).
for
一方、ループは思ったより速いです。さらに良いのは
リスト内包
(これは
for
ループでリストを作成するもの) は、リスト作成のための最適化された反復メカニズムであるため、さらに高速です。
リスト内包はパターンに従って
[f(x) for x in seq]
ここで
seq
はpandasの系列またはDataFrameのカラムです。または、複数のカラムに対して操作する場合。
[f(x, y) for x, y in zip(seq1, seq2)]
ここで
seq1
と
seq2
は列である。
数値の比較
単純なブーリアンインデックス演算を考えてみましょう。リスト内包メソッドは、時間に対して
Series.ne
(
!=
) と
query
. 以下はその機能です。
# Boolean indexing with Numeric value comparison.
df[df.A != df.B] # vectorized !=
df.query('A != B') # query (numexpr)
df[[x != y for x, y in zip(df.A, df.B)]] # list comp
わかりやすくするために
perfplot
パッケージを使用して、この記事のすべてのtimeitテストを実行しました。上記の操作のタイミングは以下の通りです。
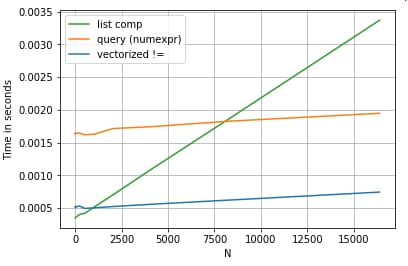
リスト内包は
query
を上回り、小さなNではベクトル化されたnot equal比較さえも上回ります。残念ながら、リスト内包は線形にスケールするので、大きなNではあまり性能向上は望めません。
ノート
リスト内包の利点の多くは、インデックスのアライメントを気にする必要がないことから来ていることは言及に値します。
しかし、これはあなたのコードがインデックスのアライメントに依存している場合、それが壊れることを意味します。
これは、コードがインデックスのアライメントに依存している場合、これが壊れることを意味します。いくつかのケースでは、ベクトル化された操作で
場合によっては、NumPyの配列に対するベクトル化された操作は、両方の良いところを取り入れたと考えることができます。
両方の世界" をもたらすと考えることができ、ベクトル化を可能にします。
を使わずに
pandasの関数のすべての不要なオーバーヘッドなしでベクトル化を可能にします。これは、上記の操作を次のように書き換えることができることを意味します。
df[df.A.values != df.B.values]
これはpandasとリスト内包の等価物の両方を凌駕しています。
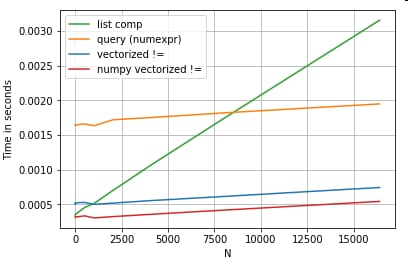
NumPyのベクトル化はこの記事の範囲外ですが、パフォーマンスが重要であれば、間違いなく検討する価値があります。
値のカウント
別の例として、今度は別のバニラパイソンの構成である
より速く
ループよりも高速です。
collections.Counter
. よくある要件は、値のカウントを計算し、その結果を辞書として返すことです。これは
value_counts
,
np.unique
そして
Counter
:
# Value Counts comparison.
ser.value_counts(sort=False).to_dict() # value_counts
dict(zip(*np.unique(ser, return_counts=True))) # np.unique
Counter(ser) # Counter
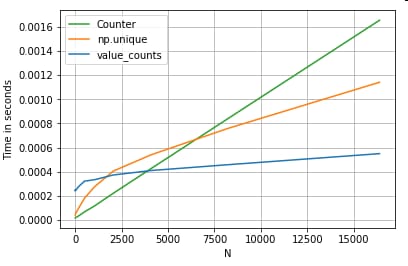
より顕著になりました。
Counter
は、より大きな範囲の小さなN (~3500) に対して、両方のベクトル化されたメソッドよりも勝っています。
注
さらなるトリビア(提供:@user2357112)。そのCounterが実装されているのは C アクセラレータ , ということで、まだ Python のオブジェクトを使う必要がありますが の代わりに python のオブジェクトを扱う必要がありますが、それでもforループよりも高速です。Python のパワー!
もちろん、ここから得られる教訓は、パフォーマンスはデータとユースケースに依存するということです。これらの例のポイントは、これらのソリューションを正当な選択肢として除外しないように説得することです。これらのソリューションで必要なパフォーマンスが得られない場合は、常に cython と numba . このテストを追加してみましょう。
from numba import njit, prange
@njit(parallel=True)
def get_mask(x, y):
result = [False] * len(x)
for i in prange(len(x)):
result[i] = x[i] != y[i]
return np.array(result)
df[get_mask(df.A.values, df.B.values)] # numba

Numbaは、ループするPythonコードを非常に強力なベクトル化されたコードにJITコンパイルする機能を提供します。numbaをどのように動作させるかを理解するには、学習曲線が伴います。
Mixed/を使った操作
object
dtypes
文字列ベースの比較
最初のセクションのフィルタリングの例を見て、比較されるカラムが文字列の場合はどうでしょうか?上の3つの関数と同じですが、入力のDataFrameを文字列にキャストして考えてみましょう。
# Boolean indexing with string value comparison.
df[df.A != df.B] # vectorized !=
df.query('A != B') # query (numexpr)
df[[x != y for x, y in zip(df.A, df.B)]] # list comp
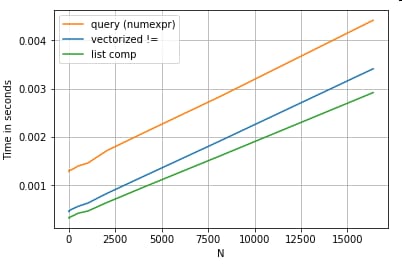
では、何が変わったのでしょうか?ここで注目すべきは 文字列の操作は本質的にベクトル化するのが難しいということです。 Pandasは文字列をオブジェクトとして扱い、オブジェクトに対するすべての操作は遅くてループする実装にフォールバックします。
さて、このルービーな実装は、上記のすべてのオーバーヘッドに囲まれているため、これらのソリューションの間には、同じスケールであっても一定の大きさの違いがあります。
ミュータブル/複雑なオブジェクトに対する操作に関しては、比較の対象にはなりません。リスト内包は、ディクテとリストを含むすべての操作を凌駕します。
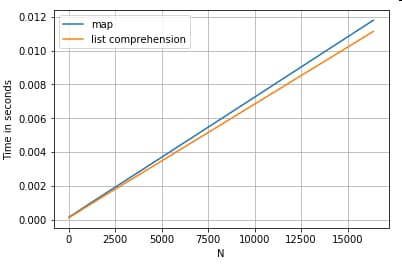
キーによる辞書の値へのアクセス
以下は、辞書のカラムから値を取り出す2つの操作のタイミングです。
map
とリスト内包です。セットアップは付録の「コード・スニペット」の見出しの下にあります。
# Dictionary value extraction.
ser.map(operator.itemgetter('value')) # map
pd.Series([x.get('value') for x in ser]) # list comprehension
位置決めリストインデックス
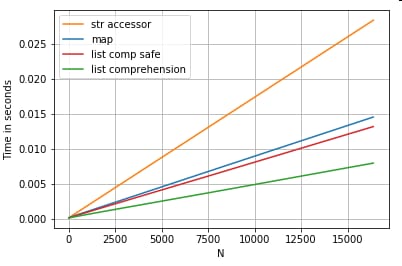
列のリストから0番目の要素を抽出する3つの操作のタイミング(例外処理)。
map
,
str.get
アクセサーメソッド
とリスト内包があります。
# List positional indexing.
def get_0th(lst):
try:
return lst[0]
# Handle empty lists and NaNs gracefully.
except (IndexError, TypeError):
return np.nan
ser.map(get_0th) # map
ser.str[0] # str accessor
pd.Series([x[0] if len(x) > 0 else np.nan for x in ser]) # list comp
pd.Series([get_0th(x) for x in ser]) # list comp safe
ノート
インデックスが重要なら、そうしたいものです。
pd.Series([...], index=ser.index)
系列を再構築する場合。
リストの平坦化
最後の例は、リストを平坦化することです。これもよくある問題で、純粋なPythonがいかに強力であるかを示しています。
# Nested list flattening.
pd.DataFrame(ser.tolist()).stack().reset_index(drop=True) # stack
pd.Series(list(chain.from_iterable(ser.tolist()))) # itertools.chain
pd.Series([y for x in ser for y in x]) # nested list comp
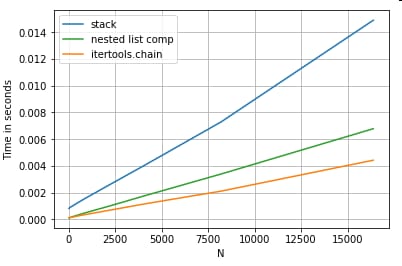
どちらも
itertools.chain.from_iterable
とネストされたリスト内包は純粋なPythonの構造であり、その拡張性は
stack
ソリューションよりもずっとうまくいきます。
これらのタイミングは、pandasが混合されたdtypesで動作するように装備されていないという事実の強い兆候であり、おそらくそうするためにそれを使用することを控えるべきである。可能な限り、データは別々の列にスカラー値(ints/floats/strings)として存在すべきです。
最後に、これらのソリューションの適用可能性は、データによって大きく異なります。したがって、最善の方法は、何を採用するかを決定する前に、自分のデータでこれらの操作をテストすることでしょう。私がどのように時間を計っていないかに注目してください。
apply
の時間を計っていないことに注意してください。グラフが歪んでしまうからです (そう、それほど遅いのです)。
Regex 操作、および
.str
アクセサメソッド
Pandasは以下のような正規表現操作を行うことができます。
str.contains
,
str.extract
そして
str.extractall
といった文字列操作や、他のベクトル化された文字列操作(例えば
str.split
,
str.find
,
str.translate
など) を文字列列に対して実行します。これらの関数はリスト内包よりも遅く、どちらかというと便利な関数であることを意図しています。
通常、正規表現パターンを事前にコンパイルし
re.compile
(また
Pythonのre.compileを使う価値はありますか?
). リストコンパイルに相当するのは
str.contains
はこのようになります。
p = re.compile(...)
ser2 = pd.Series([x for x in ser if p.search(x)])
または
ser2 = ser[[bool(p.search(x)) for x in ser]]
NaNを処理する必要がある場合は、以下のようにします。
ser[[bool(p.search(x)) if pd.notnull(x) else False for x in ser]]
と同等のリストコンパ
str.extract
(グループなし)は以下のような感じになります。
df['col2'] = [p.search(x).group(0) for x in df['col']]
ノーマッチやNaNを処理する必要がある場合は、カスタム関数を使用することができます(それでも高速です!)。
def matcher(x):
m = p.search(str(x))
if m:
return m.group(0)
return np.nan
df['col2'] = [matcher(x) for x in df['col']]
は
matcher
関数は非常に拡張性があります。必要に応じて、各キャプチャグループのリストを返すようにすることができます。ただ、クエリを抽出し
group
または
groups
属性で指定します。
については
str.extractall
を変更します。
p.search
を
p.findall
.
文字列抽出
簡単なフィルタリング操作を考えてみましょう。大文字が前にあれば、4桁の数字を抽出するというものです。
# Extracting strings.
p = re.compile(r'(?<=[A-Z])(\d{4})')
def matcher(x):
m = p.search(x)
if m:
return m.group(0)
return np.nan
ser.str.extract(r'(?<=[A-Z])(\d{4})', expand=False) # str.extract
pd.Series([matcher(x) for x in ser]) # list comprehension
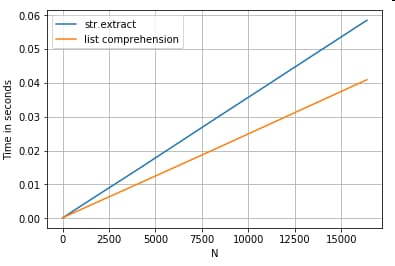
その他の例
完全な開示 - 私は以下の投稿の著者です(一部または全部)。
結論
上記の例からわかるように、反復処理は小さな行のDataFrame、混合データ型、および正規表現を扱うときに輝きます。
得られる速度向上はデータと問題に依存するため、あなたのマイレージは異なるかもしれません。最も良いのは、慎重にテストを実行し、その労力に見合うだけの利益が得られるかどうかを確認することです。
vectorized"関数は、そのシンプルさと可読性において輝いています。
もう一つの側面は、ある文字列操作がNumPyの使用に有利な制約を扱っていることです。ここでは、注意深くNumPyのベクトル化がpythonを凌駕する2つの例を紹介します。
さらに、時には、基礎となる配列を
.values
で操作するだけで、通常のシナリオでは十分な速度が得られることがあります (
注
で
数値の比較
の項を参照)。ですから、例えば
df[df.A.values != df.B.values]
は
df[df.A != df.B]
. 使用方法
.values
を使うことは、すべての状況で適切であるとは限りませんが、知っておくと便利なハックです。
上述したように、これらの解決策がわざわざ実装する価値があるかどうかは、あなた次第です。
付録 コード・スニペット
import perfplot
import operator
import pandas as pd
import numpy as np
import re
from collections import Counter
from itertools import chain
<!- ->
# Boolean indexing with Numeric value comparison.
perfplot.show(
setup=lambda n: pd.DataFrame(np.random.choice(1000, (n, 2)), columns=['A','B']),
kernels=[
lambda df: df[df.A != df.B],
lambda df: df.query('A != B'),
lambda df: df[[x != y for x, y in zip(df.A, df.B)]],
lambda df: df[get_mask(df.A.values, df.B.values)]
],
labels=['vectorized !=', 'query (numexpr)', 'list comp', 'numba'],
n_range=[2**k for k in range(0, 15)],
xlabel='N'
)
<!- ->
# Value Counts comparison.
perfplot.show(
setup=lambda n: pd.Series(np.random.choice(1000, n)),
kernels=[
lambda ser: ser.value_counts(sort=False).to_dict(),
lambda ser: dict(zip(*np.unique(ser, return_counts=True))),
lambda ser: Counter(ser),
],
labels=['value_counts', 'np.unique', 'Counter'],
n_range=[2**k for k in range(0, 15)],
xlabel='N',
equality_check=lambda x, y: dict(x) == dict(y)
)
<!- ->
# Boolean indexing with string value comparison.
perfplot.show(
setup=lambda n: pd.DataFrame(np.random.choice(1000, (n, 2)), columns=['A','B'], dtype=str),
kernels=[
lambda df: df[df.A != df.B],
lambda df: df.query('A != B'),
lambda df: df[[x != y for x, y in zip(df.A, df.B)]],
],
labels=['vectorized !=', 'query (numexpr)', 'list comp'],
n_range=[2**k for k in range(0, 15)],
xlabel='N',
equality_check=None
)
<!- ->
# Dictionary value extraction.
ser1 = pd.Series([{'key': 'abc', 'value': 123}, {'key': 'xyz', 'value': 456}])
perfplot.show(
setup=lambda n: pd.concat([ser1] * n, ignore_index=True),
kernels=[
lambda ser: ser.map(operator.itemgetter('value')),
lambda ser: pd.Series([x.get('value') for x in ser]),
],
labels=['map', 'list comprehension'],
n_range=[2**k for k in range(0, 15)],
xlabel='N',
equality_check=None
)
<!- ->
# List positional indexing.
ser2 = pd.Series([['a', 'b', 'c'], [1, 2], []])
perfplot.show(
setup=lambda n: pd.concat([ser2] * n, ignore_index=True),
kernels=[
lambda ser: ser.map(get_0th),
lambda ser: ser.str[0],
lambda ser: pd.Series([x[0] if len(x) > 0 else np.nan for x in ser]),
lambda ser: pd.Series([get_0th(x) for x in ser]),
],
labels=['map', 'str accessor', 'list comprehension', 'list comp safe'],
n_range=[2**k for k in range(0, 15)],
xlabel='N',
equality_check=None
)
<!- ->
# Nested list flattening.
ser3 = pd.Series([['a', 'b', 'c'], ['d', 'e'], ['f', 'g']])
perfplot.show(
setup=lambda n: pd.concat([ser2] * n, ignore_index=True),
kernels=[
lambda ser: pd.DataFrame(ser.tolist()).stack().reset_index(drop=True),
lambda ser: pd.Series(list(chain.from_iterable(ser.tolist()))),
lambda ser: pd.Series([y for x in ser for y in x]),
],
labels=['stack', 'itertools.chain', 'nested list comp'],
n_range=[2**k for k in range(0, 15)],
xlabel='N',
equality_check=None
)
<!- _>
# Extracting strings.
ser4 = pd.Series(['foo xyz', 'test A1234', 'D3345 xtz'])
perfplot.show(
setup=lambda n: pd.concat([ser4] * n, ignore_index=True),
kernels=[
lambda ser: ser.str.extract(r'(?<=[A-Z])(\d{4})', expand=False),
lambda ser: pd.Series([matcher(x) for x in ser])
],
labels=['str.extract', 'list comprehension'],
n_range=[2**k for k in range(0, 15)],
xlabel='N',
equality_check=None
)
関連
-
PythonによるLeNetネットワークモデルの学習と予測
-
Python Decorator 練習問題
-
[解決済み] for'ループでインデックスにアクセスする?
-
[解決済み] 要素ごとの加算は、結合ループよりも分離ループの方がはるかに高速なのはなぜですか?
-
[解決済み] 配列の反復処理に "for...in "を使用するのは、なぜ良くないのでしょうか?
-
[解決済み] Pythonで悪い/不正な引数の組み合わせに対してどの例外を発生させるべきですか?
-
[解決済み] pandas DataFrameの特定のセルに対して、インデックスを使用して値を設定する
-
[解決済み] pandas GroupByを使ってグループごとの統計情報(カウント、平均値など)を取得する?
-
[解決済み] PandasとPythonでCSVファイルを読み込むとUnicodeDecodeErrorが発生する。
-
[解決済み】forループを使った辞書の反復処理
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み] データ型が理解できない
-
[解決済み】csv.Error:イテレータはバイトではなく文字列を返すべき
-
[解決済み] 'DataFrame' オブジェクトに 'sort' 属性がない
-
[解決済み] PandasでDataFrameの行を反復処理する方法
-
[解決済み] PandasのデータフレームをSQLのように'in'と'not in'でフィルタリングする方法
-
[解決済み] Pythonのre.compileは使う価値があるのか?
-
[解決済み】pandasの関数をカラムに適用して、複数の新しいカラムを作成する?
-
[解決済み] 列の文字列から不要な部分を削除する
-
[解決済み] Pandasを使って文字列列列の各値に文字列の接頭辞を追加する
-
[解決済み] Pandasはデータフレームをタプルの配列に変換する