pandas write excel_Pandas Excel tutorial: Excelファイルの読み方、書き方
pandasでExcelに書き込む
このチュートリアルでは、ExcelファイルとPythonの扱い方について学びます。最初のセクションでは、Excelファイルを読み込む方法、スプレッドシートから特定の列を読み込む方法、複数のスプレッドシートを読み込んで1つのデータフレームにまとめる方法、多数のExcelファイルを読み込む方法、最後に特定のデータ型に従ってデータを変換する方法(例えば、Pandas dtypesを使用)を例示して説明していきます。これが終わったら、Excelファイルの書き方、シート名の付け方、複数のシートへの書き方を学びます。
このチュートリアルでは、ExcelファイルとPythonの操作方法について学びます。また、Pandaを使ってExcelにスプレッドシートを読み込んだり書き込んだりする方法についても概説します。最初のパートでは、Excelファイルを読み込む方法、スプレッドシートから特定の列を読み込む方法、複数のスプレッドシートを読み込んで1つのデータボックスにマージする方法、多数のExcelファイルを読み込む方法、最後に特定のデータ型に基づいてデータを変換する方法(例えば、Pandas dtypesを使って)の例を通して説明します。これが終わると、Excelファイルの書き方の学習に移ります。ワークシートに名前を付ける方法と、複数のワークシートに書き込む方法です。
<スパン パンダのインストール方法 <スパン ( パンダのインストール方法 )
このExcelファイルの読み書きのチュートリアルを続ける前に、Pandasをインストールする必要があります(もちろん、Pythonがインストールされていない場合は、それも)。Pipがインストールされていれば、Pipを使用してPandasをインストールすることができます。詳細は こちら pipのインストール方法です。
Excelドキュメントのチュートリアルを読み、書き続ける前に、いくつかのことをする必要があります。Pandasをインストールする(もちろんPythonがインストールされていない場合はPythonをインストールする)。すでにPipがインストールされていると仮定して、Pipを使ってPandasをインストールします。以下を参照してください。 こちら は、pipのインストール方法です。
# Linux Users
pip install pandas
# Windows Users
python pip install pandas
<スパン Anaconda Scientific Pythonディストリビューションのインストール <スパン ( Anaconda Scientific Pythonディストリビューションのインストール )
もう1つの素晴らしい選択肢は、インストールすることです。 Anaconda Python ディストリビューション . これは、コンピュータサイエンスを始めるのに、本当に簡単で早い方法です。
もう一つ、検討すべきは Anaconda Pythonディストリビューション . これは、コンピュータサイエンスを始めるのに、実に簡単で迅速な方法です。コンピュータサイエンスのために別のパッケージをインストールする必要があることを心配する必要はありません。
上記の2つの方法は、いずれも このチュートリアル .
このチュートリアル は、この2つの方法について説明しています。
<スパン ExcelファイルをPandasのデータフレームに読み込む方法。 <スパン ( ExcelファイルをPandasのデータフレームに読み込む方法。 )
このセクションでは、Excel ファイルやスプレッドシートを Pandas データフレームオブジェクトに読み込む方法について学びます。この Pandas Excel チュートリアルのすべての例では、read_excel を使用しています。read_excel は、URL からデータフレームに Excel ファイルを読み込むこともできることに注意してください。Pandasを使うときはいつも通り、モジュールをインポートするところから始めなければなりません。
このセクションでは、ExcelファイルやスプレッドシートをPandasデータフレームオブジェクトに読み込む方法について学びます。この Pandas Excel チュートリアルの例では、すべてネイティブファイルを使用します。read_excel は、URL からデータボックスに Excel ファイルを読み込むこともできることに注意してください。いつものように、Pandasで作業するときは、Importモジュールから始めなければなりません。
import pandas as pd
さて、いよいよPandasのread_excelを使ってExcelファイルからデータを読み込む方法を学びましょう。このメソッドの最も簡単な使い方は、ファイル名を渡すことです。シート名などの他のパラメータを渡さなければ、インデックス内の最初のシートを読み込みます。最初の例では、パラメータを使用しません。
さて、いよいよ Pandas read_excel を使って Excel ファイルからデータを読み込む方法を学びましょう。このメソッドの最も簡単な使用方法は、ファイル名を文字列として渡すことです。もし他のパラメータ(ワークシート名など)を渡さなければ、インデックス内の最初のワークシートを読みます。最初の例では、何もパラメータを使用しません。
df = pd.read_excel('MLBPlayerSalaries.xlsx')
df.head()
ここでは、Pandas read_excel メソッドは Excel ファイルから Pandas dataframe オブジェクトにデータを読み込んでいます。そして、このデータフレームを df という変数に格納しました。
Pandasはread_excelを使用する際、デフォルトでデータフレームに数値インデックスまたは行ラベルを割り当てますが、Pythonのintに関しては通常通り、インデックスは デフォルトインデックスのままにしておく理由があるかもしれません。例えば、あなたのデータには、より良いインデックスとして機能するユニークな値を持つ列がない場合です。よりよいインデックスとなるカラムがある場合は、デフォルトの挙動をオーバーライドすることができます。
デフォルトでは、read_excelを使用する場合、Pandasはデータボックスに数値インデックスまたは行ラベルを割り当て、Pythonでintが表示された場合、Pandasは通常通り0から開始します。デフォルトのインデックスを維持する理由があるかもしれません。例えば、データに一意な値を持つ列がない場合、より良いインデックスとして使用することができます。もし、より良いインデックスとして使用できるカラムがあれば、デフォルトの動作を上書きすることができます。
これは、index_colパラメータをカラムに設定することで実現します。以下の例では、'Player'カラムをインデックスとして使用していますが、これらは一意ではないので、これらの値をインデックスとして使用することは意味をなさないかもしれません。
これは、index_colパラメータを1つのカラムに設定することで実現します。1つのカラムをインデックスに設定するには1つの値を使用し、複数のインデックスを作成するには値のリストを使用します。以下の例では、"player" カラムをインデックスとして使用しています。これらは一意ではないので、これらの値をインデックスとして使用するのは意味がないかもしれないことに注意してください。
df = pd.read_excel('MLBPlayerSalaries.xlsx', sheet_names='MLBPlayerSalaries', index_col='Player')
<スパン read_excel を使って特定のカラムを読み込む ( read_excelを使った特定列の読み込み )
Pandas read_excel を使用すると、Excel ファイルからすべての列を自動的に取得します。例えば、Player、Salary、Positionのカラムのみを持つデータフレームを作成したいとします。 これを行うには、リストに1、3、4を追加します。
Pandas read_excel を使用する場合、Excel ファイルからすべての列を自動的に取得します。もし何らかの理由でExcelファイルの全ての列をパースしたくない場合は、usecolsというパラメータを使います。例えば、選手、給料、ポジションの列を持つデータボックスを作成したいだけだとします。この場合、リストに 1、3、4 を追加します。
cols = [1, 2, 3]
df = pd.read_excel('MLBPlayerSalaries.xlsx', sheet_names='MLBPlayerSalaries', usecols=cols)
df.head()
read_excelのドキュメントによると、文字列を入力することができるはずです。
read_excelのドキュメントに基づけば、文字列を入れることができるはずです。例えば、cols = 'Player:Position' とすると、上記と同じ結果になるはずです。
<スパン 欠落データ ( 欠落データ )
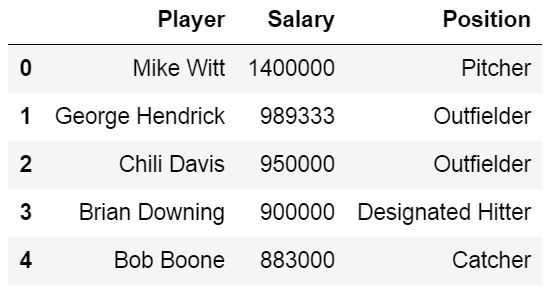
データに欠損値があり、その欠損値が "Missing"のように何らかの形でコード化されている場合、na_ values パラメータを使用することができます。
もし、いくつかのセルに欠損値があるデータがあり、それらの欠損値を"missing"などの何らかの方法でエンコードする場合、na_valuesパラメータを使用することができます。
<スパン パンダが欠落データを読み取るExcelの例 <スパン ( パンダがデータを読み込むExcelの例(欠落データあり )
以下の例では、パラメータna_valuesに文字列(例: "Missing')を入れています。
以下の例では、パラメータ na_values を使用して、文字列 (すなわち "Missing") を入れています。
df = pd.read_excel('MLBPlayerSalaries_MD.xlsx', na_values="Missing", sheet_names='MLBPlayerSalaries', usecols=cols)
df.head()
上記のExcelの読み込みの例では、次のサイトからダウンロードできるデータセットを使用しました。 これ のページをご覧ください。
上記の例でExcelを読み込むために、データセットは以下のアドレスからダウンロードできます。 これは のページをご覧ください。
- 投稿を読む Pandasによるデータ操作 には、データフレームのデータ操作(欠損データを含む)に関する3つのメソッドがあります。
<スパン Excelファイル読み込み時に行をスキップする方法 ( Excelファイルを読み込む際に行をスキップする方法 )
では、Pandasを使ってExcelファイルを読み込む際に行をスキップする方法を学びます。このExcelの読み込みの例では、ここからダウンロードできるデータを使用します。
ここでは、Pandasを使用してExcelファイルを読み込む際に行をスキップする方法について学びます。このExcelの読み込みの例では、ここからダウンロードできるデータを使用します。
この例では、スキップする必要のある行を含むシート 'session1' を読み込みます。これらの行には、データセットに関するいくつかの情報が含まれています。
 パラメータsheet_name='Session1′を使用して、'Session1'という名前のシートを読み込むことにします。なお、sheet_name パラメータを使用しない場合は、最初のシートが読み込まれます。この例で重要なのはskiprow=2というパラメータで、これを使うと最初の2行がスキップされます。
パラメータsheet_name='Session1′を使用して、'Session1'という名前のシートを読み込むことにします。なお、sheet_name パラメータを使用しない場合は、最初のシートが読み込まれます。この例で重要なのはskiprow=2というパラメータで、これを使うと最初の2行がスキップされます。
この例では、スキップする必要がある行を含むワークシート("session1")を読み込んでいます。これらの行には、データセットに関するいくつかの情報が含まれています。パラメータ sheet_name = 'Session1' を使って、'Session1' という名前のワークシートを読み込むことにします。sheet_nameパラメータを使用しない場合、最初のシートが読み込まれることに注意してください。この例で重要なのは、skiprow = 2というパラメータです。このパラメータは、最初の2行をスキップするために使用します。
df = pd.read_excel('example_sheets1.xlsx', sheet_name='Session1', skiprows=2)
df.head()
headerパラメータを使用しても、上記と同様の結果を得ることができます。Excelファイルの例では、3行目にヘッダがあり、header=2というパラメータを使って、ヘッダが3行目にあることをPandas read_excelに教えているところです。
headerパラメータを使っても、上記と同じ結果になります。ここで使用しているExcelファイルのサンプルでは、3行目にヘッダが含まれています。header = 2パラメータを使用して、Pandas read_excelにヘッダが3行目にあることを知らせます。
df = pd.read_excel('example_sheets1.xlsx', sheet_name='Session1', header=2)
<スパン 複数のExcelワークシートをPandasのデータフレームに読み込む <スパン ( 複数のExcelシートをPandasのデータフレームに読み込む )
Excelファイルexample_sheets1.xlsx'には2つのシートがあります。Session1'と'Session2'です。それぞれのシートは、想像上の実験セッションのデータを持っています。次の例では、'Session1 ' と 'Session2' の両方のシートを読み込むことにします。ここでは、Pandasのread_excelを複数のシートで使用する方法を説明します。
Excel ファイル example_sheets1.xlsx には 2 つのシートがあります: " Session1 " と " Session2 " です。それぞれのシートには、架空の実験セッションからのデータが含まれています。次の例では、2つの表 " Session1" と " Session2" を読み取ります。ここでは、Panda read_excel を複数の用紙に使用する方法を説明します。
df = pd.read_excel('example_sheets1.xlsx', sheet_name=['Session1', 'Session2'], skiprows=2)
パラメータsheet_nameと名前のリストを使うことで、2つのデータフレームを含む順序付き辞書が得られます。
パラメータ sheet_name と名前のリストを使用すると、2つのデータフレームを含む順序付き辞書が得られます。
df
すべてのシート(この場合はセッション)のデータを結合したいと思うかもしれません。Pandasのデータフレームをマージするのは非常に簡単です。concat 関数を使用して、キー(つまりシート)をループするだけです。
ワークシート(この場合はセッション)内のすべてのデータを結合したいかもしれません。Panda のデータフレームをマージするのは非常に簡単です。concat関数を使い、キー(つまりシート)に対して反復処理を行うだけです。
df2 = pd.concat(df[frame] for frame in data.keys())
さて、例のExcelファイルには、データセットを識別する列(例えば、セッション番号)があります。しかし、私たちのExcelファイルには、そのような情報はないかもしれません。2つのデータフレームをマージして、どのセッションかを示すカラムを追加するには、forループを使用します。
さて、サンプルのExcelファイルには、データセットを識別する列(例:セッション番号)があります。しかし、おそらく私たちのExcelファイルにはそのような情報はないでしょう。2つのデータフレームを結合し、どのセッションかを示す列を追加するには、forループを使用することができます。
dfs = []
for framename in data.keys():
temp_df = data[framename]
temp_df['Session'] = framename
dfs.append(temp_df)
df = pd.concat(dfs)
上記のコードでは、まずリストを作成し、データフレームのリストにあるキーをループしています。最後に、一時的なデータフレームを作成してシート名を取得し、それを 'Session' 列に追加しています。
上記のコードでは、まずリストを作成し、次にデータフレームのリスト内のキーを繰り返し処理します。最後に、一時的なデータフレームを作成し、シート名を取得して 'Session' カラムに追加しています。
<スパン Excelですべての図面を読み込むパンダ ( パンダがExcelの全シートを読み込む )
もし、read_excel を使って、Excel ファイルからデータフレームにすべてのシートをロードしたい場合は、もちろん可能です。パラメータsheet_nameをNoneに設定すればよいのです。
read_excelを使用して、Excelファイルからdataframeにすべてのシートをロードしたい場合、それは、もちろん可能です。パラメータ sheet_name を None に設定すればよい。
all_sheets_df = pd.read_excel('example_sheets1.xlsx', sheet_name=None)
<スパン 多くのExcelファイルを読み込む <スパン ( 多くのExcelファイルを読み込む )
このセクションでは、多くのファイルを Pandas のデータフレームに読み込む方法を学びます。例えば、異なる実験からのデータを含む多くの Excel ファイルがある場合があるからです。Pythonでは、モジュール os と fnmatch 最後に、リスト内包を利用して、見つかったすべてのファイルに対してread_excelを使用します。
このセクションでは、多くのファイルをPandasのデータフレームに読み込む方法を学びます。なぜなら、場合によっては、異なる実験からのデータを含む多くのExcelファイルを持っているかもしれないからです。Python では os と fnmatch モジュールで、ディレクトリ内のすべてのファイルを読み込むことができます。最後に、リスト導出を使って見つかったすべてのファイルに対して read_excel を使用します。
import os, fnmatch
xlsx_files = fnmatch.filter(os.listdir('.') , '*concat*.xlsx')
dfs = [pd.read_excel(xlsx_file) for xlsx_file in xlsx_files]
もし意味があるのなら、再びconcat関数を使ってデータフレームを結合することができます。
もしそれが理にかなっているなら、もう一度、関数concatを使ってデータフレームをマージすることができます。
df = pd.concat(dfs, sort=False)
この他にも、多数のExcelファイルを読み込んで結合する方法があります。たとえば、モジュール グロブ :
他にも、たくさんのExcelファイルを読み込んでマージする方法があります。たとえば、モジュール グロブ :
import glob
list_of_xlsx = glob.glob('. /*concat*.xlsx')
df = pdf.concat(list_of_xlsx)
<スパン データまたはカラムのデータ型を設定する <スパン ( データまたはカラムのデータ型を設定する )
example_sheets1.xlsxをもう一度読んでみましょう。以下のPandas read_excelの例では、dtypeパラメータを使って、いくつかのカラムのデータ型を設定しています。
必要であれば、列のデータ型を設定することもできます。もう一度 example_sheets1.xlsx を読んでみましょう。以下のPandas read_excelの例では、dtypeパラメータを使っていくつかのカラムのデータ型を設定しています。
df = pd.read_excel('example_sheets1.xlsx',sheet_name='Session1',
header=1,dtype={'Names':str,'ID':str,
'Mean':int, 'Session':str})
infoメソッドを使って、異なるカラムがどのようなデータ型を持っているかを確認することができます。
infoメソッドを使って、異なるカラムがどのようなデータ型を持っているかを確認することができます。
df.info()
<スパン PandasのデータボックスをExcelに書き込む ( PandasのデータフレームをExcelに書き込む )
Excelファイルは、もちろんPythonでPandasモジュールを使って作成することができます。このセクションでは、Pandasを使用してExcelファイルを作成する方法を学びます。いくつかの変数でデータフレームを作成することから始めますが、最初にモジュールPandasをインポートすることから始めます。
もちろん、PythonでExcelファイルを作成するには、Pandasモジュールを使用します。このパートでは、Pandasを使用してExcelファイルを作成する方法を学びます。まずは、いくつかの変数でデータフレームを作成しますが、その前にPandasモジュールをインポートします。
import pandas as pd
次は、データフレームの作成です。ここでは、辞書を使ってデータフレームを作成します。キーは列名で、値はデータを含むリストとなります。
次に、データフレームを作成します。辞書を使用してデータフレームを作成します。キーは列名で、値はデータを含むリストになります。
df = pd.DataFrame({'Names':['Andreas', 'George', 'Steve',
'Sarah', 'Joanna', 'Hanna'],
'Age':[21, 22, 20, 19, 18, 23]})
次に、*to_excel*メソッドを使用してデータフレームをExcelファイルに書き込みます。以下のPandas to_excelの例では、パラメータを使用していません。
次に、*to_excel *メソッドを使用して、データフレームをExcelファイルに書き込みます。以下のPandas to_excelの例では、パラメータは使用していません。
df.to_excel('NamesAndAges.xlsx')
以下の出力では、パラメータを使用しない場合の効果が明らかです。パラメータsheet_nameを使用しない場合、デフォルトのシート名である'Sheet1'が出力されます。また、Excelファイルに数字を含む新しい列が作成されることも確認できます。これはデータフレームからのインデックスです。
以下の出力では、引数を使用しないことの効果が一目瞭然です。sheet_nameパラメータがない場合、デフォルトのシート名 " Sheet1" が得られます。また、Excelファイルに数字を含む新しい列が作成されていることも確認できます。これはデータボックスのインデックスです。
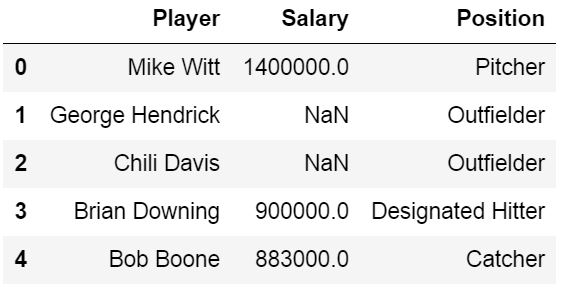
もし、シートに他の名前を付けたい、インデックス・カラムを使いたくない場合は、このようにします。
もし、シートに他の名前を付けたいが、インデックスカラムが必要ない場合は、このようにすることができます。
df.to_excel('NamesAndAges.xlsx', sheet_name='Names and Ages', index=False)
<スパン 複数のパンダのデータボックスを1つのExcelファイルに書き込む。 ( 複数のPandasデータフレームをExcelファイルに書き出す。 )
もし、多くのデータフレームを1つのExcelファイルに格納したいが、異なるシートに格納したい場合、簡単にこれを行うことができます。
もし、多くのデータフレームを1つのExcelファイルに格納したいが、異なるシートに格納したい場合は、簡単にこれを行うことができます。ただし、ExcelWriterを使用する必要があります。
df1 = pd.DataFrame({'Names': ['Andreas', 'George', 'Steve',
'Sarah', 'Joanna', 'Hanna'],
'Age':[21, 22, 20, 19, 18, 23]})
df2 = pd.DataFrame({'Names': ['Pete', 'Jordan', 'Gustaf',
'Sophie', 'Sally', 'Simone'],
'Age':[22, 21, 19, 19, 29, 21]})
df3 = pd.DataFrame({'Names': ['Ulrich', 'Donald', 'Jon',
'Jessica', 'Elisabeth', 'Diana'],
'Age':[21, 21, 20, 19, 19, 22]})
dfs = {'Group1':df1, 'Group2':df2, 'Group3':df3}
writer = pd.ExcelWriter('NamesAndAges.xlsx', engine='xlsxwriter')
for sheet_name in dfs.keys():
dfs[sheet_name].to_excel(writer, sheet_name=sheet_name, index=False)
writer.save()
上記のコードでは、3つのデータフレームを作成し、それらを引き続き辞書に格納しています。この後、xlsxwriter エンジンを使ってライターオブジェクトを作成します。そして、キー(すなわちシート名)をループして、各シートを追加していきます。最後に、ファイルを保存します。これを省くと意図した結果にならないので、重要です。
上記のコードでは、3つのデータボックスを作成し、それを辞書に登録するところまで進めています。キーがワークシート名で、セル名がデータボックスであることに注意してください。これが終わったら、xlsxwriterエンジンを使ってライターオブジェクトを作成します。そして、キー(すなわち、ワークシート名)を繰り返し、各ワークシートを追加していきます。最後に、ファイルを保存する。これを省略すると期待するような結果が得られないので、重要です。
<スパン まとめ:パンダのエクセルファイルの扱い方 ( まとめ:Pandasを使ってExcelファイルを操作する方法 )
この投稿で、私たちは多くのことを学びました 特に、どのようにすればよいかを学びました。
以上です。この記事で私たちは多くのことを学びました! 他のものの中で、私たちは、方法を学びました。
-
read_excelを使用してExcelファイルやスプレッドシートを読み込む
- 多数のシートをデータフレームにマージする 多数のExcelファイルを1つのデータフレームに読み込む
- データフレームをExcelファイルに書き出す
- 多数のデータフレームを取り込み、多数のシートを持つ1つのExcelファイルに書き込む
-
read_excelを使ったExcelファイルやスプレッドシートの読み込み
-
Excel ファイルをデータボックスに読み込む。
- Excelワークシートの読み込みと行のスキップ
- 多くのワークシートを1つのデータボックスにまとめる
- 多数のExcelファイルを1つのデータボックスに読み込む
-
Excel ファイルをデータボックスに読み込む。
- データボックスのExcelファイルへの書き込み
- 多数のデータボックスを抽出し、多数の図面が入ったExcelファイルに書き込む
-
Excelファイルをデータフレームに読み込む。
-
Excelシートの読み込みと行のスキップ
要望や次に取り上げるべき内容があれば、下にコメントを残してください。投稿を確認する 初心者のためのPandasデータフレームの基礎チュートリアル つまり、ファイル(Excelのスプレッドシートなど)から読み込んだ後に
要望や次に取り上げるべきことがあれば、以下にコメントを投稿してください。お願い Pandasデータフレームの基礎知識"の記事を参照してください。 は、Pandasデータの使用についてより詳しく学ぶために のボックス をご覧ください。つまり、ファイル(Excelのスプレッドシートなど)から読み込んだ後
Translated from : https://www.pybloggers.com/2018/11/pandas-excel-tutorial-how-to-read-and-write-excel-files/
パンダがエクセルに書き込む
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
ハートビート・エフェクトのためのHTML+CSS
-
HTML ホテル フォームによるフィルタリング
-
HTML+cssのボックスモデル例(円、半円など)「border-radius」使いやすい
-
HTMLテーブルのテーブル分割とマージ(colspan, rowspan)
-
ランダム・ネームドロッパーを実装するためのhtmlサンプルコード
-
Html階層型ボックスシャドウ効果サンプルコード
-
QQの一時的なダイアログボックスをポップアップし、友人を追加せずにオンラインで話す効果を達成する方法
-
sublime / vscodeショートカットHTMLコード生成の実装
-
HTMLページを縮小した後にスクロールバーを表示するサンプルコード
-
html のリストボックス、テキストフィールド、ファイルフィールドのコード例