[解決済み] 私のコードでpandas apply()を使用したい(したくない)のはどんなときですか?
質問
Stack Overflowの質問に対して、Pandasのメソッドを使用した回答が多数投稿されているのを見かけました。
apply
. また、その下にユーザーが「"」とコメントしているのを見たことがあります。
apply
は遅いので、避けるべきです" 。
私は、パフォーマンスに関する多くの記事を読みましたが、その中で、以下のように説明されています。
apply
が遅い。また、ドキュメントにある免責事項で
apply
は、単にUDFを渡すための便利な関数です(今は見つからないようです)。というわけで、一般的なコンセンサスは
apply
は可能な限り避けるべきです。しかし、これには次のような疑問があります。
-
もし
applyはそんなに悪いものなのか、ではなぜAPIにあるのだろう? -
いつ、どのように、自分のコードを
apply-フリー? -
という場面はありますか?
applyは 良い (他の可能な解決策よりも)良いですか?
どのように解決するのですか?
apply
今まで必要なかった便利な機能
まずは、OPにある質問に一つずつ答えていきます。
<ブロッククオート
もし
apply
はそんなに悪いことなのか、ではなぜAPIに含まれているのか、"。
DataFrame.apply
そして
Series.apply
は
便利な機能
DataFrameとSeriesオブジェクトにそれぞれ定義されています。
apply
は、DataFrame に変換/集計を適用する任意のユーザ定義関数を受け付けます。
apply
は、既存のpandas関数ができないことを何でもやってくれる、事実上の銀の弾丸です。
いくつかのものは
apply
ができます。
- DataFrameまたはSeriesに対して、任意のユーザー定義関数を実行する。
-
行単位で関数を適用する (
axis=1) または列単位で (axis=0) のデータフレーム - 関数を適用する際にインデックスのアライメントを行う
-
ユーザー定義関数で集計を行う(ただし、通常、私たちが好むのは
aggまたはtransformこのような場合) - 要素ごとの変換を行う
-
集計結果を元の行にブロードキャストする(
result_type引数)を使用します。 - ユーザー定義関数に渡す位置決め/キーワード引数を受け付ける。
...中でも 詳しくは 行または列単位の関数適用 のドキュメントを参照してください。
では、これだけの機能がありながら、なぜ
apply
悪いこと?それは
なぜなら
apply
は
遅い
. Pandas は関数の性質について何も仮定しません。
関数を繰り返し適用する
を、必要に応じて各行/列に対して適用します。さらに
すべて
上記のような状況下で
apply
は、各反復処理で大きなオーバーヘッドを発生させます。さらに
apply
は、より多くのメモリを消費するため、メモリに制約のあるアプリケーションにとっては課題となります。
という場面はほとんどありません。
apply
を使うのが適切です(詳しくは後述します)。
を使うべきかどうか迷った時は
apply
おそらく、そうすべきではないでしょう。
次の質問にお答えしましょう。
<ブロッククオート
いつ、どのようにコードを作成すればよいのでしょうか?
apply
-free?"
言い換えると、よくあるシチュエーションは以下の通りです。
取り除く
への呼び出しのうち
apply
.
数値データ
もしあなたが数値データを扱っているなら、あなたがやろうとしていることを正確に行うベクトル化されたcython関数がすでにあるはずです(ない場合は、Stack Overflowで質問するか、GitHubで機能要求を開いてください)。
のパフォーマンスを比較します。
apply
は、単純な足し算の操作の場合です。
df = pd.DataFrame({"A": [9, 4, 2, 1], "B": [12, 7, 5, 4]})
df
A B
0 9 12
1 4 7
2 2 5
3 1 4
<!- ->
df.apply(np.sum)
A 16
B 28
dtype: int64
df.sum()
A 16
B 28
dtype: int64
性能面では比較にならないほど、cython化された同等品はずっと高速です。おもちゃのデータでもその差は歴然としているので、グラフは必要ありません。
%timeit df.apply(np.sum)
%timeit df.sum()
2.22 ms ± 41.2 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
471 µs ± 8.16 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
で生配列を渡せるようにしても
raw
引数で指定しても、2倍は遅くなります。
%timeit df.apply(np.sum, raw=True)
840 µs ± 691 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
別の例
df.apply(lambda x: x.max() - x.min())
A 8
B 8
dtype: int64
df.max() - df.min()
A 8
B 8
dtype: int64
%timeit df.apply(lambda x: x.max() - x.min())
%timeit df.max() - df.min()
2.43 ms ± 450 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
1.23 ms ± 14.7 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
一般的には 可能であれば、ベクター化された代替品を探してください。
文字列/レジェックス
Pandasは、ほとんどの状況においてquot;vectorized"文字列関数を提供しますが、稀にそれらの関数が... "apply" 言わば、適用できない場合があります。
よくある問題は、ある列の値が同じ行の別の列にも存在するかどうかをチェックすることです。
df = pd.DataFrame({
'Name': ['mickey', 'donald', 'minnie'],
'Title': ['wonderland', "welcome to donald's castle", 'Minnie mouse clubhouse'],
'Value': [20, 10, 86]})
df
Name Value Title
0 mickey 20 wonderland
1 donald 10 welcome to donald's castle
2 minnie 86 Minnie mouse clubhouse
これは、"donald" と "minnie" がそれぞれの "Title" 列に存在するので、2行目と3行目を返すはずです。
applyを使用すると、これは次のようになります。
df.apply(lambda x: x['Name'].lower() in x['Title'].lower(), axis=1)
0 False
1 True
2 True
dtype: bool
df[df.apply(lambda x: x['Name'].lower() in x['Title'].lower(), axis=1)]
Name Title Value
1 donald welcome to donald's castle 10
2 minnie Minnie mouse clubhouse 86
しかし、リスト内包を使うことで、より良い解決策があります。
df[[y.lower() in x.lower() for x, y in zip(df['Title'], df['Name'])]]
Name Title Value
1 donald welcome to donald's castle 10
2 minnie Minnie mouse clubhouse 86
<!- ->
%timeit df[df.apply(lambda x: x['Name'].lower() in x['Title'].lower(), axis=1)]
%timeit df[[y.lower() in x.lower() for x, y in zip(df['Title'], df['Name'])]]
2.85 ms ± 38.4 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
788 µs ± 16.4 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
ここで注目すべきは、反復ルーチンの方が、たまたま
apply
その理由は、オーバーヘッドが少ないからです。NaNや無効なdtypesを処理する必要がある場合は、リスト内包内の引数で呼び出すカスタム関数を使用して、これを構築することができます。
リスト内包がどのような場合に有効であるかについては、私の記事を参照してください。 pandasのforループは本当にダメなのか?どのような場合に気にすべきなのか? .
備考
日付と日時の操作には、ベクトル化されたバージョンもあります。ですから、たとえばpd.to_datetime(df['date'])よりも、です。 を言う。df['date'].apply(pd.to_datetime).詳しくはこちらで ドキュメント .
よくある落とし穴。リストの列が爆発する
s = pd.Series([[1, 2]] * 3)
s
0 [1, 2]
1 [1, 2]
2 [1, 2]
dtype: object
を使いたくなるのが人情です。
apply(pd.Series)
. これは
恐ろしい
を、性能の面で実現しました。
s.apply(pd.Series)
0 1
0 1 2
1 1 2
2 1 2
より良い方法は、カラムをリスト化してpd.DataFrameに渡すことです。
pd.DataFrame(s.tolist())
0 1
0 1 2
1 1 2
2 1 2
<!- ->
%timeit s.apply(pd.Series)
%timeit pd.DataFrame(s.tolist())
2.65 ms ± 294 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
816 µs ± 40.5 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
最後に
という場面はありますか?
applyは良いのか"。
Applyは便利な機能なので、そこに は オーバーヘッドが無視できるほど小さい場合。それは、この関数が何回呼び出されるかによります。
シリーズではベクトル化されるが、データフレームではベクトル化されない関数
複数の列に対して文字列操作を適用したい場合はどうすればよいですか?複数のカラムをdatetimeに変換したい場合はどうすればよいのでしょうか?これらの関数はSeriesのみベクトル化されているので、必ず
適用
を、変換・操作したい各カラムに適用してください。
df = pd.DataFrame(
pd.date_range('2018-12-31','2019-01-31', freq='2D').date.astype(str).reshape(-1, 2),
columns=['date1', 'date2'])
df
date1 date2
0 2018-12-31 2019-01-02
1 2019-01-04 2019-01-06
2 2019-01-08 2019-01-10
3 2019-01-12 2019-01-14
4 2019-01-16 2019-01-18
5 2019-01-20 2019-01-22
6 2019-01-24 2019-01-26
7 2019-01-28 2019-01-30
df.dtypes
date1 object
date2 object
dtype: object
の許容範囲内のケースです。
apply
:
df.apply(pd.to_datetime, errors='coerce').dtypes
date1 datetime64[ns]
date2 datetime64[ns]
dtype: object
また、次のようにすることも意味があります。
stack
または、明示的なループを使用します。これらのオプションはすべて
apply
しかし、その差は十分に小さいので、許せる範囲です。
%timeit df.apply(pd.to_datetime, errors='coerce')
%timeit pd.to_datetime(df.stack(), errors='coerce').unstack()
%timeit pd.concat([pd.to_datetime(df[c], errors='coerce') for c in df], axis=1)
%timeit for c in df.columns: df[c] = pd.to_datetime(df[c], errors='coerce')
5.49 ms ± 247 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
3.94 ms ± 48.1 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
3.16 ms ± 216 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
2.41 ms ± 1.71 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
文字列の操作やカテゴリへの変換など、他の操作についても同様のケースを作ることができる。
u = df.apply(lambda x: x.str.contains(...))
v = df.apply(lambda x: x.astype(category))
v/s
u = pd.concat([df[c].str.contains(...) for c in df], axis=1)
v = df.copy()
for c in df:
v[c] = df[c].astype(category)
などなど・・・。
シリーズを変換する
str
:
astype
対
apply
これはAPIの特質のような気がします。使用方法
apply
を使用してシリーズ内の整数を文字列に変換するのと同等(場合によってはより速い)です。
astype
.
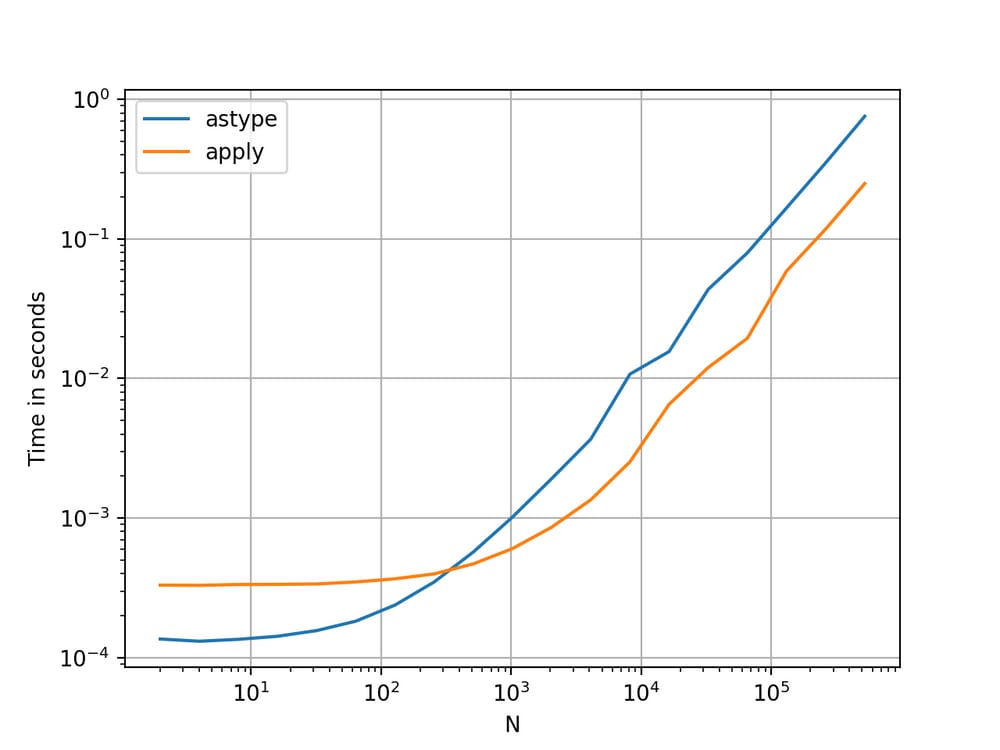 を使用してグラフをプロットした。
を使用してグラフをプロットした。
perfplot
ライブラリを使用します。
import perfplot
perfplot.show(
setup=lambda n: pd.Series(np.random.randint(0, n, n)),
kernels=[
lambda s: s.astype(str),
lambda s: s.apply(str)
],
labels=['astype', 'apply'],
n_range=[2**k for k in range(1, 20)],
xlabel='N',
logx=True,
logy=True,
equality_check=lambda x, y: (x == y).all())
フロートでは
astype
と同等か、わずかに速い程度です。
apply
. これは、テストのデータが整数型であることと関係があるんですね。
GroupBy
連鎖したトランスフォームを用いた操作
GroupBy.apply
は今まで議論されてきませんでしたが
GroupBy.apply
はまた、既存の
GroupBy
関数にはない。
よくある要件としては、GroupByを実行した後に、"lagged cums"などの2つの主要な演算を実行することです。
df = pd.DataFrame({"A": list('aabcccddee'), "B": [12, 7, 5, 4, 5, 4, 3, 2, 1, 10]})
df
A B
0 a 12
1 a 7
2 b 5
3 c 4
4 c 5
5 c 4
6 d 3
7 d 2
8 e 1
9 e 10
<!- ->
ここでは、groupbyを2回連続して呼び出す必要があります。
df.groupby('A').B.cumsum().groupby(df.A).shift()
0 NaN
1 12.0
2 NaN
3 NaN
4 4.0
5 9.0
6 NaN
7 3.0
8 NaN
9 1.0
Name: B, dtype: float64
使用方法
apply
というように、一回の呼び出しで短縮することができます。
df.groupby('A').B.apply(lambda x: x.cumsum().shift())
0 NaN
1 12.0
2 NaN
3 NaN
4 4.0
5 9.0
6 NaN
7 3.0
8 NaN
9 1.0
Name: B, dtype: float64
性能はデータに依存するため、数値化するのは非常に難しいです。しかし、一般的には
apply
を減らすことが目的であれば、許容できる解決策です。
groupby
を呼び出すことができます(なぜなら
groupby
もかなり高いです)。
その他の注意事項
上記の注意点とは別に、以下の点についても言及する必要があります。
apply
は最初の行(または列)に対して2回操作します。これは、この関数に副作用があるかどうかを判断するために行われます。そうでない場合は
apply
は結果の評価に高速なパスを使えるかもしれませんし、そうでなければ低速な実装にフォールバックします。
df = pd.DataFrame({
'A': [1, 2],
'B': ['x', 'y']
})
def func(x):
print(x['A'])
return x
df.apply(func, axis=1)
# 1
# 1
# 2
A B
0 1 x
1 2 y
この動作は
GroupBy.apply
をpandasのバージョン<0.25で修正しました。
詳しくはこちら
.)
関連
-
PythonはWordの読み書きの変更操作を実装している
-
Evidentlyを用いたPythonデータマイニングによる機械学習モデルダッシュボードの作成
-
[解決済み】 AttributeError: モジュール 'matplotlib' には属性 'plot' がない。
-
[解決済み】ImportError: bs4という名前のモジュールがない(BeautifulSoup)
-
[解決済み] Pythonのdictsで'has_key()'と'in'のどちらを使うべきですか?
-
[解決済み] INNER JOINよりもCROSS APPLYを使用すべきなのはどのような場合ですか?
-
[解決済み] Pandasのデータフレームから行を選択するために値のリストを使用する
-
[解決済み] PandasのデータフレームをSQLのように'in'と'not in'でフィルタリングする方法
-
[解決済み] Pandasのmap、applymap、applyメソッドの違い
-
[解決済み] pandas が他の列の値に基づいて新しい列を作成する / 複数の列の関数を行単位で適用する
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
ピロウズ画像色処理の具体的な活用方法
-
Python LeNetネットワークの説明とpytorchでの実装
-
Pythonの画像ファイル処理用ライブラリ「Pillow」(グラフィックの詳細)
-
[解決済み】RuntimeWarning: 割り算で無効な値が発生しました。
-
[解決済み】django インポートエラー - core.managementという名前のモジュールがない
-
[解決済み] pandas DataFrameのカラムを複数行にアンネスト(分解)する方法
-
[解決済み] PandasでDataFrameの行を反復処理する方法
-
[解決済み] Pandasのmap、applymap、applyメソッドの違い
-
[解決済み] apply()関数を1つの列に対して使用するにはどうすればよいですか?
-
[解決済み】複数のカラムを参照するPandasの「apply」関数が動作しないのはなぜですか?[クローズド]