[解決済み] Pandas マージ入門
質問
-
を実行するにはどうすればよいのでしょうか?
INNER| (LEFT|RIGHT|FULL)OUTER)JOINパンダと? - マージの後、欠落した行のために NaN を追加するにはどうすればよいですか?
- マージ後にNaNを取り除くにはどうすればよいですか?
- インデックス上でのマージは可能ですか?
- 複数のDataFrameをマージするにはどうすればよいですか?
- pandasを使ったクロスジョイン
-
merge?join?concat?update? 誰?何?どうして!?
...などなど。pandasのmerge機能の様々な側面について質問する、このような繰り返しの質問を見かけました。マージとその様々な使用例に関する情報のほとんどは、多くの悪い言葉で書かれた検索不可能な投稿に断片化されています。ここでは、後世に伝えるために、より重要なポイントをいくつかまとめてみました。
このQ&Aは、pandasの一般的なイディオムに関する有用なユーザーガイドの次の回を意図しています( ピボットの記事 と この記事は連結についてです については、後ほど触れる予定です)。
なお、この投稿は ではなく の代わりとなるものです。 ドキュメント ということで、そちらもお読みください。いくつかの例は、そこから引用しています。
目次
<サブ アクセスしやすいように
-
マージの基本 - 基本的な結合の種類 (最初にこちらをお読みください)
解決方法は?
この投稿は、Pandasを使ったSQL風味のマージについて、どのように使うか、そしてどのような場合に使わないかを読者に紹介することを目的としています。
具体的には、この記事では以下のような流れになります。
-
基本 - ジョインの種類 (LEFT, RIGHT, OUTER, INNER)
- 異なるカラム名でのマージ
- 複数列のマージ
- 出力におけるマージキー列の重複を回避する。
この投稿(このスレッドでの私の他の投稿も)がスルーされること。
- 性能に関する議論とタイミング(今のところ)。主に、より良い代替品について、適切な場所で注目すべき言及。
- サフィックスの処理、余分な列の削除、出力の名前変更、その他特定のユースケース。これについては、他の(より良い)記事がありますので、そちらを参照してください。
備考 ほとんどの例では、特に指定がない限り、さまざまな機能をデモンストレーションする際に INNER JOIN 操作をデフォルトで使用します。
さらに、ここにあるすべてのDataFrameはコピーして複製することができますので で遊べます。また この ポスト は、クリップボードからDataFrameを読み込む方法です。
最後に、JOIN操作のビジュアル表現はすべてGoogle Drawingsを使用して手描きで行っています。インスピレーションの源 こちら .
もういい、使い方を教えてくれ
merge
!
セットアップ&ベーシック
np.random.seed(0)
left = pd.DataFrame({'key': ['A', 'B', 'C', 'D'], 'value': np.random.randn(4)})
right = pd.DataFrame({'key': ['B', 'D', 'E', 'F'], 'value': np.random.randn(4)})
left
key value
0 A 1.764052
1 B 0.400157
2 C 0.978738
3 D 2.240893
right
key value
0 B 1.867558
1 D -0.977278
2 E 0.950088
3 F -0.151357
簡略化のため、キーカラムは(今のところ)同じ名前にしています。
An INNER JOIN は次のように表されます。
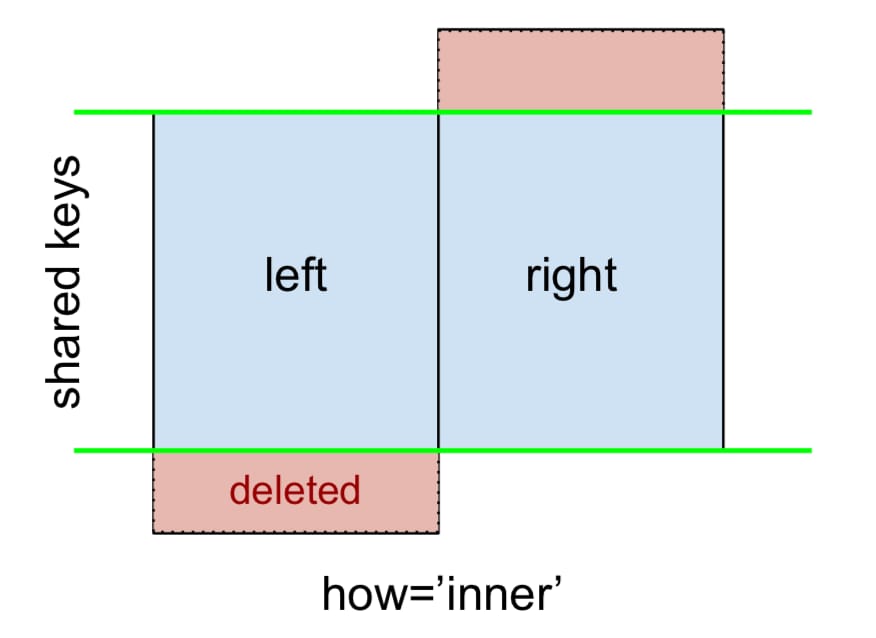
備考 これと、これから発表される図表は、すべてこの規約に従ったものです。
- 青 は、マージ結果に存在する行を示します。
- 赤 は結果から除外される(削除される)行を示す
- グリーン は欠落している値を示しており、その値は
NaNを表示します。
INNER JOIN を実行するには、次のようにします。
merge
に、右側のデータフレームと結合キー(最低限)を引数として指定します。
left.merge(right, on='key')
# Or, if you want to be explicit
# left.merge(right, on='key', how='inner')
key value_x value_y
0 B 0.400157 1.867558
1 D 2.240893 -0.977278
の行のみを返します。
left
と
right
で、共通のキー(この例では、"B" と "D)を持つもの。
A 左外部結合 またはLEFT JOINは次のように表されます。
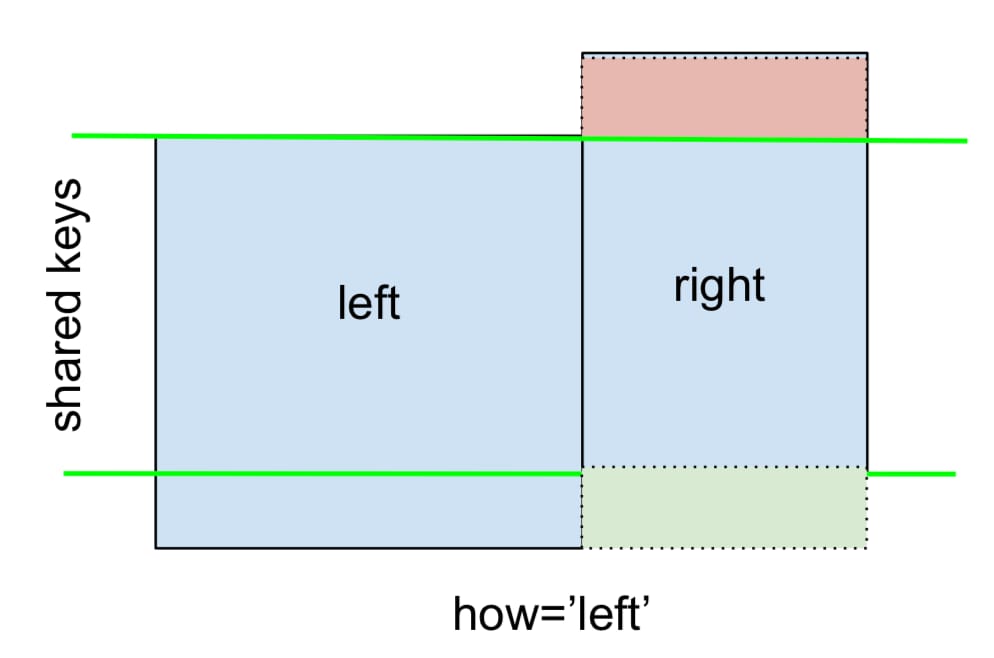
を指定することで実行できます。
how='left'
.
left.merge(right, on='key', how='left')
key value_x value_y
0 A 1.764052 NaN
1 B 0.400157 1.867558
2 C 0.978738 NaN
3 D 2.240893 -0.977278
ここでは、NaNの配置に注意してください。もし
how='left'
のキーのみとなります。
left
が使用され、欠損データは
right
はNaNに置き換えられる。
また、同様に 右外部結合 またはRIGHT JOINは...です。
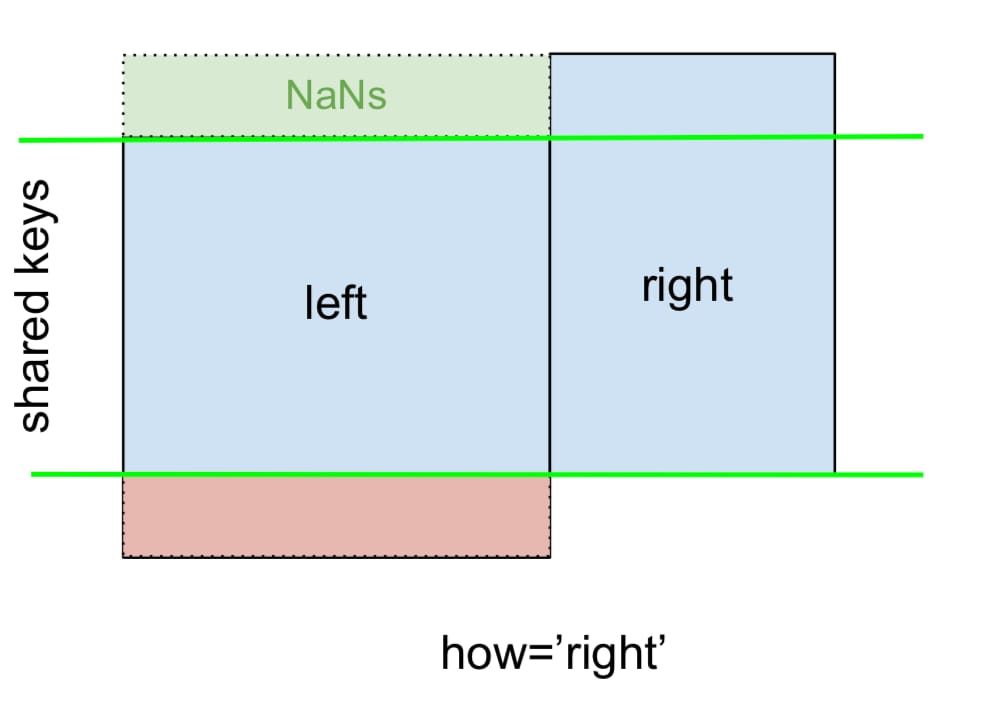
...指定
how='right'
:
left.merge(right, on='key', how='right')
key value_x value_y
0 B 0.400157 1.867558
1 D 2.240893 -0.977278
2 E NaN 0.950088
3 F NaN -0.151357
ここでは
right
が使用され、欠損データは
left
はNaNに置き換えられる。
最後に 完全外部結合 で与えられる。
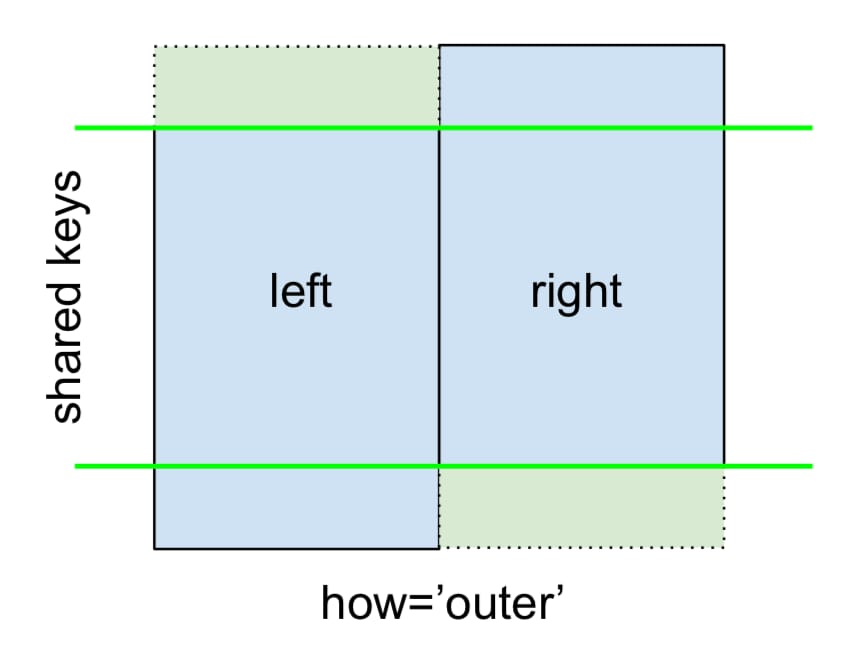
指定する
how='outer'
.
left.merge(right, on='key', how='outer')
key value_x value_y
0 A 1.764052 NaN
1 B 0.400157 1.867558
2 C 0.978738 NaN
3 D 2.240893 -0.977278
4 E NaN 0.950088
5 F NaN -0.151357
これは、両方のフレームのキーを使用し、両方の行がない場合はNaNが挿入されます。
ドキュメントには、これらの様々なマージがうまくまとめられている。

その他のJOIN - LEFT-Excluding、RIGHT-Excluding、FULL-Excluding/ANTI JOIN
必要な場合 LEFT-Excluding JOINs(左排他的論理和 と RIGHT-除外JOINs を2ステップで実行します。
LEFT-Excluding JOINの場合、次のように表されます。
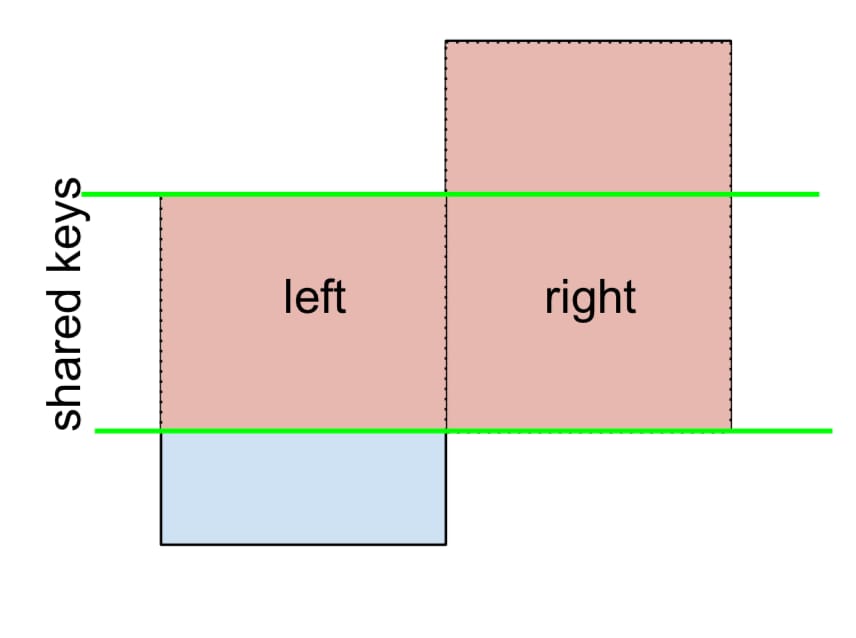
LEFT OUTER JOIN を実行し、次の行をフィルタリング(除外!)します。
left
のみです。
(left.merge(right, on='key', how='left', indicator=True)
.query('_merge == "left_only"')
.drop('_merge', 1))
key value_x value_y
0 A 1.764052 NaN
2 C 0.978738 NaN
どこで
left.merge(right, on='key', how='left', indicator=True)
key value_x value_y _merge
0 A 1.764052 NaN left_only
1 B 0.400157 1.867558 both
2 C 0.978738 NaN left_only
3 D 2.240893 -0.977278 both
そして同様に、RIGHT-Excluding JOINの場合。
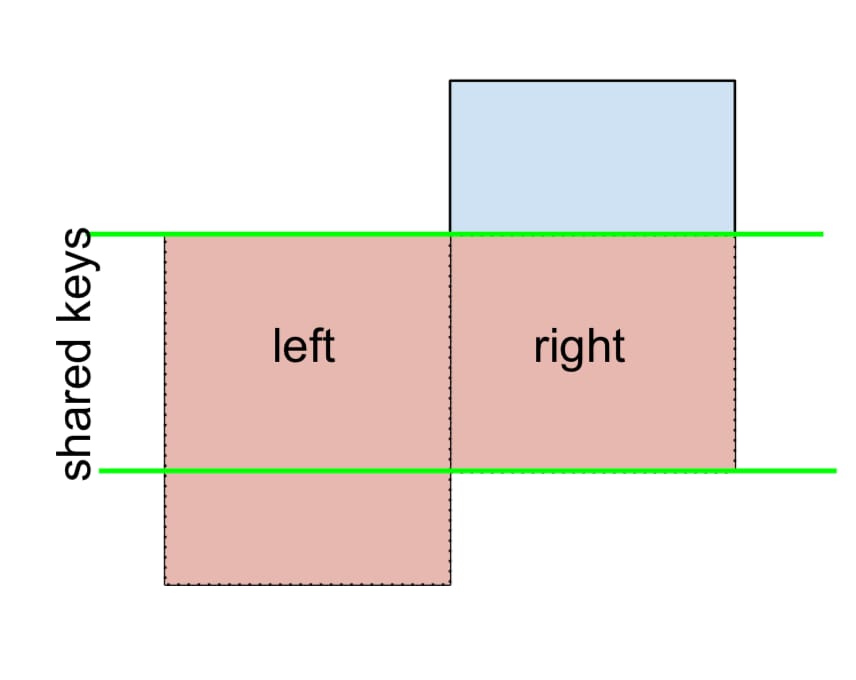
(left.merge(right, on='key', how='right', indicator=True)
.query('_merge == "right_only"')
.drop('_merge', 1))
key value_x value_y
2 E NaN 0.950088
3 F NaN -0.151357
最後に、左または右のキーのみを保持し、両方を保持しないマージを行う必要がある場合 (つまり アンチジョイン ),
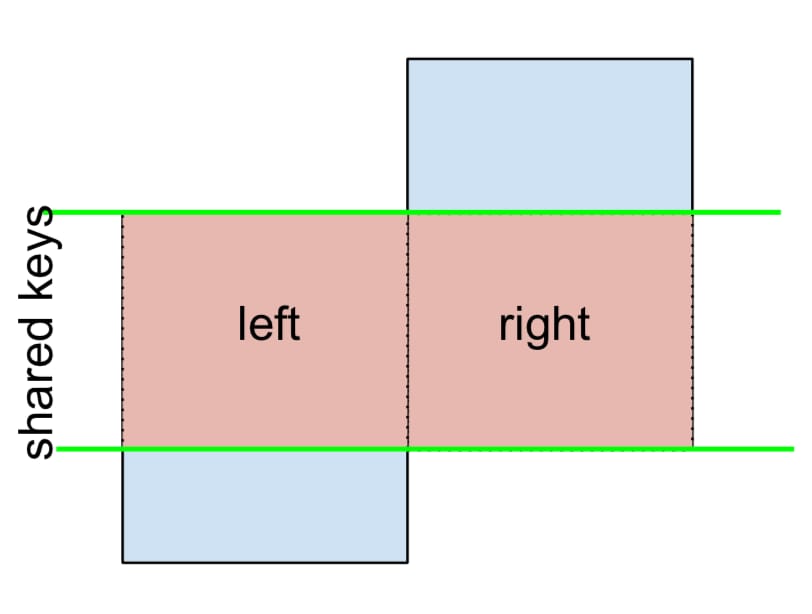
同様の方法で行うことができます。
(left.merge(right, on='key', how='outer', indicator=True)
.query('_merge != "both"')
.drop('_merge', 1))
key value_x value_y
0 A 1.764052 NaN
2 C 0.978738 NaN
4 E NaN 0.950088
5 F NaN -0.151357
キーカラムの異なる名称
キーとなるカラムの名前が異なる場合、例えば、以下のようになります。
left
は
keyLeft
であり、かつ
right
があります。
keyRight
の代わりに
key
-を指定する必要があります。
left_on
と
right_on
の代わりに引数として
on
:
left2 = left.rename({'key':'keyLeft'}, axis=1)
right2 = right.rename({'key':'keyRight'}, axis=1)
left2
keyLeft value
0 A 1.764052
1 B 0.400157
2 C 0.978738
3 D 2.240893
right2
keyRight value
0 B 1.867558
1 D -0.977278
2 E 0.950088
3 F -0.151357
left2.merge(right2, left_on='keyLeft', right_on='keyRight', how='inner')
keyLeft value_x keyRight value_y
0 B 0.400157 B 1.867558
1 D 2.240893 D -0.977278
出力におけるキーカラムの重複を回避する
でマージする場合
keyLeft
から
left
と
keyRight
から
right
のどちらか一方だけが必要な場合は
keyLeft
または
keyRight
(両方は不可) を出力する場合、前段階としてインデックスを設定することから始めることができます。
left3 = left2.set_index('keyLeft')
left3.merge(right2, left_index=True, right_on='keyRight')
value_x keyRight value_y
0 0.400157 B 1.867558
1 2.240893 D -0.977278
直前のコマンドの出力と対比してください。
left2.merge(right2, left_on='keyLeft', right_on='keyRight', how='inner')
を実行すると
keyLeft
が抜けています。どのフレームのインデックスがキーとして設定されているかで、どのカラムを保持するかを把握することができます。これは、例えば、何らかのOUTER JOIN操作を行う際に重要になるかもしれません。
の1つから1つのカラムだけをマージする。
DataFrames
例えば、次のように考えます。
right3 = right.assign(newcol=np.arange(len(right)))
right3
key value newcol
0 B 1.867558 0
1 D -0.977278 1
2 E 0.950088 2
3 F -0.151357 3
もし、quot;new_val"のみをマージする必要がある場合(他の列を含まない)、通常はマージの前に列をサブセットするだけでよいでしょう。
left.merge(right3[['key', 'newcol']], on='key')
key value newcol
0 B 0.400157 0
1 D 2.240893 1
LEFT OUTER JOINを行う場合、よりパフォーマンスの高いソリューションとして、以下のようになります。
map
:
# left['newcol'] = left['key'].map(right3.set_index('key')['newcol']))
left.assign(newcol=left['key'].map(right3.set_index('key')['newcol']))
key value newcol
0 A 1.764052 NaN
1 B 0.400157 0.0
2 C 0.978738 NaN
3 D 2.240893 1.0
前述したように、これは
left.merge(right3[['key', 'newcol']], on='key', how='left')
key value newcol
0 A 1.764052 NaN
1 B 0.400157 0.0
2 C 0.978738 NaN
3 D 2.240893 1.0
複数列でのマージ
複数のカラムで結合する場合は
on
(または
left_on
と
right_on
を、適宜追加してください)。
left.merge(right, on=['key1', 'key2'] ...)
または、名前が異なる場合。
left.merge(right, left_on=['lkey1', 'lkey2'], right_on=['rkey1', 'rkey2'])
その他の便利な機能
merge*
操作・機能
-
DataFrameとSeriesをindexでマージする。参照 この回答 .
-
その他
merge,DataFrame.updateそしてDataFrame.combine_firstは、あるデータフレームを別のデータフレームで更新する場合にも使用されます。 -
pd.merge_orderedは、順序付きJOINのための便利な関数です。 -
pd.merge_asof(読み: merge_asOf) は次のような場合に便利です。 きんじ を結合します。
ここでは、あくまで基本的なことを説明し、食欲をそそるような内容になっています。その他の例や事例については
ドキュメンテーション
merge
,
join
そして
concat
と機能仕様へのリンクがあります。
続きを読む
Pandas Merging 101 の他のトピックにジャンプして、学習を続けることができます。
<サブ *あなたはここにいます。
関連
-
PythonはWordの読み書きの変更操作を実装している
-
[解決済み] PandasでDataFrameの行を反復処理する方法
-
[解決済み] Pandasのカラム名のリネーム
-
[解決済み] Pandas DataFrameからカラムを削除する
-
[解決済み] Pandasのデータフレームで複数の列を選択する
-
[解決済み] Pandas DataFrameの行数を取得する方法は?
-
[解決済み] 既存のDataFrameに新しい列を追加する方法は?
-
[解決済み] pandasを使った "大量データ "ワークフロー【終了しました
-
[解決済み】Pandas DataFrameのカラムヘッダからリストを取得する。
-
[解決済み】pandasでカラムの種類を変更する
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
Python 人工知能 人間学習 描画 機械学習モデル作成
-
Python jiabaライブラリの使用方法について説明
-
Python 可視化 big_screen ライブラリ サンプル 詳細
-
任意波形を生成してtxtで保存するためのPython実装
-
[解決済み】Pythonスクリプトで「Expected 2D array, got 1D array instead: 」というエラーが発生?
-
[解決済み】Pythonでgoogle APIのJSONコードを読み込むとエラーになる件
-
[解決済み】ImportError: bs4という名前のモジュールがない(BeautifulSoup)
-
[解決済み】NameError: 名前 'self' が定義されていません。
-
[解決済み】「OverflowError: Python int too large to convert to C long" on windows but not mac
-
[解決済み】Python - "ValueError: not enough values to unpack (expected 2, got 1)" の修正方法 [閉店].