[解決済み] numpyをインポートすると、マルチプロセシングがシングルコアになるのはなぜですか?
質問
私は、これが OS の問題としてカウントされるかどうかわかりませんが、誰かが物事の Python 側からいくつかの洞察を持っている場合に備えて、ここで質問してみようと思いました。
私はCPUに負荷のかかる
for
ループを
joblib
しかし、各ワーカー プロセスが異なるコアに割り当てられるのではなく、すべてのワーカー プロセスが同じコアに割り当てられてしまい、パフォーマンスが向上しないことがわかりました。
これは非常につまらない例ですが...。
from joblib import Parallel,delayed
import numpy as np
def testfunc(data):
# some very boneheaded CPU work
for nn in xrange(1000):
for ii in data[0,:]:
for jj in data[1,:]:
ii*jj
def run(niter=10):
data = (np.random.randn(2,100) for ii in xrange(niter))
pool = Parallel(n_jobs=-1,verbose=1,pre_dispatch='all')
results = pool(delayed(testfunc)(dd) for dd in data)
if __name__ == '__main__':
run()
...そして、以下は
htop
に表示されます。
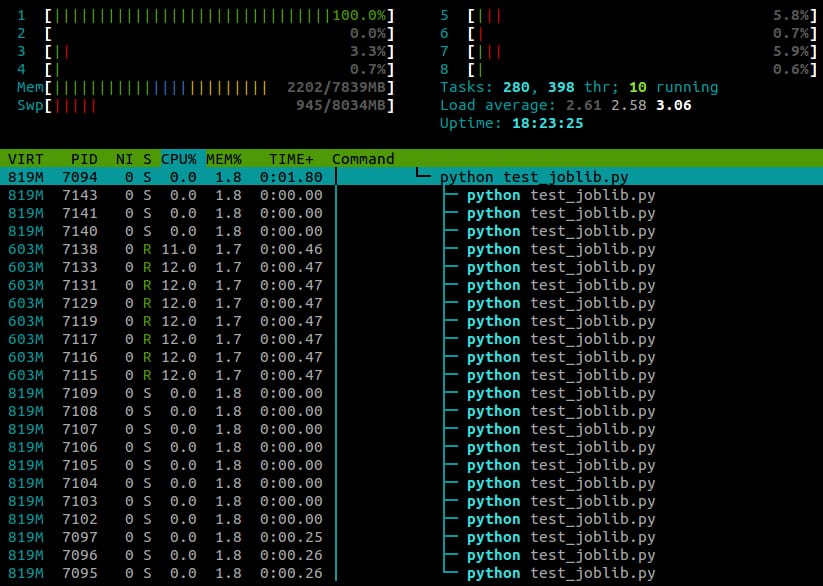
私は、Ubuntu 12.10 (3.5.0-26) を 4 コアのラップトップで実行しています。はっきりと
joblib.Parallel
は異なるワーカーのために別々のプロセスを生成していますが、これらのプロセスを異なるコアで実行させる方法はありますか?
どのように解決するのですか?
さらにググってみると、次のような答えが見つかりました。 ここで .
ある種の Python モジュール (
numpy
,
scipy
,
tables
,
pandas
,
skimage
...) は、インポート時にコア・アフィニティーを混乱させます。私が知る限り、この問題は、マルチスレッドのOpenBLASライブラリに対してリンクすることで特に発生するようです。
回避策は、タスクアフィニティをリセットすることです。
os.system("taskset -p 0xff %d" % os.getpid())
この行をモジュールのインポートの後に貼り付けると、私のサンプルはすべてのコアで動作するようになります。
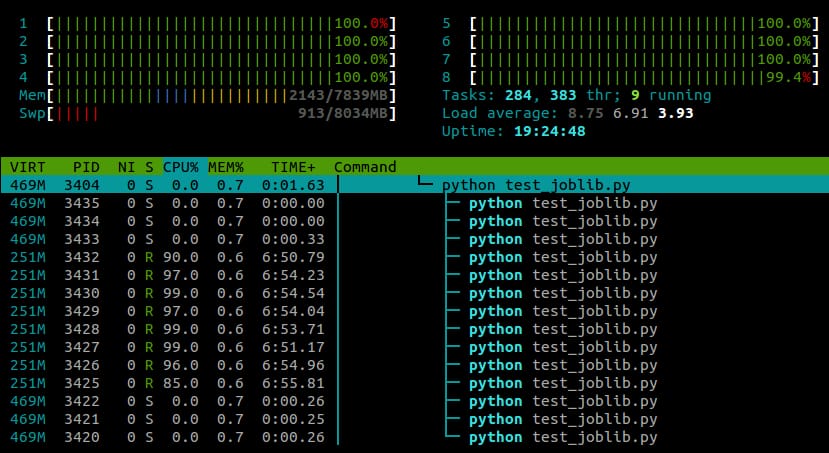
私のこれまでの経験では、これは
numpy
のパフォーマンスに悪影響を与えていないように見えますが、これはおそらくマシンやタスクに特有のものでしょう。
更新しました。
また、OpenBLAS自体のCPUアフィニティリセットの動作を無効にする方法が2つあります。実行時に、環境変数
OPENBLAS_MAIN_FREE
(または
GOTOBLAS_MAIN_FREE
) のように、例えば
OPENBLAS_MAIN_FREE=1 python myscript.py
あるいは、OpenBLASをソースからコンパイルする場合は、ビルド時に
Makefile.rule
を編集して、次の行を含むようにします。
NO_AFFINITY=1
関連
-
Python Decorator 練習問題
-
Python 人工知能 人間学習 描画 機械学習モデル作成
-
Python カメの描画コマンドとその例
-
任意波形を生成してtxtで保存するためのPython実装
-
Pythonの@decoratorsについてまとめてみました。
-
PythonでECDSAを実装する方法 知っていますか?
-
[解決済み】OSError: [WinError 193] %1 は有効な Win32 アプリケーションではありません。
-
[解決済み】LogisticRegression: Pythonでsklearnを使用して、未知のラベルタイプ: '連続'を使用しています。
-
[解決済み】NameError: 名前 'self' が定義されていません。
-
[解決済み] なぜpythonはforやwhileループの後に'else'を使うのですか?
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
ピロウズ画像色処理の具体的な活用方法
-
PythonはWordの読み書きの変更操作を実装している
-
[解決済み] データ型が理解できない
-
[解決済み】TypeError: re.findall()でバイトのようなオブジェクトに文字列パターンを使用することはできません。)
-
[解決済み】csv.Error:イテレータはバイトではなく文字列を返すべき
-
[解決済み】TypeError: 系列を <class 'float'> に変換することができません。
-
[解決済み】「SyntaxError.Syntax」は何ですか?Missing parentheses in call to 'print'」はPythonでどういう意味ですか?
-
[解決済み】「OverflowError: Python int too large to convert to C long" on windows but not mac
-
[解決済み】Python - "ValueError: not enough values to unpack (expected 2, got 1)" の修正方法 [閉店].
-
[解決済み】django インポートエラー - core.managementという名前のモジュールがない