MySQL上級SQLステートメント
2022-02-21 02:48:39
MySQLの高度なSQLステートメント
MySQLの高度なSQLステートメント
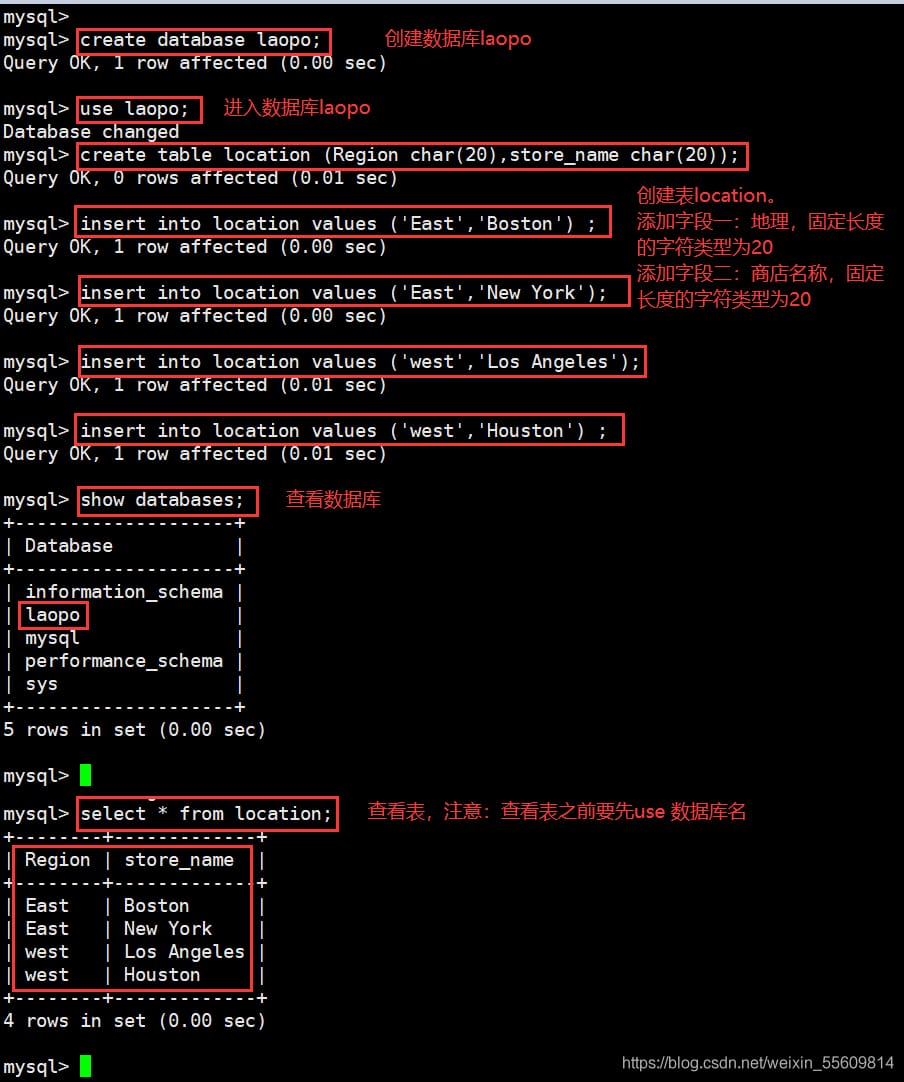
use kgc;
create table location (Region char(20),store_name char(20));
insert into location values ('East','Boston') ;
insert into location values ('East','New York'); insert into location values ('East','New York');
insert into location values ('west','Los Angeles');
insert into location values ('west','Houston') ;
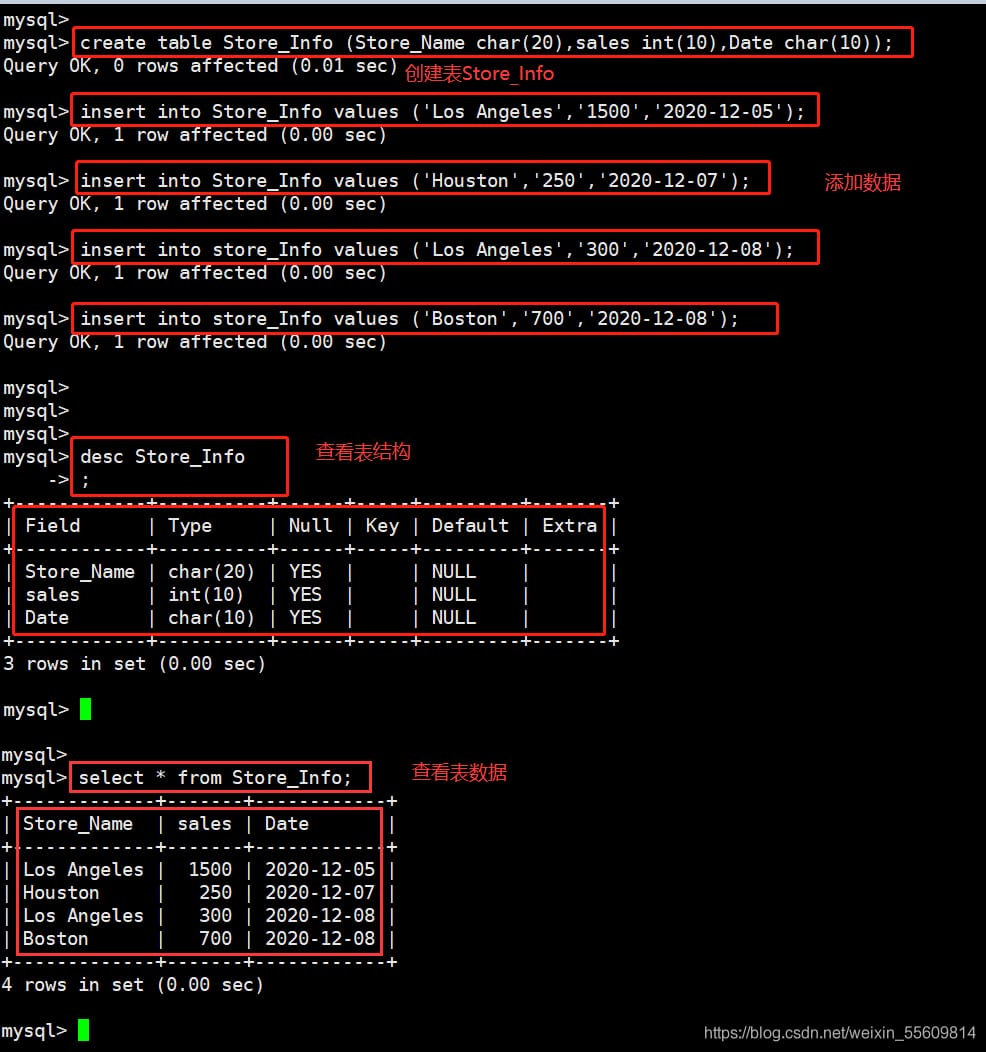
create table Store_Info (Store_Name char(20),sales int(10),Date char(10));
insert into Store_Info values ('Los Angeles','1500','2020-12-05');
insert into Store_Info values ('Houston','250','2020-12-07'); insert into Store_Info values ('Houston','250','2020-12-07');
insert into Store_Info values ('Los Angeles','300','2020-12-08'); insert into Store_Info values ('Los Angeles','300','2020-12-08');
insert into Store_Info values ('Boston','700','2020-12-08');
---- SELECT ---- displays all information in one or more columns of a table
Syntax: SELECT "Columns" FROM "Table Name";
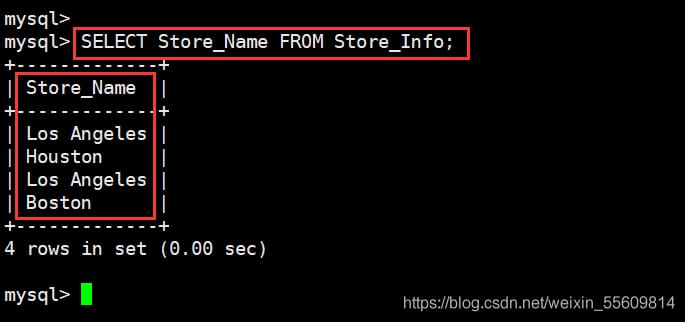
SELECT Store_Name FROM Store_Info;
---- DISTINCT ---- Do not display duplicates
Syntax: SELECT DISTINCT "Columns" FROM "Table Name";
SELECT DISTINCT Store_Name FROM Store_Info;
---- WHERE ---- conditional query
Syntax:SELECT "Column" FROM "Table Name" WHERE "Condition";
SELECT Store_Name FROM Store_Info WHERE Sales > 1000;
---- AND OR ---- AND OR
Syntax:SELECT "Column" FROM "Table Name" WHERE "Condition 1" {[ANDIOR] "Condition 2"}+;
SELECT Store_Name FROM Store_Info WHERE Sales > 1000 OR (Sales < 500 AND Sales > 200);
---- IN ---- Display information for known values
Syntax: SELECT "Column" FROM "Table Name" WHERE "Column" IN ('Value1','Value2', ...) ;
SELECT * FROM Store_Info WHERE Store_Name IN ('Los Angeles','Houston');
---- BETWEEN ---- Display information in a range of two values
Syntax:SELECT "Column" FROM "Table Name" WHERE "Column" BETWEEN 'Value 1' AND 'Value 2';
SELECT * FROM Store_Info WHERE Date BETWEEN '2020-12-06' AND '2020-12-10';
---- Wildcard ---- Usually wildcards are used in conjunction with LIKE
% : percent sign for zero, one or more characters
_ : underscore for a single character
'A_Z':All strings that start with 'A', another character of any value, and end with 'Z'. For example, 'A.BZ' and 'A.22' both fit this one pattern, while 'AKK2' does not (because there are two characters between A and Z, not one).
'ABC%':All strings that start with 'ABC'. For example, 'ABCD' and 'ABCABC' both match this pattern.
'%XYZ':All strings that end with 'XYZ'. For example, 'WXYZ' and 'ZZXYZ' both match this pattern.
'%AN%':All strings that contain the pattern 'AN'. For example, 'LOS ANGELES' and 'SAN FRANCISCO' both match this pattern.
'_AN%':All strings with the second letter 'A' and the third letter 'N'. For example, 'SAMN FRANCITSCO' matches this pattern, while 'LOS ANGELES' does not.
---- LIKE ---- matches a pattern to find the information we want
Syntax:SELECT "COLUMNS" FROM "TABLE_NAME" WHERE "COLUMNS" LIKE {pattern};
SELECT * FROM Store_Info WHERE Store_Name like '%os%';
---- ORDER BY ---- Sort by keyword
Syntax:SELECT "Columns" FROM "Table_Name" [WHERE "Condition"] ORDER BY "Columns" [ASC, DESC];
#ASC is sorted in ascending order, which is the default sorting method.
#DESC is sorted in descending order.
SELECT Store_Name,Sales,Date FROM Store_Info ORDER BY Sales DESC;
abs(x) #returns the absolute value of x
rand() #returns a random number from 0 to 1
mod(x,y) #returns the remainder of x divided by y
power(x,y) # return to the yth power of x
round(x) # return the nearest integer to x
round(x,y) # retain the y decimal places of x after rounding the value
sqrt(x) # return to the square root of x
truncate(x,y) # return the number x truncated to y decimal values
ceil(x) # return greater than or equal to x the smallest integer
floor(x) # return less than or equal to x the largest integer
greatest(x1,x2...) # return the largest value in the set
least(x1,x2...) # return the smallest value in the set
SELECT abs(-1),rand(),mod(5,3),power(2,3),round(1.89);
SELECT round(1.8937,3),truncate(1.235,2),ceil(5.2),floor(2.1),last(1.89,3,6.1,2.1);
The aggregation function :
avg() #returns the average of the specified columns
count() # return the number of non-NULL values in the specified column
min() #returns the minimum value of the specified column
max() # return the maximum value of the specified column
sum(x) # return the sum of all values of the specified column
SELECT avg(Sales) FROM Store_Info;
SELECT count(store_Name) FROM Store_Info;
SELECT count(DISTINCT store_Name) FROM Store_Info;
SELECT max(Sales) FROM Store_Info;
SELECT min(sales) FROM Store_Info;
SELECT sum(sales) FROM Store_Info;
SELECT count(DISTINCT store_Name) FROM Store_Info;
SELECT count(*) FROM Store_Info;
#count(*) includes the number of rows of all columns and does not ignore the NULL value when counting the results
#count(*) includes only the number of rows in the column with the column name, and will ignore rows with NULL values when counting results
The string function :
trim() #returns the value with the specified format removed
concat(x,y) # splice the supplied parameters x and y into a string
substr(x,y) # get the string from the yth position in the string x, the same function as substring()
substr(x,y,z) # get the string from the yth position in the string x the length of the string z
length(x) # return the length of the string x
replace(x,y,z) # replace the string z with the string y in the string x
upper(x) # will be all letters of the string x into uppercase letters
lower(x) # will be all letters of the string x into lowercase letters
left(x,y) # return the first y characters of the string x
right(x,y) # return to the string x after the y characters
repeat(x,y) # will repeat the string x y times
space(x) # return x spaces
strcmp (x,y) #compare x and y, the return value can be -1,0,1
reverse(x) # reverse the string x
SELECT concat(Region,Store_Name) FROM location WHERE Store_Name = 'Boston';
#If sql_mode is turned on with PIPES_AS_CONCAT on, "||" is considered a concatenation operator instead of an or operator, similar to the concatenation function concat, which is used in the same way as the Oracle database
SELECT Region || ' ' || Store_Name FROM location WHERE Store_Name = 'Boston';
SELECT substr(Store_Name,3) FROM location WHERE Store_Name = 'Los Angeles';
SELECT substr(Store_Name,2,4) FROM location WHERE Store_Name = 'New York';
SELECT TRIM ([ [location] [string to remove] FROM ] string);
#[location]: The values can be LEADING (start), TRAILING (end), BOTH (start and end).
#[string to be removed]: the string to be removed from the beginning, the end, or the beginning and the end of the string. By default, it is a space
SELECT TRIM(LEADING 'Ne' FROM 'New York');
SELECT Region,length(Store_Name) FROM location;
SELECT REPLACE(Region,'ast','east') FROM location;
---- GROUP BY ---- aggregates and groups the results of queries in the columns following GROUP BY, usually in conjunction with the aggregation function
GROUP BY has a principle that all columns following SELECT that do not use the aggregation function must appear after GROUP BY.
Syntax:SELECT "Column1",SUM("Column2") FROM "TableName" GROUP BY "Column1";
SELECT Store_Name,SUM(Sales) FROM Store_Info GROUP BY Store_Name ORDER BY sales desc;
---- HAVING ---- is used to filter the set of records returned by the GROUP BY statement and is usually used in conjunction with the GROUP BY statement
The existence of the HAVING statement makes up for the fact that the wHERE keyword cannot be used in conjunction with aggregate functions. If the only column being SELECcT is the function column, then the GROUP BY clause is not needed.
Syntax:SELECT "Column1",SUM("Column2") FROM "TableName" GROUP BY "Column1" HAVING (function condition);
SELECT Store_Name,SUM(Sales) FROM Store_Info GROUP BY Store_Name HAVING SUM (Sales) > 1500;
---- alias ---- column alias table alias
Syntax:SELECT "Table Alias". "Column 1" [AS] "Column Alias" FROM "Table Name" [AS] "Table Alias"
SELECT A.Store_Name Store, SUM(A.Sales) "Total Sales" FROM Store_Info A GROUP BY A.Store_Name;
---- subquery ---- joins a table and inserts another SQL statement in the WHERE clause or HAVING clause
Syntax: SELECT "Column1" FROM "Table1" WHERE "Column2" [comparison operator] #external query
(SELECT "column1" FROM "table2" WHERE "condition"); #internal query
can be symbolic operators such as =, >, <, >=, <= ; or literal operators such as LIKE, IN, BETWEEN
SELECT SUM(Sales) FROM Store_Info WHERE Store_Name IN
(SELECT Store_Name FROM location WHERE Region = 'west');
SELECT SUM(A.Sales) FROM Store_Info A WHERE A.Store_Name IN
(SELECT Store_Name FROM location B WHERE B.Store_Name = A.Store_Name);
---- EXISTS ---- is used to test whether the inner query produces any results, similar to whether the Boolean value is true
#If so, the system will execute the SQL statement in the outer query. If it is not, then the whole SQL statement will not produce any result.
Syntax: SELECT "Column1" FROM "Form1" WHERE EXISTS (SELECT * FROM "Form2" WHERE "Condition");
SELECT SUM(Sales) FROM Store_Info WHERE EXISTS (SELECT * FROM location WHERE Region = 'West');
<イグ
UPDATE Store_Info SET store_name='washington' WHERE sales=300;
<イグ
セレクト
inner join (inner join): returns only the rows in the two tables whose join fields are equal
left join (left join): returns all rows in the left table that include all rows in the left table and those in the right table with equal join fields
right join(right join): return the rows that include all rows in the right table and the rows with equal join fields in the left table
SELECT * FROM location A INNER JOIN Store_Info B on A.Store_Name = B.store_Name ;
SELECT * FROM location A RIGHT JOIN Store_Info B on A.Store_Name = B.Store_Name ;
SELECT * FROM location A,store_Info B WHERE A.Store_Name = B.Store_Name;
SELECT A.REGION REGION,SUM(B.Sales) SALES FROM location A,Store_Info B
WHERE A.Store_Name = B.Store_Name GROUP BY REGION;
---- CREATE VIEW ---- A view can be thought of as a virtual table or a stored query.
-The difference between a view and a table is that a table has actual stored information, while a view is a structure built on top of a table that does not actually store information itself.
-Temporary tables disappear automatically when the user logs out or when the connection to the database is broken, while views do not disappear.
-A view does not contain data, it only stores its definition, and its purpose is generally to simplify complex queries. For example, if you want to query several tables, and also to perform statistical sorting and other operations, writing SQT statements will be very troublesome, use the view to link several tables, and then query operations on this view, just like a table query, very convenient.
Syntax: CREATE VIEW "depending on the table name" AS "SELECT statement ";
CREATE VIEW V_REGION_SALES AS SELECT A.REGION REGION, SUM(B.Sales) SALES FROM location A
INNER JOIN Store_Info B ON A.Store_Name = B.Store_Name GROUP BY REGION;
SELECT * FROM V_REGION_SALES;
DROP VIEW V_REGION_SALES;
---- UNION ---- union combines the results of two SQL statements, the fields generated by the two SQI statements need to be of the same data type
UNION: The resulting data values will have no duplicates and will be sorted in the order of the fields
Syntax: [SELECT statement 1] UNION [SELECT statement 2];
UNION ALL: lists all the data values of the generated results, regardless of duplicates
Syntax:[SELECT statement 1] UNION ALL [SELECT statement 2];
SELECT Store_Name FROM location UNION SELECT Store_Name FROM Store_Info;
SELECT Store_Name FROM location UNION ALL SELECT Store_Name FROM Store_Info;
----- intersection value ---- takes the intersection of the results of two SQL statements
SELECT A.Store_Name FROM location A INNER JOIN Store_Info B ON A.Store_Name = B.Store_Name;
SELECT A.Store_Name FROM location A INNER JOIN Store_Info B USING(Store_Name);
#If one of the two table bases does not have the specified row, and the other table has a duplicate row, and does have an intersection, use
SELECT A.Store_Name FROM
(SELECT Store_Name FROM location UNION ALL SELECT Store_Name FROM store_Info) A
GROUP BY A.Store_Name HAVING COUNT(*) > 1;
# Take the intersection of the results of two sQL statements, and no duplicates
SELECT A.Store_Name FRONM (SELECT B.Store_Name FROM location B INNER JOIN Store_Info C ON B.Store_Name = C.store_Name) A
GROUP BY A.Store_Name;
SELECT DISTINCT A.Store_Name FROM location A INNER JOIN Store_Info B USING(Store_Name);
SELECT DISTIMCT Store_Name FROM location WHERE (Store_Name) IN (SELECT Store_Name FROM Store_Info);
SELECT DISTINCT A.Store_Name FROM location A LEFT JOIN Store_Info B USING(Store_Name) WHERE B.Store_Name IS NOT NULL;
---- No intersection values ---- shows the result of the first sQL statement that does not intersect with the second SQL statement and is not duplicated
SELECT DISTINCT Store_Name FROM location WHERE (Store_Name) NOT IN (SELECT Store_Name FROM Store_Info);
SELECT DISTINCT A.Store_Name FROM location A LEFT JOIN Store_Info B USING(Store_Name) WHERE B.Store_Name IS NULL;
---- CASE ---- is a keyword used by SQL for IF-THEN-ELSE type logic
syntax:
SELECT CASE ("field name")
WHEN "Condition 1" THEN "Result 1"
WHEN "condition2" THEN "result2"
...
[ELSE "Result N"]
END
FROM "Table name";
#The ELSE clause is not required.
SELECT store_Name, CASE Store_Name
WHEN 'Los Angeles' THEN Sales * 2
WHEN 'Boston' THEN Sales * 1.5
ELSE Sales
END
"New Sales",Date
FROM Store_Info;
#"New Sales" is the name of the column used to CASE that column.
CREATE TABLE Total_Sales (Name char(10),sales int(5));
INSERT INTO Total_Sales VALUES ('zhangsan',10);
INSERT INTO Total_Sales VALUES ('lisi',15);
INSERT INTO Total_Sales VALUES ('wangwu',20);
INSERT INTO Total_Sales VALUES ('zhaoliu',40);
INSERT INTO Total_Sales VALUES ('sunqi',50);
INSERT INTO Total_Sales VALUES ('zhouba',20);
INSERT INTO Total_Sales VALUES ('wujiu',30);
---- to calculate the ranking of ---- form self-join (Self Join), and then the results will be listed in order to calculate how many lines before each line (including that line itself)
SELECT A1.Name, A1.sales,COUNT(A2.sales) Rank FROM Total_sales A1,Total_sales A2
WHERE A1.sales < A2.sales 0R (A1.sales = A2.sales AND A1.Name = A2.Name)
GROUP BY A1.Name, A1.sales ORDER BY A1.sales DESC;
Example.
select A1.Name,A1.sales,count(A2.sales) rank from Total_Sales A1,Total_Sales A2 where A1.sales < A2.sales OR (A1.sales=A2.sales and A1.Name= A2.Name) group by A1.Name order by A1.sales desc;
Explanation.
When the value of the sales field in A1 is less than the value of the sales field in A2, or when the values of the sales fields in the two tables are equal and the values of the Name fields are equal
Query A1's Name field value, A1's sales field value, and A2's sales field non-empty value rank is an alias from A1 and A2 tables, and group A1's Name field, and sort A1's sales field in descending order
---- Calculate the median ----
SELECT Sales Middle FROM (SELECT A1.Name,A1.Sales,COUNT(A2.Sales) Rank FROM Total_Sales A1,Total_Sales A2
WHERE A1.Sales < A2.Sales 0R (A1.Sales = A2.Sales AND A1.Name >= A2.Name)
GROUP BY A1.Name,A1.Sales ORDER BY A1.Sales DESC) A3
WHERE A3.Rank = (SELECT (COUNT(*) + 1) DIV 2 FROM Total_Sales);
Example.
select * from (select A1.Name,A1.sales,count(A2.sales) rank from Total_Sales A1,Total_Sales A2 where A1.sales < A2.sales OR (A1.sales=A2.sales and A1.Name=A2.Name) group by A1.Name order by A1.sales desc) A3 where A3.rank = (select (count(*)+1) DIV 2 from Total_Sales);
select sales mid from (select A1.Name,A1.sales,count(A2.sales) rank from Total_Sales A1,Total_Sales A2 where A1.sales < A2.sales OR (A1.sales= A2.sales and A1.Name=A2.Name) group by A1.Name order by A1.sales desc) A3 where A3.rank = (select (count(*)+1) DIV 2 from Total_Sales);
#Each derived table must have its own alias, so alias A3 must have
#DIV is the way to figure out the quotient in MySQL
---- to calculate the cumulative total ---- table Self Join, and then the results will be listed in order, to calculate the total before each row (including that row itself)
SELECT A1.Name, A1.Sales, SUM(A2.Sales) Sum_Total FROM Total_Sales A1, Total_Sales A2
WHERE A1.Sales < A2.Sales OR (A1.Sales = A2.Sales AND A1.Name = A2.Name)
GROUP BY A1.Name,A1.Sales ORDER BY A1.Sales DESC;
Example.
select A1.*,sum(A2.sales) sum_soales from Total_Sales A1,Total_Sales A2 where A1.sales < A2.sales or(A1.sales=A2.sales and A1.Name=A2.Name) group by A1.Name order by A1.sales desc;
Example.
select A1.*,A1.sales/(select sum(sales) from Total_Sales) z_sum from Total_Sales A1,Total_Sales A2 where A1.sales < A2.sales or (A1.sales=A2. sales and A1.Name=A2.Name) group by A1.Name;
#select sum(sales) from Total_Sales is to calculate the total of the field values and then divide each row by the total to calculate the percentage of the total for each row.
Example.
select A1.Name,A1.sales,sum(A2.sales),sum(A2.sales)/(select sum(sales) from Total_Sales) Z from Total_Sales A1,Total_Sales A2 where A1.sales & lt; A2.sales or (A1.sales=A2.sales and A1.Name=A2.Name) group by A1.Name order by A1.sales desc;
select A1.Name,A1.sales,sum(A2.sales),TRUNCATE(sum(A2.sales)/(select sum(sales) from Total_Sales),2) ||'%' Z from Total_Sales A1,Total_ Sales A2 where A1.sales < A2.sales or (A1.sales=A2.sales and A1.Name=A2.Name) group by A1.Name order by A1.sales desc;
<イグ
DISTINCT
Example.
create table SITE(site varchar(20));
insert into SITE values('nanjing');
insert into SITE values('beijing');
insert into SITE values('');
insert into SITE values('taijin');
insert into SITE values();
insert into SITE values('');
select * from SITE;
select length(site) from SITE;
select * from SITE where site is NULL;
select * from SITE where site is not NULL;
select * from SITE where site = '';
select * from SITE where site <> '';
Match pattern Description Example
^ matches the beginning of the text '^bd' matches a string starting with bd
$ matches the end of the text 'qn$' matches a string ending in qn
. match any single character 's.t' match any string with one character between s and t
* match zero or more characters preceding it 'fo*t' match any character preceding t with an o
+ match the preceding character 1 or more times 'hom+' match any string that starts with ho and is followed by at least one m
string match the string containing the specified 'clo' match the string containing clo
p1|p2' matches p1 or p2 'bg|fg' matches bg or fg
[...] match any character in the set '[abc]' match a or b or c
[^...] match any character not in parentheses '[^ab]' match a string that does not contain a or b
{n} matches the preceding string n times 'g{2}' matches the string with 2 g's
{n,m} matches the preceding string at least n times and up to m times 'f{1,3}' matches f at least 1 time and up to 3 times
<イグ
ここ
Example.
select * from Total_Sales where Name regexp '^[n]';
select * from Total_Sales where Name regexp '[n]';
select * from Total_Sales where Name regexp 'Ho|Bo';
<イグ
AND OR
Syntax.
DELIMITER !!! # Change the end of the statement from a semicolon; temporarily, in case something goes wrong, you can customize it
CREATE PROCEDURE XXX() #Create a procedure with a custom name, () with parameters
BEGIN # procedure body starts with the keyword BEGIN
select * from xxx; # procedure body statement
END!!! #End the procedure body with the keyword END
DELIMITER ; #Restore the end of the statement to a semicolon
call XXX; #Call the procedure
==== View the procedure ====
show create procedure [database.] procedure name; #View specific information about a procedure
show create procedure XXX;
show procedure status [like '%XXX%'] \G
Example.
DELIMITER !!!
CREATE PROCEDURE KIND1()
BEGIN
select * from Total_Sales;
END!!!
DELIMITER ;
CALL KIND1;
show create procedure KIND1\G
show procedure status like '%KIND1%'\G
<イグ
IN
Example.
DELIMITER !!!
CREATE PROCEDURE KIND2(IN people char(20))
BEGIN
select * from Total_Sales where Name=people;
END!!!
DELIMITER ;
CALL KIND2('lisi');
Example.
DELIMITER !!!
CREATE PROCEDURE KIND7(IN num int(10))
BEGIN
declare var int;
set var=num*2;
if var>=10 then
update Total_Sales set sales=sales+1;
else
update Total_Sales set sales=sales-1;
end if;
END!!!
DELIMITER ;
CALL KIND7(5);
CALL KIND7(4);
Example.
create table akg(id int);
DELIMITER !!!
CREATE PROCEDURE KIND6()
BEGIN
declare var int;
set var=0;
while var<5 do
insert into akg values(var);
set var=var+1;
end while;
END!!!
DELIMITER ;
CALL KIND6;
select * from akg;
<イグ
間
---- BETWEEN ---- Display information in a range of two values
Syntax:SELECT "Column" FROM "Table Name" WHERE "Column" BETWEEN 'Value 1' AND 'Value 2';
SELECT * FROM Store_Info WHERE Date BETWEEN '2020-12-06' AND '2020-12-10';
<イグ
ワイルドカード
---- Wildcard ---- Usually wildcards are used in conjunction with LIKE
% : percent sign for zero, one or more characters
_ : underscore for a single character
'A_Z':All strings that start with 'A', another character of any value, and end with 'Z'. For example, 'A.BZ' and 'A.22' both fit this one pattern, while 'AKK2' does not (because there are two characters between A and Z, not one).
'ABC%':All strings that start with 'ABC'. For example, 'ABCD' and 'ABCABC' both match this pattern.
'%XYZ':All strings that end with 'XYZ'. For example, 'WXYZ' and 'ZZXYZ' both match this pattern.
'%AN%':All strings that contain the pattern 'AN'. For example, 'LOS ANGELES' and 'SAN FRANCISCO' both match this pattern.
'_AN%':All strings with the second letter 'A' and the third letter 'N'. For example, 'SAMN FRANCITSCO' matches this pattern, while 'LOS ANGELES' does not.
---- LIKE ---- matches a pattern to find the information we want
Syntax:SELECT "COLUMNS" FROM "TABLE_NAME" WHERE "COLUMNS" LIKE {pattern};
SELECT * FROM Store_Info WHERE Store_Name like '%os%';
---- ORDER BY ---- Sort by keyword
Syntax:SELECT "Columns" FROM "Table_Name" [WHERE "Condition"] ORDER BY "Columns" [ASC, DESC];
#ASC is sorted in ascending order, which is the default sorting method.
#DESC is sorted in descending order.
SELECT Store_Name,Sales,Date FROM Store_Info ORDER BY Sales DESC;
<イグ
機能
数学的機能
abs(x) #returns the absolute value of x
rand() #returns a random number from 0 to 1
mod(x,y) #returns the remainder of x divided by y
power(x,y) # return to the yth power of x
round(x) # return the nearest integer to x
round(x,y) # retain the y decimal places of x after rounding the value
sqrt(x) # return to the square root of x
truncate(x,y) # return the number x truncated to y decimal values
ceil(x) # return greater than or equal to x the smallest integer
floor(x) # return less than or equal to x the largest integer
greatest(x1,x2...) # return the largest value in the set
least(x1,x2...) # return the smallest value in the set
SELECT abs(-1),rand(),mod(5,3),power(2,3),round(1.89);
SELECT round(1.8937,3),truncate(1.235,2),ceil(5.2),floor(2.1),last(1.89,3,6.1,2.1);
<イグ
集計機能
The aggregation function :
avg() #returns the average of the specified columns
count() # return the number of non-NULL values in the specified column
min() #returns the minimum value of the specified column
max() # return the maximum value of the specified column
sum(x) # return the sum of all values of the specified column
SELECT avg(Sales) FROM Store_Info;
SELECT count(store_Name) FROM Store_Info;
SELECT count(DISTINCT store_Name) FROM Store_Info;
SELECT max(Sales) FROM Store_Info;
SELECT min(sales) FROM Store_Info;
SELECT sum(sales) FROM Store_Info;
SELECT count(DISTINCT store_Name) FROM Store_Info;
SELECT count(*) FROM Store_Info;
#count(*) includes the number of rows of all columns and does not ignore the NULL value when counting the results
#count(*) includes only the number of rows in the column with the column name, and will ignore rows with NULL values when counting results
<イグ
文字列機能
The string function :
trim() #returns the value with the specified format removed
concat(x,y) # splice the supplied parameters x and y into a string
substr(x,y) # get the string from the yth position in the string x, the same function as substring()
substr(x,y,z) # get the string from the yth position in the string x the length of the string z
length(x) # return the length of the string x
replace(x,y,z) # replace the string z with the string y in the string x
upper(x) # will be all letters of the string x into uppercase letters
lower(x) # will be all letters of the string x into lowercase letters
left(x,y) # return the first y characters of the string x
right(x,y) # return to the string x after the y characters
repeat(x,y) # will repeat the string x y times
space(x) # return x spaces
strcmp (x,y) #compare x and y, the return value can be -1,0,1
reverse(x) # reverse the string x
SELECT concat(Region,Store_Name) FROM location WHERE Store_Name = 'Boston';
#If sql_mode is turned on with PIPES_AS_CONCAT on, "||" is considered a concatenation operator instead of an or operator, similar to the concatenation function concat, which is used in the same way as the Oracle database
SELECT Region || ' ' || Store_Name FROM location WHERE Store_Name = 'Boston';
SELECT substr(Store_Name,3) FROM location WHERE Store_Name = 'Los Angeles';
SELECT substr(Store_Name,2,4) FROM location WHERE Store_Name = 'New York';
SELECT TRIM ([ [location] [string to remove] FROM ] string);
#[location]: The values can be LEADING (start), TRAILING (end), BOTH (start and end).
#[string to be removed]: the string to be removed from the beginning, the end, or the beginning and the end of the string. By default, it is a space
SELECT TRIM(LEADING 'Ne' FROM 'New York');
SELECT Region,length(Store_Name) FROM location;
SELECT REPLACE(Region,'ast','east') FROM location;
<イグ
---- GROUP BY ---- aggregates and groups the results of queries in the columns following GROUP BY, usually in conjunction with the aggregation function
GROUP BY has a principle that all columns following SELECT that do not use the aggregation function must appear after GROUP BY.
Syntax:SELECT "Column1",SUM("Column2") FROM "TableName" GROUP BY "Column1";
SELECT Store_Name,SUM(Sales) FROM Store_Info GROUP BY Store_Name ORDER BY sales desc;
---- HAVING ---- is used to filter the set of records returned by the GROUP BY statement and is usually used in conjunction with the GROUP BY statement
The existence of the HAVING statement makes up for the fact that the wHERE keyword cannot be used in conjunction with aggregate functions. If the only column being SELECcT is the function column, then the GROUP BY clause is not needed.
Syntax:SELECT "Column1",SUM("Column2") FROM "TableName" GROUP BY "Column1" HAVING (function condition);
SELECT Store_Name,SUM(Sales) FROM Store_Info GROUP BY Store_Name HAVING SUM (Sales) > 1500;
---- alias ---- column alias table alias
Syntax:SELECT "Table Alias". "Column 1" [AS] "Column Alias" FROM "Table Name" [AS] "Table Alias"
SELECT A.Store_Name Store, SUM(A.Sales) "Total Sales" FROM Store_Info A GROUP BY A.Store_Name;
---- subquery ---- joins a table and inserts another SQL statement in the WHERE clause or HAVING clause
Syntax: SELECT "Column1" FROM "Table1" WHERE "Column2" [comparison operator] #external query
(SELECT "column1" FROM "table2" WHERE "condition"); #internal query
can be symbolic operators such as =, >, <, >=, <= ; or literal operators such as LIKE, IN, BETWEEN
SELECT SUM(Sales) FROM Store_Info WHERE Store_Name IN
(SELECT Store_Name FROM location WHERE Region = 'west');
SELECT SUM(A.Sales) FROM Store_Info A WHERE A.Store_Name IN
(SELECT Store_Name FROM location B WHERE B.Store_Name = A.Store_Name);
<イグ
EXISTS
---- EXISTS ---- is used to test whether the inner query produces any results, similar to whether the Boolean value is true
#If so, the system will execute the SQL statement in the outer query. If it is not, then the whole SQL statement will not produce any result.
Syntax: SELECT "Column1" FROM "Form1" WHERE EXISTS (SELECT * FROM "Form2" WHERE "Condition");
SELECT SUM(Sales) FROM Store_Info WHERE EXISTS (SELECT * FROM location WHERE Region = 'West');
<イグ
-
接続クエリ
-
ロケーションフォーム
-
ロケーションフォーム
UPDATE Store_Info SET store_name='washington' WHERE sales=300;
-
Store_Infoテーブル
inner join (inner join): returns only the rows in the two tables whose join fields are equal
left join (left join): returns all rows in the left table that include all rows in the left table and those in the right table with equal join fields
right join(right join): return the rows that include all rows in the right table and the rows with equal join fields in the left table
SELECT * FROM location A INNER JOIN Store_Info B on A.Store_Name = B.store_Name ;
SELECT * FROM location A RIGHT JOIN Store_Info B on A.Store_Name = B.Store_Name ;
SELECT * FROM location A,store_Info B WHERE A.Store_Name = B.Store_Name;
SELECT A.REGION REGION,SUM(B.Sales) SALES FROM location A,Store_Info B
WHERE A.Store_Name = B.Store_Name GROUP BY REGION;
<イグ
CREATE VIEW(ビューの作成
---- CREATE VIEW ---- A view can be thought of as a virtual table or a stored query.
-The difference between a view and a table is that a table has actual stored information, while a view is a structure built on top of a table that does not actually store information itself.
-Temporary tables disappear automatically when the user logs out or when the connection to the database is broken, while views do not disappear.
-A view does not contain data, it only stores its definition, and its purpose is generally to simplify complex queries. For example, if you want to query several tables, and also to perform statistical sorting and other operations, writing SQT statements will be very troublesome, use the view to link several tables, and then query operations on this view, just like a table query, very convenient.
Syntax: CREATE VIEW "depending on the table name" AS "SELECT statement ";
CREATE VIEW V_REGION_SALES AS SELECT A.REGION REGION, SUM(B.Sales) SALES FROM location A
INNER JOIN Store_Info B ON A.Store_Name = B.Store_Name GROUP BY REGION;
SELECT * FROM V_REGION_SALES;
DROP VIEW V_REGION_SALES;
<イグ
UNION
---- UNION ---- union combines the results of two SQL statements, the fields generated by the two SQI statements need to be of the same data type
UNION: The resulting data values will have no duplicates and will be sorted in the order of the fields
Syntax: [SELECT statement 1] UNION [SELECT statement 2];
UNION ALL: lists all the data values of the generated results, regardless of duplicates
Syntax:[SELECT statement 1] UNION ALL [SELECT statement 2];
SELECT Store_Name FROM location UNION SELECT Store_Name FROM Store_Info;
SELECT Store_Name FROM location UNION ALL SELECT Store_Name FROM Store_Info;
<イグ
交差点値
----- intersection value ---- takes the intersection of the results of two SQL statements
SELECT A.Store_Name FROM location A INNER JOIN Store_Info B ON A.Store_Name = B.Store_Name;
SELECT A.Store_Name FROM location A INNER JOIN Store_Info B USING(Store_Name);
#If one of the two table bases does not have the specified row, and the other table has a duplicate row, and does have an intersection, use
SELECT A.Store_Name FROM
(SELECT Store_Name FROM location UNION ALL SELECT Store_Name FROM store_Info) A
GROUP BY A.Store_Name HAVING COUNT(*) > 1;
# Take the intersection of the results of two sQL statements, and no duplicates
SELECT A.Store_Name FRONM (SELECT B.Store_Name FROM location B INNER JOIN Store_Info C ON B.Store_Name = C.store_Name) A
GROUP BY A.Store_Name;
SELECT DISTINCT A.Store_Name FROM location A INNER JOIN Store_Info B USING(Store_Name);
SELECT DISTIMCT Store_Name FROM location WHERE (Store_Name) IN (SELECT Store_Name FROM Store_Info);
SELECT DISTINCT A.Store_Name FROM location A LEFT JOIN Store_Info B USING(Store_Name) WHERE B.Store_Name IS NOT NULL;
<イグ
交差点値なし
---- No intersection values ---- shows the result of the first sQL statement that does not intersect with the second SQL statement and is not duplicated
SELECT DISTINCT Store_Name FROM location WHERE (Store_Name) NOT IN (SELECT Store_Name FROM Store_Info);
SELECT DISTINCT A.Store_Name FROM location A LEFT JOIN Store_Info B USING(Store_Name) WHERE B.Store_Name IS NULL;
<イグ
CASE
---- CASE ---- is a keyword used by SQL for IF-THEN-ELSE type logic
syntax:
SELECT CASE ("field name")
WHEN "Condition 1" THEN "Result 1"
WHEN "condition2" THEN "result2"
...
[ELSE "Result N"]
END
FROM "Table name";
#The ELSE clause is not required.
SELECT store_Name, CASE Store_Name
WHEN 'Los Angeles' THEN Sales * 2
WHEN 'Boston' THEN Sales * 1.5
ELSE Sales
END
"New Sales",Date
FROM Store_Info;
#"New Sales" is the name of the column used to CASE that column.
CREATE TABLE Total_Sales (Name char(10),sales int(5));
INSERT INTO Total_Sales VALUES ('zhangsan',10);
INSERT INTO Total_Sales VALUES ('lisi',15);
INSERT INTO Total_Sales VALUES ('wangwu',20);
INSERT INTO Total_Sales VALUES ('zhaoliu',40);
INSERT INTO Total_Sales VALUES ('sunqi',50);
INSERT INTO Total_Sales VALUES ('zhouba',20);
INSERT INTO Total_Sales VALUES ('wujiu',30);
<イグ

1. ランキングの集計
---- to calculate the ranking of ---- form self-join (Self Join), and then the results will be listed in order to calculate how many lines before each line (including that line itself)
SELECT A1.Name, A1.sales,COUNT(A2.sales) Rank FROM Total_sales A1,Total_sales A2
WHERE A1.sales < A2.sales 0R (A1.sales = A2.sales AND A1.Name = A2.Name)
GROUP BY A1.Name, A1.sales ORDER BY A1.sales DESC;
Example.
select A1.Name,A1.sales,count(A2.sales) rank from Total_Sales A1,Total_Sales A2 where A1.sales < A2.sales OR (A1.sales=A2.sales and A1.Name= A2.Name) group by A1.Name order by A1.sales desc;
Explanation.
When the value of the sales field in A1 is less than the value of the sales field in A2, or when the values of the sales fields in the two tables are equal and the values of the Name fields are equal
Query A1's Name field value, A1's sales field value, and A2's sales field non-empty value rank is an alias from A1 and A2 tables, and group A1's Name field, and sort A1's sales field in descending order
<イグ
2. 中央値を数える
---- Calculate the median ----
SELECT Sales Middle FROM (SELECT A1.Name,A1.Sales,COUNT(A2.Sales) Rank FROM Total_Sales A1,Total_Sales A2
WHERE A1.Sales < A2.Sales 0R (A1.Sales = A2.Sales AND A1.Name >= A2.Name)
GROUP BY A1.Name,A1.Sales ORDER BY A1.Sales DESC) A3
WHERE A3.Rank = (SELECT (COUNT(*) + 1) DIV 2 FROM Total_Sales);
Example.
select * from (select A1.Name,A1.sales,count(A2.sales) rank from Total_Sales A1,Total_Sales A2 where A1.sales < A2.sales OR (A1.sales=A2.sales and A1.Name=A2.Name) group by A1.Name order by A1.sales desc) A3 where A3.rank = (select (count(*)+1) DIV 2 from Total_Sales);
select sales mid from (select A1.Name,A1.sales,count(A2.sales) rank from Total_Sales A1,Total_Sales A2 where A1.sales < A2.sales OR (A1.sales= A2.sales and A1.Name=A2.Name) group by A1.Name order by A1.sales desc) A3 where A3.rank = (select (count(*)+1) DIV 2 from Total_Sales);
#Each derived table must have its own alias, so alias A3 must have
#DIV is the way to figure out the quotient in MySQL
<イグ
3. 累計のカウント
---- to calculate the cumulative total ---- table Self Join, and then the results will be listed in order, to calculate the total before each row (including that row itself)
SELECT A1.Name, A1.Sales, SUM(A2.Sales) Sum_Total FROM Total_Sales A1, Total_Sales A2
WHERE A1.Sales < A2.Sales OR (A1.Sales = A2.Sales AND A1.Name = A2.Name)
GROUP BY A1.Name,A1.Sales ORDER BY A1.Sales DESC;
Example.
select A1.*,sum(A2.sales) sum_soales from Total_Sales A1,Total_Sales A2 where A1.sales < A2.sales or(A1.sales=A2.sales and A1.Name=A2.Name) group by A1.Name order by A1.sales desc;
<イグ
4. 合計のパーセンテージを計算する
Example.
select A1.*,A1.sales/(select sum(sales) from Total_Sales) z_sum from Total_Sales A1,Total_Sales A2 where A1.sales < A2.sales or (A1.sales=A2. sales and A1.Name=A2.Name) group by A1.Name;
#select sum(sales) from Total_Sales is to calculate the total of the field values and then divide each row by the total to calculate the percentage of the total for each row.
<イグ
5. 累計のパーセンテージを計算する
Example.
select A1.Name,A1.sales,sum(A2.sales),sum(A2.sales)/(select sum(sales) from Total_Sales) Z from Total_Sales A1,Total_Sales A2 where A1.sales & lt; A2.sales or (A1.sales=A2.sales and A1.Name=A2.Name) group by A1.Name order by A1.sales desc;
select A1.Name,A1.sales,sum(A2.sales),TRUNCATE(sum(A2.sales)/(select sum(sales) from Total_Sales),2) ||'%' Z from Total_Sales A1,Total_ Sales A2 where A1.sales < A2.sales or (A1.sales=A2.sales and A1.Name=A2.Name) group by A1.Name order by A1.sales desc;
<イグ
6. ヌル(NULL)と値なし(' ')の違いについて
- 1. nullの長さは0であり、スペースを取らないが、nullの長さはnullであり、スペースを取る
- 2、IS NULLまたはIS NOT NULLは、フィールドがNULLまたはNULLではない、それは値がNULLかどうかを調べることはできませんされているかどうかを判断するために使用されています
- 3、=''または<>'で値なし判定を処理する。
- 4. count()で行数を指定する際、NULL値があった場合は自動的に無視され、NULL値があった場合は自動的に計算用レコードに追加されること
Example.
create table SITE(site varchar(20));
insert into SITE values('nanjing');
insert into SITE values('beijing');
insert into SITE values('');
insert into SITE values('taijin');
insert into SITE values();
insert into SITE values('');
select * from SITE;
<イグ
select length(site) from SITE;
select * from SITE where site is NULL;
select * from SITE where site is not NULL;
select * from SITE where site = '';
select * from SITE where site <> '';
<イグ
7. 正規表現 (シェル部分と同じ)
Match pattern Description Example
^ matches the beginning of the text '^bd' matches a string starting with bd
$ matches the end of the text 'qn$' matches a string ending in qn
. match any single character 's.t' match any string with one character between s and t
* match zero or more characters preceding it 'fo*t' match any character preceding t with an o
+ match the preceding character 1 or more times 'hom+' match any string that starts with ho and is followed by at least one m
string match the string containing the specified 'clo' match the string containing clo
p1|p2' matches p1 or p2 'bg|fg' matches bg or fg
[...] match any character in the set '[abc]' match a or b or c
[^...] match any character not in parentheses '[^ab]' match a string that does not contain a or b
{n} matches the preceding string n times 'g{2}' matches the string with 2 g's
{n,m} matches the preceding string at least n times and up to m times 'f{1,3}' matches f at least 1 time and up to 3 times
- 構文 SELECT field FROM テーブル名 WHERE field REGEXP match pattern
Example.
select * from Total_Sales where Name regexp '^[n]';
select * from Total_Sales where Name regexp '[n]';
select * from Total_Sales where Name regexp 'Ho|Bo';
<イグ
8、ストアドプロシージャ(とシェル関数はほとんど同じ、コードの再利用)。
- プロシージャは、特定の機能を実現するために設計されたSQL文の集合体である
- ストアドプロシージャは、よく使われる作業や複雑な作業をあらかじめSQL文を使って記述し、指定した名前で保存しておくものです。プロシージャはコンパイルされ最適化されてデータベースサーバーに格納され、プロシージャが必要なときは呼び出すだけでよい。
-
ストアドプロシージャの利点
- 1. 一度実行すると、生成されたバイナリコードはバッファに常駐し、実行効率を向上させることができる
- 2. SQL文+制御文の集合体で、高い柔軟性を実現
- 3. サーバーサイドに格納し、クライアントから呼び出された際のネットワーク負荷を軽減する
- 4、繰り返し何度も呼び出すことができ、いつでも変更することができ、クライアントの呼び出しに影響を与えません
- 5、すべてのデータベース操作を完了することができますが、また、データベース情報のアクセス権を制御する
Syntax.
DELIMITER !!! # Change the end of the statement from a semicolon; temporarily, in case something goes wrong, you can customize it
CREATE PROCEDURE XXX() #Create a procedure with a custom name, () with parameters
BEGIN # procedure body starts with the keyword BEGIN
select * from xxx; # procedure body statement
END!!! #End the procedure body with the keyword END
DELIMITER ; #Restore the end of the statement to a semicolon
call XXX; #Call the procedure
==== View the procedure ====
show create procedure [database.] procedure name; #View specific information about a procedure
show create procedure XXX;
show procedure status [like '%XXX%'] \G
Example.
DELIMITER !!!
CREATE PROCEDURE KIND1()
BEGIN
select * from Total_Sales;
END!!!
DELIMITER ;
CALL KIND1;
show create procedure KIND1\G
show procedure status like '%KIND1%'\G
<イグ
- プロシージャのパラメータです。
- 呼び出し元がプロシージャに値を渡したことを示すIN入力パラメータ(入力される値はリテラルまたは変数である可能性があります)
- OUT出力パラメータ:プロシージャが呼び出し元に値を渡したことを示す(複数の値を返すことが可能、出力値は変数のみ)。
Example.
DELIMITER !!!
CREATE PROCEDURE KIND2(IN people char(20))
BEGIN
select * from Total_Sales where Name=people;
END!!!
DELIMITER ;
CALL KIND2('lisi');
<イグ
8.1. ストアドプロシージャの条件文
Example.
DELIMITER !!!
CREATE PROCEDURE KIND7(IN num int(10))
BEGIN
declare var int;
set var=num*2;
if var>=10 then
update Total_Sales set sales=sales+1;
else
update Total_Sales set sales=sales-1;
end if;
END!!!
DELIMITER ;
CALL KIND7(5);
CALL KIND7(4);
<イグ

8.2. ループ文 while
Example.
create table akg(id int);
DELIMITER !!!
CREATE PROCEDURE KIND6()
BEGIN
declare var int;
set var=0;
while var<5 do
insert into akg values(var);
set var=var+1;
end while;
END!!!
DELIMITER ;
CALL KIND6;
select * from akg;
<イグ
関連
-
この操作を行うには、少なくとも1つのSUPER権限が必要です。
-
MySQL - エラーです。executeQuery() でデータ操作ステートメントを発行できません。
-
Hibernateでhibernate.propertiesが見つからない問題とデータベース方言の更新の問題
-
MySQLデータベースのクエリ機能を使用する際に、グループ関数の使用が無効である問題の解決方法
-
[Mac] sudo mongod コマンド、プロンプトコマンドが見つかりません。
-
mongodbの更新操作の更新
-
Oracleデータベースの挿入データエラーです。ORA-06550
-
ORA-30926: ソース・テーブルの安定した行のセットを取得できませんか?
-
ORA-65096 無効な共通ユーザー名またはロール名
-
AttributeError: 'function' オブジェクトには 'cursor' という属性がありません。
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
MYSQL "Access denied; you need (at least one of) SUPER privilege(s) for this operation" 問題解決
-
(NTDLL.DLL): 0xC0000005: アクセス違反 - 解決
-
解決方法 テーブルの定義が正しくありません。自動列は1つだけで、キーとして定義する必要があります。
-
解決策: テーブルの定義が正しくありません。
-
SocketTimeoutExceptionが発生しました。読み取りがタイムアウトした問題のトラブルシューティング
-
EF Exception Inquiry (エンティティオブジェクトは、IEntityChangeTrackerの複数のインスタンスから参照できません。)...
-
INSERT EXEC文は入れ子にできません。
-
01. プロシージャの結果セットを持つ一時テーブルへのSELECT INTO
-
Postgresql でテーブル "t" の FROM 句の項目が見つからない。
-
ORA-06550 "の解決策。1 行目、7 列目"