mysql インデックス - なぜ自己インクリメント番号を主キーとして使用するのか 理解し、インデックスを使用し、インデックスの条件を使用し、いくつかの場所を使用します。
最近mysqlデータベースは、とにかく、ハハハを爆発するように頼まれた、大きな工場をロールバックするつもりはない、それを爆発させるように頼まれたが、学習やオタク時間mysqlの記事を読んで、学ぶために チェーン記事ピックアップ 私は最近、自分自身に別の半月の休みを与え、今、私はまた、私はすぐに秋の募集会社に満足していると私は給与の話を願って開始、年30が平らに横たわっていきます、いいえ、その後、インタビューのために立ち上がるハハッ
私は本当に前に小さなインデックスに非常に多くの興味深い場所があることを知らなかったので、私は前に知っていた/知らないことをいくつかのことを記録します。
索引とは、本の目次のようなもので、欲しいものを探すのにスピードアップを図るものです。
主キーインデックスとセカンダリインデックス(非主キーインデックスとして理解することができる)、非主キーインデックスは、あなたが望むデータを見つけるために主キーのバックテーブル操作を持っている必要がありますので、それは私が以前に理解し、また多くの時間は、主キーとして自己増加IDを使用することを知っている、二次インデックスと呼ばれるが、これはなぜ私は本当にわからないです。ちょうど記事の例のように、また、例えばIDカードを取る、intは4バイトですが、IDカード番号は文字列型であり、18ビットは18バイトとしてカウントされ、その二次インデックスは、主キーの下にぶら下がっている主キーとしてIDカード番号なら、主キーの下にぶら下がって二次インデックスは、18バイトにあり、自己増加IDの使用は4バイトだけではありませんか?はい、それは正しいので、何度も主キーとしてintを使用すると、スペースを節約することです。では、なぜセルフインクリメントが必要なのでしょうか?データはページによって、突然特定の場所に挿入された場合、彼は前後のデータを持っていますが、バックはもはやデータを追加することができますので、明らかに非常に時間のかかる、モバイルデータで、新しいページを生成するこの時間は、自己インクリメント私は尾の後に追加することができ、そこにデータを移動する必要があるので面倒な操作です。これは、自己インクリメントと主キーとして数字を使用しての主な理由を説明します。
データベースのテーブルは複数のB+木で構成されており、作成されるインデックスはそれぞれB+木が作成されたものである。
説明では、インデックスを使うのはオーバーライドインデックスを使うことで、テーブルに戻らなくてもいいということです。
ジョイントインデックスは、(a,b)ジョイントインデックスを作成すると、(a,b)、2つのインデックスとして見ることができる場合、プロジェクトデータ、より多くの、より多くの、bもより多くの共同、その後また、フィールドが短い、短いデータであり、新しいインデックスを開くことを考慮すると、ジョイントインデックスの左側に長いフィールドですことができる。
私はどこを使用して理解するためにテーブルを構築し、インデックスを使用して、インデックスの条件を使用して。コースは名前の年齢の共同インデックスであり、私はテストのためにid /カード名の年齢の共同インデックスを構築する
CREATE TABLE `tuser` (
`id` int(11) NOT NULL,
`id_card` varchar(32) DEFAULT NULL,
`name` varchar(32) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`ismale` tinyint(1) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB
次のSQL文を実行します。
mysql> select * from tuser where name like 'Zhang%' and age=10 and ismale=1;
インデックス条件を使ってテーブルに戻ると、より少ないデータが返されました。
図3はUsing index conditionの最適化を行わない場合、図4は最適化を行った場合です。
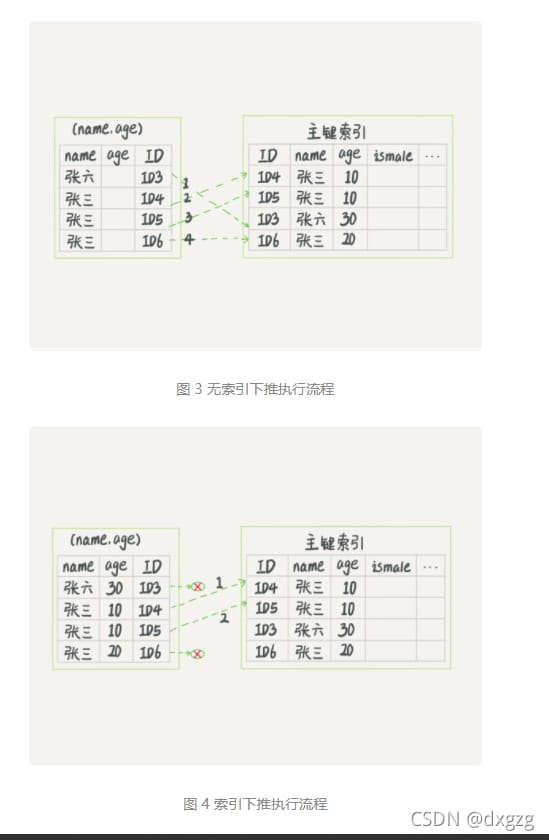
たくさんのsql文を実行しましたが、個人的な推測では、Using indexの条件が表示される前にテーブルに戻っているのではと思います

また、テーブルに戻らずにインデックスを使用しても、左端一致の原則を満たさない場合は、Using where; Using index 状態になるそうです。私の理解では、このジョイントインデックスでもwhereフィルタ条件が使用され、テーブルのフルスキャンを必要とせず(typeフィールドはALLではありません)、さらにテーブルの戻り操作を避けるためにインデックスの上に主キーを使用する、ということです。

プレフィックスインデックスを考慮し、インデックスの後に何が来るかを考慮し、さらにこの関数を使ってプレフィックスインデックスに含まれるビット数を決定することができます。

関連
-
[解決済み] MySQL エラー 1093 - FROM 句で更新のターゲット テーブルを指定できません。
-
[解決済み] MySQLクエリ GROUP BY 日/月/年
-
[解決済み] 各単語の最初の文字を大文字にする(既存のテーブルの場合
-
[解決済み] MySQL テーブルのテーブルレベルロック待ち
-
[解決済み] モジュール `mysql` が見つからない node.js
-
[解決済み] MySQLのgroup_concat_max_lenの最大許容値を教えてください。
-
[解決済み] <」はどの文字セットですか?[閉じる]
-
この操作には(少なくとも)1つのRELOAD権限が必要です。
-
初期通信パケットの読み込み」でMySQLサーバーに接続できなくなり、システムエラーが発生しました。111
-
mysql更新レコードエラー "Truncated incorrect DOUBLE value".
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み】MySQLユーザーDBにパスワードカラムがない - OSXへのMySQLインストール
-
[解決済み] MySQLで「一意のテーブル/エイリアスでない」場合
-
[解決済み] ONLY_FULL_GROUP_BYの無効化
-
[解決済み] テーブルのストレージエンジンは修復をサポートしていません。InnoDB または MyISAM?
-
[解決済み] MYSQLのTIMESTAMP比較
-
[解決済み] mysql Fatal error: cannot allocate memory for buffer pool
-
[解決済み] 警告 #1265 1行目の列 'pdd' でデータが切り捨てられました [閉鎖]。
-
[解決済み] リモートサーバーのMySQLデータベースをバックアップする方法は?
-
初期通信パケットの読み込み」でMySQLサーバーに接続できなくなり、システムエラーが発生しました。0
-
Mysqlの解決策 「初期通信パケットの読み込み」でMySQLサーバーに接続できなくなる、システムエラー。0