[mysql] コマンドラインガイド
mysqlの簡単な紹介
MySQLは、スウェーデンのMySQL ABが開発したリレーショナルデータベース管理システムで、現在はオラクルの傘下に入っている。MySQLは、最も人気のあるリレーショナルデータベース管理システムの1つで、WEBアプリケーションに最適なRDBMS(リレーショナルデータベース管理システム)アプリケーションです。MySQLは、最も人気のあるリレーショナルデータベース管理システムの1つであり、Webアプリケーションに最適なRDBMS(リレーショナルデータベース管理システム)アプリケーションです。
MySQL はリレーショナルデータベース管理システムです。リレーショナル・データベースは、すべてのデータを1つの大きな倉庫に入れるのではなく、異なるテーブルにデータを格納することで、スピードを上げ、柔軟性を向上させることができます。
MySQLが使用するSQL言語は、データベースへのアクセスに使用される最も一般的な標準化言語です。MySQLソフトウェアはデュアルライセンシングポリシーを採用しており、コミュニティ版と商用版に分かれています。MySQLは一般的に、その小さなサイズ、スピード、低い総所有コスト、そして特にオープンソースの特徴から、中小規模のWebサイト開発におけるWebサイトデータベースとして選ばれています。
目次を見る
1. mysqlに接続する3つの方法
2. 基本的なSQL文
3. データテーブルを操作する
4.データ型
5. プロパティと制約条件
6. テーブル構造の変更
演習問題
7. テーブルデータの追加・削除・チェック
コマンド紹介
1. mysqlに接続する3つの方法
-
コマンドライン内から、次のように入力します。
mysql -u root -pEnter、次にパスワードを入力し、Enterで入力する -
コマンドラインから、次のように入力します。
mysql -h localhost -P 3306 -u root -pEnter、次にパスワードを入力し、Enter、runで入力します。 - (Windows)あなたは、スタートメニュー、mysqlフォルダ内のMySQLを探し、コマンドラインクライアントを起動し、パスワードを入力することができます。
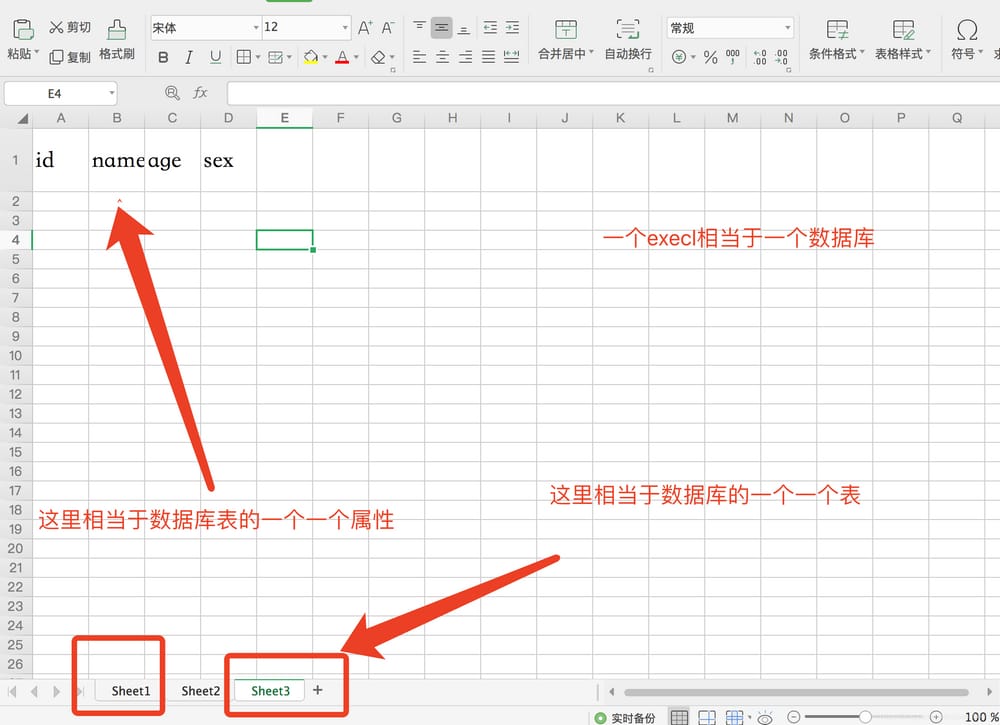
2. 基本的なSQL文(SQL文はセミコロンで終わる)(一般的なエクセルのcreate write and storeに類似している)。
-
すべてのデータベースファイルを表示する(Excelファイルのディレクトリを開くのに似ている)
show databases; -
データベースの作成(エクセルファイルの作成と同様)
create database test; -
データベースを使用する(エクセルファイルを開くのと同じです)
use test; -
データテーブルを見る(どのようなシートがあるか見るのと同等です)
show tables; -
ライブラリの削除(エクセルの削除と同等)
drop database test;
3. データテーブルを操作する
- テーブルの作成(エクセルで新しいシートを作成し、シートの最初の行で名前、年齢、性別など各列に記入する内容を指定するのと同じです)
create table [if not exists] table name (
field name1 column type [attribute] [constraint] [comment],
field name2 column type [attribute] [constraint] [comment],
......
field name n column type [attribute] [constraint] [comment]
);
-
テーブルの削除(Excelの既存シートの削除と同等)
drop table (table name); -
テーブル構造の表示
desc (table name); -
データテーブルを表示する
show tables;
4. データ型(一般に列型に使用される)
- 数値型
整数です。一般的なものは、int bigint
浮動小数点:よく使われるのはfloat double
- 文字列型(mは長さの値)
char(m)
varchar(m) varchar(20) 20文字を意味します。
テキスト
longtext : 小説を保存する
- 日付の種類
日付 2019-8-3
日時 2019-8-3 10:05:30
timestamp タイムスタンプ
時間 10:05:30
5. 属性と制約
- ヌル空
- not null not null
- default age : age int default 18 のようなデフォルト値です。
- ユニークキー ユニークには、カラムの値がユニークであること、すなわち重複がないことを設定する。例えば、ID番号のように、一般的にユニークであることが望ましい
- 主キー : テーブルが持たなければならない主キーのユニークマーカー(ユニーク属性付き、NULL属性は不可)、一般的には自己増殖の数である。
- auto_increment: 主キーに auto_increment を設定する必要がある、 int 、その値はロールバックされない。
-
外部キー : 外部キー 冗長性を減らし、他のテーブルと結合するために使用される。
構文: constraint 外部キーに付ける名前 外部キー(外部キーを参照させたいカラム名) references 参照先のテーブル名(カラム名でこのカラム名は主キー属性を持っている)。
6. テーブルの構造を変更する
-
テーブル名の変更
構文: テーブルを変更する (古いテーブル名) 名前を変更する (新しいテーブル名)
例:-> alter table class1 rename as classOne; -
フィールドの追加
構文:alter table (テーブル名) add (フィールド名) (列タイプ) [属性] [制約]を追加します。
例:-> alter table class2 add phone varchar(20); -
フィールドを削除する
構文:alter table (テーブル名) drop (フィールド名) -
フィールド名の変更
構文:alter table (テーブル名) change (古いフィールド名) (新しいフィールド名) (列の種類) [属性] [制約].
例:-> alter table class2 change name stu_name varchar(20) not null; -
属性を変更する
構文:alter table (テーブル名) modity (フィールド名) ( 列タイプ) [属性][制約].
例:-> alter table class2 modify stu_name varchar(50) not null; -
外部キーを追加します。
構文: alter table (外部キーを追加したいテーブル名) add constraint (外部キーに付ける名前)( foreign key (外部キーに参照したい列名) references (参照テーブル名) (列名と列名が主キー属性を持っている)です。
運動
ライブラリーグッズの作成
グッズライブラリの利用
commoditytype テーブルを作成する commoditytype
商品テーブル「commodity」の作成
c_id 主キー self-growing
c_name 50 文字の文字列 Not null
c_madein 50文字以上 nullでない文字列
c_type, integer, 製品テーブルの ct_id に関連する外部キーです。
c_inprice ,integer Not null
c_outprice,integer nullではない
c_num, 整数値 初期値 100
create table commoditytype(
ct_id int primary key auto_increment,
ct_name varchar(50) not null
) default charset=utf8;
create table commodity(
c_id int primary key auto_increment,
c_name varchar(50) not null,
c_madein varchar(50) not null,
c_type int,
constraint fk_1 foreign key (c_type) references commoditytype(ct_id),
c_inprice int not null,
c_outprice int not null,
c_num int default 100
) default charset=utf8;
7. テーブルデータの追加、削除、チェック
7.1 データの追加と挿入
構文:insert into [table_name] ([column], ...) values("name", ...)です。
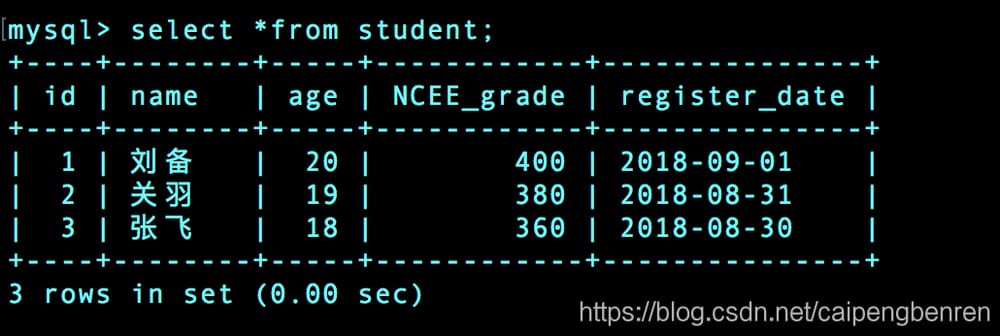
例
insert into student(name,age,NCEE_grade,register_date) values("Liu Bei",20,400,"2018-9-1").
insert into student(name,age,NCEE_grade,register_date) values("Guan Yu",19,380,"2018-8-31");
insert into student(name,age,NCEE_grade,register_date) values("Zhang Fei",18,360,"2018-8-30");
<イグ
7.2.行データの削除
構文: delete from [table_name] where [column_name] = " "
例
1. delete the child named Liu Bei delete from student where name = "Liu Bei".
2. delete children whose age is greater than or equal to 19 delete from student where age>=19;
3. delete from student where date like "2018-09%";
<イグ
7.3.データ値の変更
書式: update [テーブル名] set [columns] = " ",[columns] = " " where /.
例 劉備の子供の高校入試の点数を390点に変更する場合
update student set NCEE_grade = 390 where name = "刘备";
<イグ
7.4.統計的要件に従ったデータのチェック
NCEE_gradeの降順で表示する。
select * from student order by NCEE_grade desc;
 各カラムの出現回数のグループ化
各カラムの出現回数のグループ化
フォーマット: select [column],count(*) (as [name]) from student group by [column];
select register_date,count(*) as date_num from student group by register_date;
select name,sum(NCEE_grade) from student group by name ;
<イグ
column1 のグループ分けをもとに、各グループの column2 の合計値を個別に算出する。
書式: select [column1],sum(column2) from student group by [column1] ;
select coalesce(name,"total_grade"),sum(NCEE_grade) as total from student group by name with rollup
<イグ
column1 のグループ化に基づいて各グループの column2 の合計値を計算し、以下の形式で学生の総数をカウントします。 select coalesce(column1, "total_num"),sum(column2) as [name] from student group by [column1] with rollup.グループ化した学生の総数を計算します。
select coalesce(name,"total_grade"),sum(NCEE_grade) as total from student group by name with rollup
<イグ
関連
-
[解決済み】1052:フィールドリストの列「id」が曖昧である
-
[解決済み】カラムのデータが切り捨てられた?
-
[解決済み] SQLZOO - select from world チュートリアル #13
-
[解決済み] MySQLにおけるOracleのRowIDに相当する。
-
[解決済み] SQLキー、MUL vs PRI vs UNI
-
[解決済み] MySQL でネストされたトランザクションは可能ですか?
-
[解決済み] エラーコード1111。グループ関数の無効な使用
-
[解決済み] モジュール `mysql` が見つからない node.js
-
[解決済み] mysqlステートメントの*アスタリスクは何を意味するのですか?
-
[解決済み] MySQLで1つを除くすべての列を選択しますか?
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み】mysqld_safe UNIX ソケットファイル用のディレクトリ '/var/run/mysqld' が存在しません。
-
[解決済み] 1030 ストレージエンジンからエラー28が発生しました
-
[解決済み] "sqlstate[23000]: 整合性制約違反 "を有効な制約で
-
[解決済み] ローカルマシンからリモートDBをmysqldumpする方法
-
[解決済み] エラーコードです。1215. 外部キー制約を追加できません (外部キー)
-
[解決済み] MySQLで "no "キーワードは何に使うのですか?
-
[解決済み] 数値が範囲外です。mysql で 1264
-
[解決済み] Mysql 1050 エラー "テーブルはすでに存在しています" 実際には存在しないのに。
-
初期通信パケットの読み込み」でMySQLサーバーに接続できなくなり、システムエラーが発生しました。111
-
mysqlがエラーを報告する(ユニークなテーブル/エイリアスでない)。