Microsoft.Office.Interop を使わずに .NET Core で Word doc および docx フォーマットを PDF に変換する
質問
Wordを表示したい
.doc
と
.docx
ファイルをブラウザで表示することができます。クライアント側でこれを行う実際の方法はなく、これらのドキュメントは法的な理由から Google docs や Microsoft Office 365 と共有することはできません。
ブラウザはWordを表示できませんが、PDFは表示できるので、これらのドキュメントをサーバー上でPDFに変換して、それを表示したいのです。
私は、これが
Microsoft.Office.Interop.Word
を使用して実行できることは知っていますが、私のアプリケーションは .NET Core で、Office interop にアクセスすることはできません。Azure 上で実行することもできますが、他の何かで Docker コンテナーで実行することもできます。
これと似たような質問がたくさんあるように見えますが、ほとんどはフル フレームワーク .NET について質問しているか、サーバーが Windows OS であると仮定しており、どんな答えも私にとっては役に立ちません。
どのように
.doc
と
.docx
ファイルから
.pdf
を使わずに
へのアクセス
Microsoft.Office.Interop.Word
?
どのように解決するのですか?
これでは、サードパーティのソリューションがすべて、開発者1人あたり500ドルを請求するのも無理はないでしょう。
良い知らせは
Open XML SDK が最近、.Net Standard のサポートを追加したことです。
をサポートしたことです。
.docx
形式をサポートするようになりました。
悪い知らせ 現時点では には、.NET Core 上の PDF 生成ライブラリの選択肢があまりありません。お金を払って購入したいとは思えませんし、サード パーティのサービスを合法的に使用することもできないため、独自に開発する以外の選択肢はほとんどありません。
主な問題は、Word ドキュメント コンテンツを PDF に変換させることです。一般的な方法の 1 つは、Docx を HTML に読み込んで、それを PDF にエクスポートすることです。見つけるのは困難でしたが、OpenXMLSDK の .Net Core バージョンがあります。 PowerTools があり、DocxをHTMLに変換することをサポートしています。Pull Requestが受理されそうなので、ここから入手できます。
https://github.com/OfficeDev/Open-Xml-PowerTools/tree/abfbaac510d0d60e2f492503c60ef897247716cf
さて、ドキュメントの内容をHTMLに抽出することができたので、それをPDFに変換する必要があります。HTMLをPDFに変換するためのライブラリはいくつかありますが、例えば DinkToPdf は、Webkit HTML to PDF ライブラリ libwkhtmltox のクロスプラットフォームなラッパーです。
DinkToPdf の方が https://code.msdn.microsoft.com/How-to-export-HTML-to-PDF-c5afd0ce
DocxからHTMLへ
これをまとめて、OpenXMLSDK-PowerTools .Net Coreプロジェクトをダウンロードしてビルドしましょう(OpenXMLPowerTools.Core と OpenXMLPowerTools.Core.Example だけです - 他のプロジェクトは無視してください)。
OpenXMLPowerTools.Core.ExampleをStartUpプロジェクトとして設定します。プロジェクトにWordドキュメントを追加し(例:test.docx)、このdocxファイルのプロパティを設定します。
Copy To Output = If Newer
コンソールプロジェクトを実行します。
static void Main(string[] args)
{
var source = Package.Open(@"test.docx");
var document = WordprocessingDocument.Open(source);
HtmlConverterSettings settings = new HtmlConverterSettings();
XElement html = HtmlConverter.ConvertToHtml(document, settings);
Console.WriteLine(html.ToString());
var writer = File.CreateText("test.html");
writer.WriteLine(html.ToString());
writer.Dispose();
Console.ReadLine();
test.docxが有効なワード文書であり、テキストがあることを確認してください。
指定されたパッケージは無効です。主要な部分が欠けています。
プロジェクトを実行すると、HTMLがWord文書の内容とほとんど同じに見えることがわかります。
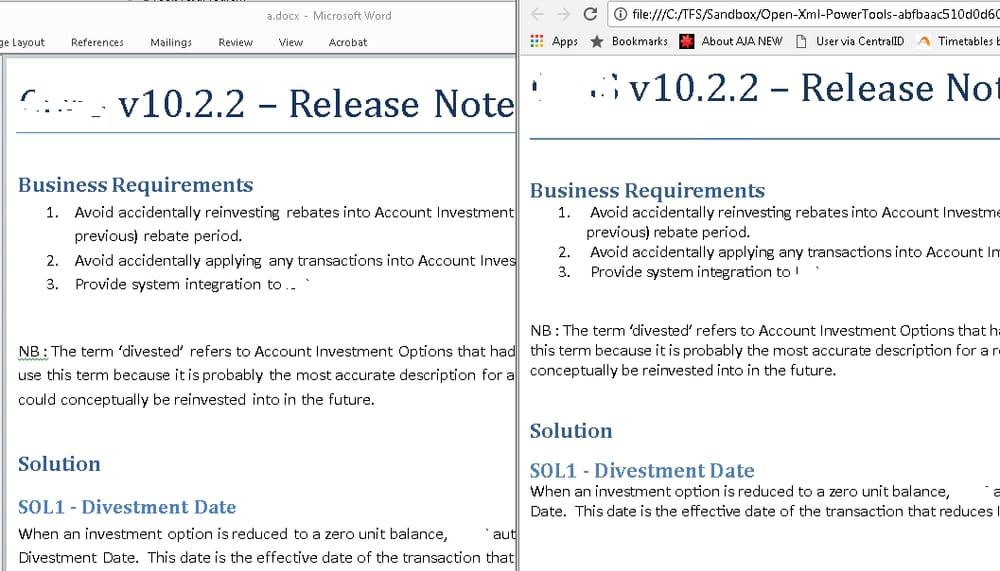
しかし、画像やリンクを含む Word ドキュメントを試した場合、それらが欠けていたり、壊れていたりすることに気づくでしょう。
このCodeProjectの記事はこれらの問題に対処しています。 https://www.codeproject.com/Articles/1162184/Csharp-Docx-to-HTML-to-Docx
を変更する必要がありました。
static Uri FixUri(string brokenUri)
メソッドを
Uri
を返すようにし、ユーザーフレンドリーなエラーメッセージを追加しました。
static void Main(string[] args)
{
var fileInfo = new FileInfo(@"c:\temp\MyDocWithImages.docx");
string fullFilePath = fileInfo.FullName;
string htmlText = string.Empty;
try
{
htmlText = ParseDOCX(fileInfo);
}
catch (OpenXmlPackageException e)
{
if (e.ToString().Contains("Invalid Hyperlink"))
{
using (FileStream fs = new FileStream(fullFilePath,FileMode.OpenOrCreate, FileAccess.ReadWrite))
{
UriFixer.FixInvalidUri(fs, brokenUri => FixUri(brokenUri));
}
htmlText = ParseDOCX(fileInfo);
}
}
var writer = File.CreateText("test1.html");
writer.WriteLine(htmlText.ToString());
writer.Dispose();
}
public static Uri FixUri(string brokenUri)
{
string newURI = string.Empty;
if (brokenUri.Contains("mailto:"))
{
int mailToCount = "mailto:".Length;
brokenUri = brokenUri.Remove(0, mailToCount);
newURI = brokenUri;
}
else
{
newURI = " ";
}
return new Uri(newURI);
}
public static string ParseDOCX(FileInfo fileInfo)
{
try
{
byte[] byteArray = File.ReadAllBytes(fileInfo.FullName);
using (MemoryStream memoryStream = new MemoryStream())
{
memoryStream.Write(byteArray, 0, byteArray.Length);
using (WordprocessingDocument wDoc =
WordprocessingDocument.Open(memoryStream, true))
{
int imageCounter = 0;
var pageTitle = fileInfo.FullName;
var part = wDoc.CoreFilePropertiesPart;
if (part != null)
pageTitle = (string)part.GetXDocument()
.Descendants(DC.title)
.FirstOrDefault() ?? fileInfo.FullName;
WmlToHtmlConverterSettings settings = new WmlToHtmlConverterSettings()
{
AdditionalCss = "body { margin: 1cm auto; max-width: 20cm; padding: 0; }",
PageTitle = pageTitle,
FabricateCssClasses = true,
CssClassPrefix = "pt-",
RestrictToSupportedLanguages = false,
RestrictToSupportedNumberingFormats = false,
ImageHandler = imageInfo =>
{
++imageCounter;
string extension = imageInfo.ContentType.Split('/')[1].ToLower();
ImageFormat imageFormat = null;
if (extension == "png") imageFormat = ImageFormat.Png;
else if (extension == "gif") imageFormat = ImageFormat.Gif;
else if (extension == "bmp") imageFormat = ImageFormat.Bmp;
else if (extension == "jpeg") imageFormat = ImageFormat.Jpeg;
else if (extension == "tiff")
{
extension = "gif";
imageFormat = ImageFormat.Gif;
}
else if (extension == "x-wmf")
{
extension = "wmf";
imageFormat = ImageFormat.Wmf;
}
if (imageFormat == null) return null;
string base64 = null;
try
{
using (MemoryStream ms = new MemoryStream())
{
imageInfo.Bitmap.Save(ms, imageFormat);
var ba = ms.ToArray();
base64 = System.Convert.ToBase64String(ba);
}
}
catch (System.Runtime.InteropServices.ExternalException)
{ return null; }
ImageFormat format = imageInfo.Bitmap.RawFormat;
ImageCodecInfo codec = ImageCodecInfo.GetImageDecoders()
.First(c => c.FormatID == format.Guid);
string mimeType = codec.MimeType;
string imageSource =
string.Format("data:{0};base64,{1}", mimeType, base64);
XElement img = new XElement(Xhtml.img,
new XAttribute(NoNamespace.src, imageSource),
imageInfo.ImgStyleAttribute,
imageInfo.AltText != null ?
new XAttribute(NoNamespace.alt, imageInfo.AltText) : null);
return img;
}
};
XElement htmlElement = WmlToHtmlConverter.ConvertToHtml(wDoc, settings);
var html = new XDocument(new XDocumentType("html", null, null, null),
htmlElement);
var htmlString = html.ToString(SaveOptions.DisableFormatting);
return htmlString;
}
}
}
catch
{
return "The file is either open, please close it or contains corrupt data";
}
}
ImageFormat を使用するには System.Drawing.Common NuGet パッケージが必要な場合があります。
これで画像を取得できるようになりました。
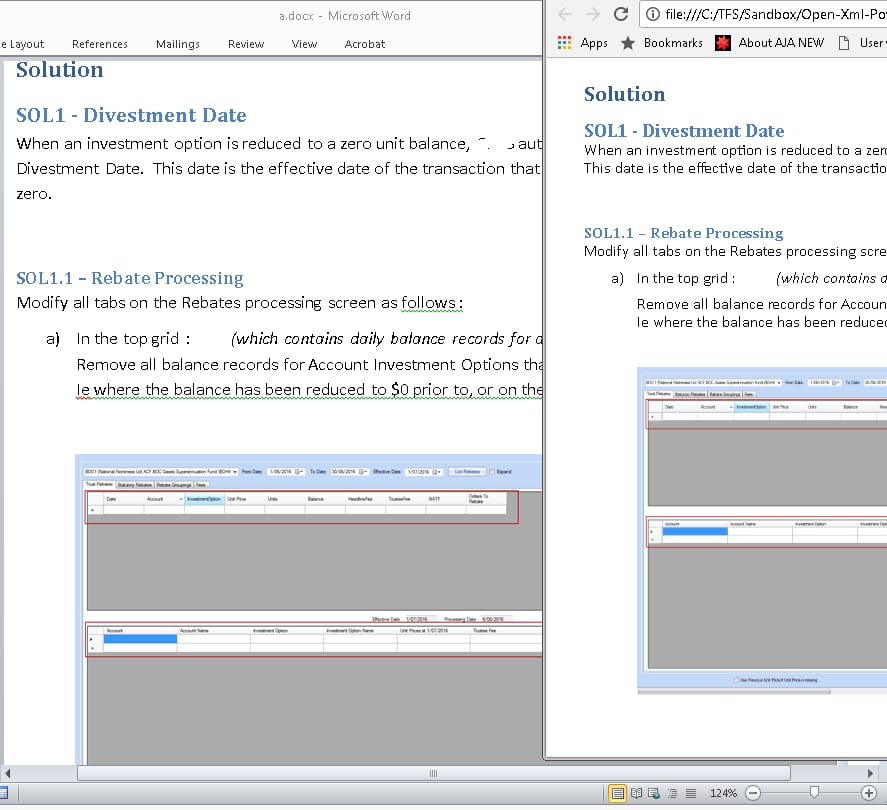
Web ブラウザで Word .docx ファイルを表示したいだけなら、HTML を PDF に変換しないほうがよいでしょう。HTML をファイル システム、クラウド、または VPP テクノロジーを使用した dB に保存することができます。
HTMLからPDFへ
次に必要なことは、HTMLをDinkToPdfに渡すことです。DinkToPdf (90 MB) ソリューションをダウンロードします。ソリューションをビルドします。すべてのパッケージがリストアされ、ソリューションがコンパイルされるまでしばらく時間がかかります。
重要なことです。
DinkToPdf ライブラリは、Linux と Windows で動作させたい場合、プロジェクトのルートに libwkhtmltox.so と libwkhtmltox.dll ファイルが必要です。必要であれば、Mac 用の libwkhtmltox.dylib ファイルもあります。
これらの DLL は、v0.12.4 フォルダにあります。お使いのPCの32ビット、64ビットに応じて、3つのファイルをDinkToPdf-master DinkToPfd.TestConsoleApp\binDebug\netcoreapp1.1 フォルダーにコピーしてください。
重要なこと 2:
Docker イメージまたは Linux マシンに libgdiplus がインストールされていることを確認してください。libwkhtmltox.so ライブラリはこれに依存しています。
DinkToPfd.TestConsoleAppをStartUpプロジェクトに設定し、Program.csファイルを変更して、Lorium Ipsomテキストではなく、Open-Xml-PowerToolsで保存したHTMLファイルからhtmlContentを読み込むように変更します。
var doc = new HtmlToPdfDocument()
{
GlobalSettings = {
ColorMode = ColorMode.Color,
Orientation = Orientation.Landscape,
PaperSize = PaperKind.A4,
},
Objects = {
new ObjectSettings() {
PagesCount = true,
HtmlContent = File.ReadAllText(@"C:\TFS\Sandbox\Open-Xml-PowerTools-abfbaac510d0d60e2f492503c60ef897247716cf\ToolsTest\test1.html"),
WebSettings = { DefaultEncoding = "utf-8" },
HeaderSettings = { FontSize = 9, Right = "Page [page] of [toPage]", Line = true },
FooterSettings = { FontSize = 9, Right = "Page [page] of [toPage]" }
}
}
};
Docx と PDF の結果は非常に印象的で、多くの人が多くの違いを見つけることはないでしょう (特に、オリジナルを見たことがない場合は)。
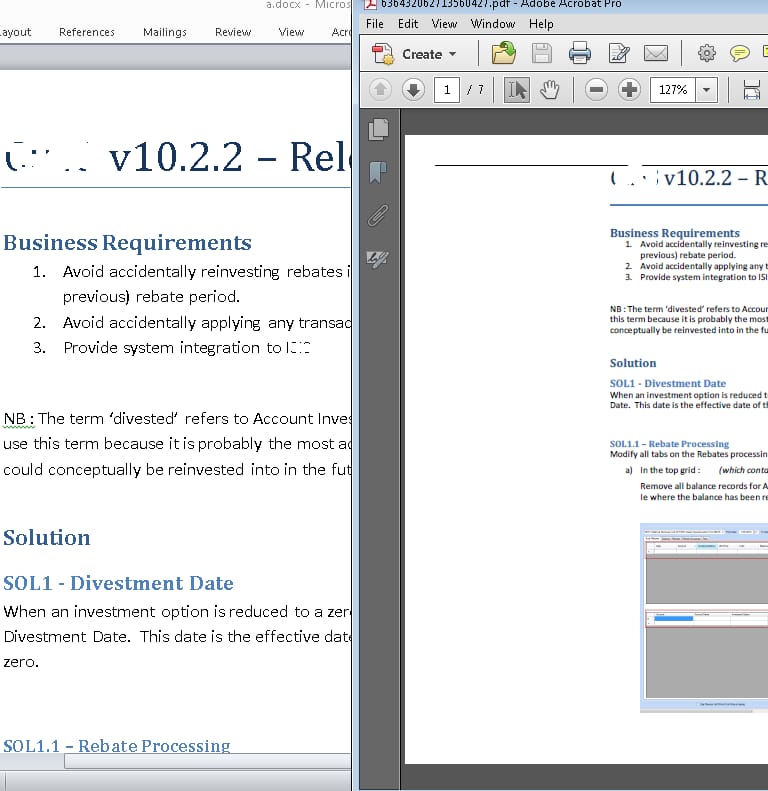
Ps. 私はあなたが両方の
.doc
と
.docx
をPDFに変換することができます。サーバーではない特定のWindows/Microsoftの技術を使って、.docをdocxに変換するサービスを自分で作ることをお勧めします。doc形式はバイナリであり、以下のような用途を想定していない。
オフィスのサーバー サイド オートメーション
.
関連
-
[解決済み】ここで「要求URIに一致するHTTPリソースが見つかりませんでした」となるのはなぜですか?
-
[解決済み】ソケットのアドレス(プロトコル/ネットワークアドレス/ポート)は、通常1つしか使用できない?
-
[解決済み] [Solved] 不正な文字列値: '\xEFxBFxBD' for column
-
[解決済み】なぜこのコードはInvalidOperationExceptionを投げるのですか?
-
[解決済み】2年前のMSDateを把握する【クローズド
-
[解決済み】URLから画像をダウンロードする方法
-
[解決済み】インデックスが範囲外でした。コレクションパラメータname:indexのサイズより小さく、非負でなければなりません。
-
[解決済み】ユーザー設定値を別のユーザー設定値で設定する
-
[解決済み] MS Wordの保存形式とシンタックスハイライトでコードスニペットを表示するにはどうすればよいですか?
-
[解決済み] .NET Coreと.NET Standard Class Libraryのプロジェクトタイプの違いは何ですか?
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み】「未割り当てのローカル変数を使用」とはどういう意味ですか?
-
[解決済み】非静的メソッドはターゲットを必要とする
-
[解決済み】値が期待した範囲に収まらない
-
[解決済み] EntityTypeにキーが定義されていないエラー
-
[解決済み】「...は'型'であり、与えられたコンテキストでは有効ではありません」を解決するにはどうすればよいですか?(C#)
-
[解決済み】2つ(またはそれ以上)のリストを1つに統合する(C# .NETで
-
[解決済み] [Solved] .NETでスレッドの終了を待つには?
-
[解決済み】IntPtrとは一体何なのか?
-
[解決済み] 関数を終了するには?
-
[解決済み】スレッド終了またはアプリケーションの要求により、I/O操作が中断されました。