[解決済み] matplotlibでpcolorを使ったヒートマップ?
2022-10-31 22:03:28
質問
このようなヒートマップを作りたいのですが(
フローイングデータ
):
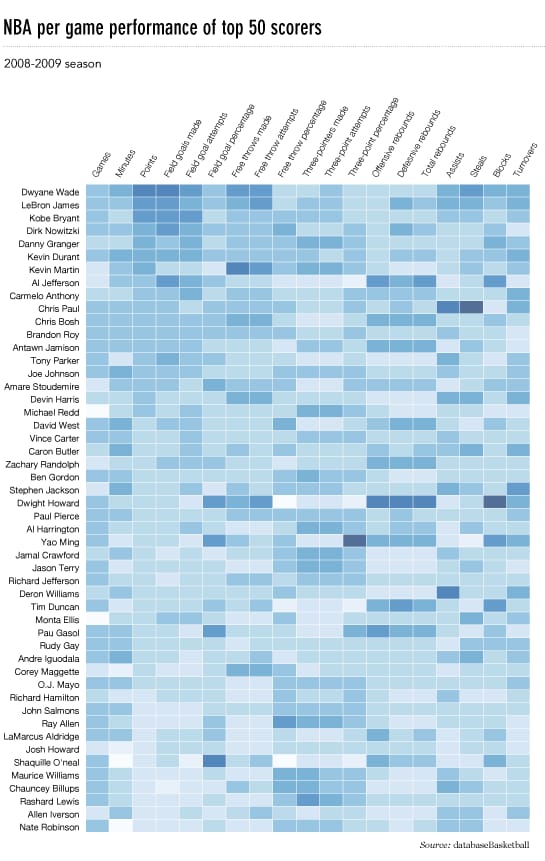
元データは ここに であるが、ランダムなデータやラベルを使用しても良いだろう、すなわち
import numpy
column_labels = list('ABCD')
row_labels = list('WXYZ')
data = numpy.random.rand(4,4)
ヒートマップの作成はmatplotlibで簡単にできます。
from matplotlib import pyplot as plt
heatmap = plt.pcolor(data)
そして、さらに
カラーマップ
の引数は、ほぼ正しいように見えます。
heatmap = plt.pcolor(data, cmap=matplotlib.cm.Blues)
しかし、それ以上に、列と行のラベルを表示する方法と、データを適切な方向(左下ではなく左上の原点)で表示する方法がわかりません。
を操作する試みは
heatmap.axes
(例えば
heatmap.axes.set_xticklabels = column_labels
) はすべて失敗しました。私はここで何を見逃しているのでしょうか?
どのように解決するのですか?
遅くなりましたが、flowingdata NBA heatmapのPython実装を紹介します。
更新日:2014/1/4 : みなさんありがとうございます。
# -*- coding: utf-8 -*-
# <nbformat>3.0</nbformat>
# ------------------------------------------------------------------------
# Filename : heatmap.py
# Date : 2013-04-19
# Updated : 2014-01-04
# Author : @LotzJoe >> Joe Lotz
# Description: My attempt at reproducing the FlowingData graphic in Python
# Source : http://flowingdata.com/2010/01/21/how-to-make-a-heatmap-a-quick-and-easy-solution/
#
# Other Links:
# http://stackoverflow.com/questions/14391959/heatmap-in-matplotlib-with-pcolor
#
# ------------------------------------------------------------------------
import matplotlib.pyplot as plt
import pandas as pd
from urllib2 import urlopen
import numpy as np
%pylab inline
page = urlopen("http://datasets.flowingdata.com/ppg2008.csv")
nba = pd.read_csv(page, index_col=0)
# Normalize data columns
nba_norm = (nba - nba.mean()) / (nba.max() - nba.min())
# Sort data according to Points, lowest to highest
# This was just a design choice made by Yau
# inplace=False (default) ->thanks SO user d1337
nba_sort = nba_norm.sort('PTS', ascending=True)
nba_sort['PTS'].head(10)
# Plot it out
fig, ax = plt.subplots()
heatmap = ax.pcolor(nba_sort, cmap=plt.cm.Blues, alpha=0.8)
# Format
fig = plt.gcf()
fig.set_size_inches(8, 11)
# turn off the frame
ax.set_frame_on(False)
# put the major ticks at the middle of each cell
ax.set_yticks(np.arange(nba_sort.shape[0]) + 0.5, minor=False)
ax.set_xticks(np.arange(nba_sort.shape[1]) + 0.5, minor=False)
# want a more natural, table-like display
ax.invert_yaxis()
ax.xaxis.tick_top()
# Set the labels
# label source:https://en.wikipedia.org/wiki/Basketball_statistics
labels = [
'Games', 'Minutes', 'Points', 'Field goals made', 'Field goal attempts', 'Field goal percentage', 'Free throws made', 'Free throws attempts', 'Free throws percentage',
'Three-pointers made', 'Three-point attempt', 'Three-point percentage', 'Offensive rebounds', 'Defensive rebounds', 'Total rebounds', 'Assists', 'Steals', 'Blocks', 'Turnover', 'Personal foul']
# note I could have used nba_sort.columns but made "labels" instead
ax.set_xticklabels(labels, minor=False)
ax.set_yticklabels(nba_sort.index, minor=False)
# rotate the
plt.xticks(rotation=90)
ax.grid(False)
# Turn off all the ticks
ax = plt.gca()
for t in ax.xaxis.get_major_ticks():
t.tick1On = False
t.tick2On = False
for t in ax.yaxis.get_major_ticks():
t.tick1On = False
t.tick2On = False
出力はこのようになります。
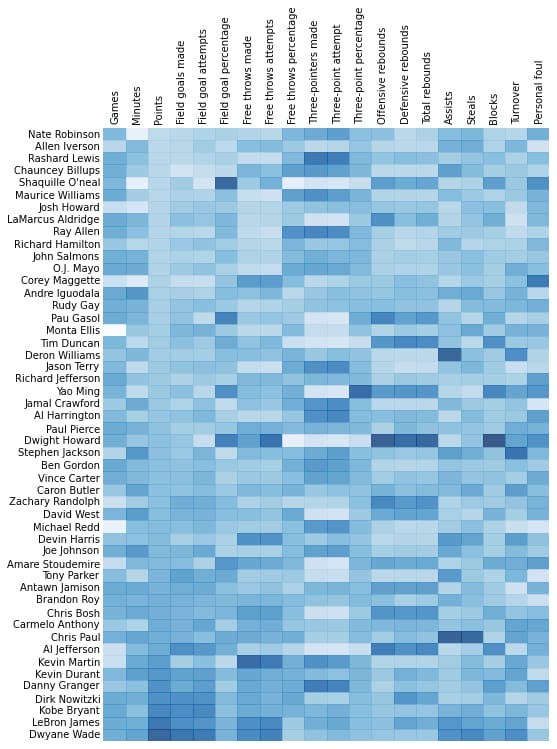
ipythonのノートブックにはこのようなコードが書かれています。 ここに . 私は'overflowから多くを学びましたので、誰かがこれを有用であることを望みます。
関連
-
[解決済み] pipでPythonの全パッケージをアップグレードする方法
-
[解決済み] Matplotlibでプロットを表示するのではなく、画像ファイルに保存する。
-
[解決済み] IPythonノートブックmatplotlibプロットをインラインで行う方法
-
[解決済み】Matplotlibで図のタイトルと軸ラベルのフォントサイズを設定するには?
-
[解決済み] matplotlib のプロットでフォントサイズを変更する方法
-
[解決済み] Pythonのキャッシュライブラリはありますか?
-
[解決済み] オブジェクトのリストに特定の属性値を持つオブジェクトが含まれているかどうかをチェックする
-
[解決済み] サブフォルダからのインポートモジュール
-
[解決済み] PySparkでデータフレームのカラムをString型からDouble型に変更する方法は?
-
[解決済み] Pythonの文字列の前にあるbという接頭辞は何を意味するのですか?
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み】Bokehでヒートマップを正しく作成する方法
-
[解決済み] Python pandasで共起行列を構築する
-
[解決済み] matplotlib で x 軸をプロットの先頭に移動する
-
[解決済み] PILからopenCVフォーマットへの変換
-
[解決済み] DataFrameに日付間の日数カラムを追加する pandas
-
[解決済み] オブジェクトのリストに特定の属性値を持つオブジェクトが含まれているかどうかをチェックする
-
[解決済み] tensorflowのCPUのみのインストールでダイナミックライブラリ 'cudart64_101.dll' を読み込めなかった
-
[解決済み] subprocess.run()の出力を抑制またはキャプチャするには?
-
[解決済み] matplotlib でプロットの軸、目盛、ラベルの色を変更する方法
-
[解決済み] Flaskで非同期タスクを作る