[解決済み] Locality Sensitive Hashingを理解するには?[クローズド]
2022-04-25 10:09:28
質問
LSHは、高次元の特性を持つ類似項目を見つけるのに適しているようですね。
論文を読んで http://www.slaney.org/malcolm/yahoo/Slaney2008-LSHTutorial.pdf とはいえ、これらの数式にはまだ戸惑いがありますね。
どなたか、それを簡単に説明しているブログや記事をご存じないでしょうか?
どのように解決するのですか?
LSHのチュートリアルは、私が見た中では、この本が一番です。Mining of Massive Datasetsにあります。 第3章 - 類似アイテムの検索をチェック http://infolab.stanford.edu/~ullman/mmds/ch3a.pdf
また、以下のスライドもおすすめです。 http://www.cs.jhu.edu/%7Evandurme/papers/VanDurmeLallACL10-slides.pdf . このスライドの例は、コサイン類似度に対するハッシュを理解する上でとても役に立ちました。
から2枚のスライドを拝借しています。
Benjamin Van Durme & Ashwin Lall, ACL2010
と、コサイン距離のLSH Familiesの直感を少し説明してみます。
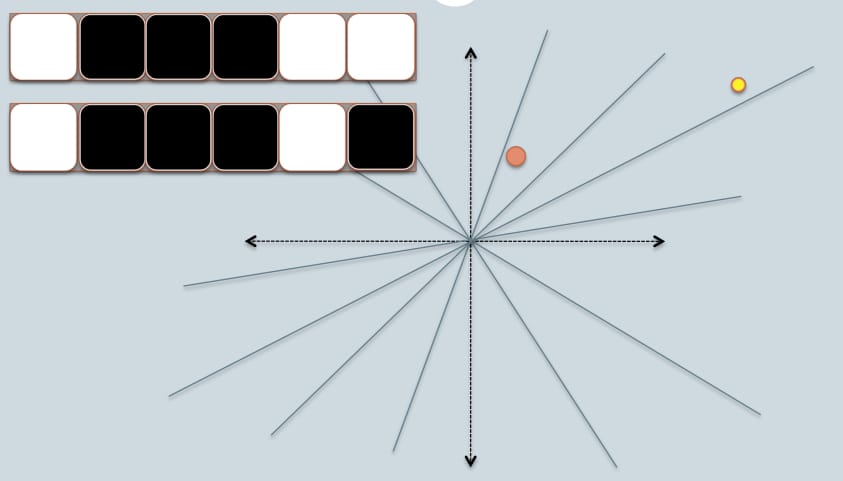
- 図の中に、2つの円w/があります。 赤 と 黄色 の色で、2つの2次元のデータ点を表しています。私たちは、その コサイン類似度 をLSHで使用しています。
- 灰色の線は、一様にランダムに選ばれたいくつかの平面である。
- データ点が灰色の線の上にあるか下にあるかによって、この関係を0/1とマークする。
- 左上には白と黒の正方形が2列並んでおり、それぞれ2つのデータ点の署名を表している。それぞれの正方形はビット0(白)または1(黒)に対応している。
- つまり、プレーンのプールがあれば、そのプレーンに対応する位置でデータポイントをエンコードすることができるのです。プールのプレーン数が多いほど、シグネチャにエンコードされる角度差は実際の差に近くなると想像してください。なぜなら、2つの点の間に存在する平面だけが、2つのデータに異なるビット値を与えるからです。
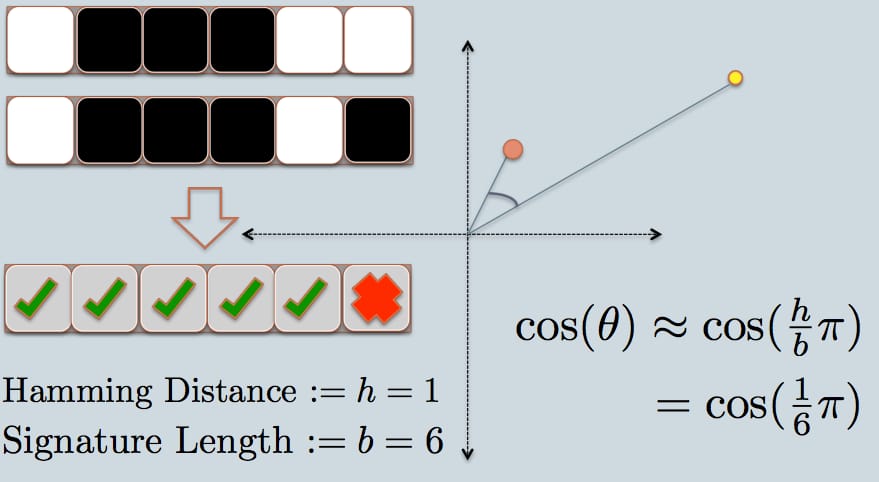
- ここで、2つのデータ点のシグネチャを見てみましょう。例と同じく、6ビット(四角)のみで各データを表現しています。これが手持ちの元データのLSHハッシュです。
- 2つのハッシュ値のハミング距離は、署名が1ビットしか違わないので、1である。
- 署名の長さを考慮すると、グラフのように両者の角度の類似性を計算することができます。
pythonでcosine similarityを使ったサンプルコード(50行だけ)があります。 https://gist.github.com/94a3d425009be0f94751
関連
-
C: 1を求める! + 2! + 3! + ... + n! (ループ)
-
[解決済み] 初期化でポインタ対象の型から修飾語を捨てる
-
[解決済み] Xcode - 警告。C99 では関数の暗黙の宣言は無効です。
-
[解決済み] C - Setデータ構造を実装するには?
-
[解決済み] 1ビットのセット、クリア、トグルはどのように行うのですか?
-
[解決済み] 配列の場合、なぜ a[5] == 5[a] になるのでしょうか?
-
[解決済み] 配列のすべてのメンバーを同じ値で初期化するには?
-
[解決済み] while ( !feof (file) ) 」は、なぜいつも間違っているのですか?
-
[解決済み] ストラクチャーとユニオンの違い
-
[解決済み】C言語の関数ポインタはどのように機能するのですか?
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
g++が内部・外部コマンドソリューションとして認識されない、MinGWを初めて使うときの落とし穴
-
[C] Error [Error] 代入の左オペランドとして lvalue が必要です。
-
警告:代入がキャストなしで整数からポインタを作成する場合の修正方法に関する警告
-
[解決済み] PTHREAD_MUTEX_INITIALIZER vs pthread_mutex_init ( &mutex, param )
-
[解決済み] Xcode - 警告。C99 では関数の暗黙の宣言は無効です。
-
[解決済み] c または c++ 用のシンプルな 2 次元クロスプラットフォームグラフィックスライブラリ?[クローズド]
-
[解決済み] ソケットアクセプト - "開かれているファイルが多すぎる"
-
[解決済み] printfにおけるdoubleの正しい書式指定子
-
[解決済み] char s[]とchar *sの違いは何ですか?
-
[解決済み] C言語でファイルが存在するかどうかを確認する最も良い方法は何ですか?