[解決済み] list()はリスト内包よりもわずかに多くのメモリを消費する
質問
というわけで、私は
list
オブジェクトで遊んでいて、ちょっと不思議なことを発見しました。
list
で作成された場合
list()
で作成された場合、リスト内包よりも多くのメモリを消費するのでしょうか?私はPython 3.5.2を使っています。
In [1]: import sys
In [2]: a = list(range(100))
In [3]: sys.getsizeof(a)
Out[3]: 1008
In [4]: b = [i for i in range(100)]
In [5]: sys.getsizeof(b)
Out[5]: 912
In [6]: type(a) == type(b)
Out[6]: True
In [7]: a == b
Out[7]: True
In [8]: sys.getsizeof(list(b))
Out[8]: 1008
からの ドキュメント :
リストはいくつかの方法で構築することができます。
- 角括弧のペアを使用して、空のリストを表します。
[]- 角括弧を使用し、カンマで項目を区切る。
[a],[a, b, c]- リスト内包を使用する。
[x for x in iterable]- タイプ・コンストラクタを使う。
list()またはlist(iterable)
しかし、どうやら
list()
を使うと、より多くのメモリを消費するようです。
また、同じくらい
list
が大きくなると、ギャップが大きくなります。
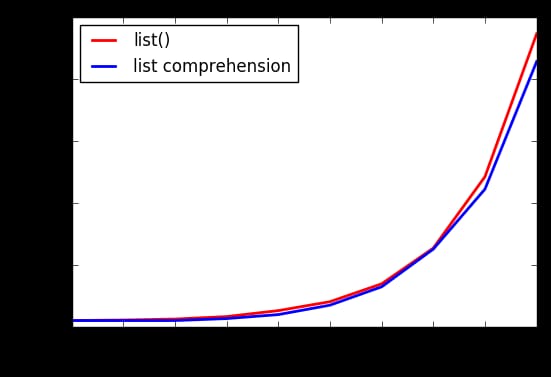
なぜこのようなことが起こるのでしょうか?
アップデイト1号
Python 3.6.0b2でテストしています。
Python 3.6.0b2 (default, Oct 11 2016, 11:52:53)
[GCC 5.4.0 20160609] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import sys
>>> sys.getsizeof(list(range(100)))
1008
>>> sys.getsizeof([i for i in range(100)])
912
アップデイト#2
Python 2.7.12でテスト。
Python 2.7.12 (default, Jul 1 2016, 15:12:24)
[GCC 5.4.0 20160609] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import sys
>>> sys.getsizeof(list(xrange(100)))
1016
>>> sys.getsizeof([i for i in xrange(100)])
920
どのように解決するのですか?
オーバーアロケーションのパターンが見られると思いますが、これは ソースのサンプルです。 :
/* This over-allocates proportional to the list size, making room
* for additional growth. The over-allocation is mild, but is
* enough to give linear-time amortized behavior over a long
* sequence of appends() in the presence of a poorly-performing
* system realloc().
* The growth pattern is: 0, 4, 8, 16, 25, 35, 46, 58, 72, 88, ...
*/
new_allocated = (newsize >> 3) + (newsize < 9 ? 3 : 6);
長さ0~88のリスト内包のサイズを印刷すると、パターンマッチを見ることができます。
# create comprehensions for sizes 0-88
comprehensions = [sys.getsizeof([1 for _ in range(l)]) for l in range(90)]
# only take those that resulted in growth compared to previous length
steps = zip(comprehensions, comprehensions[1:])
growths = [x for x in list(enumerate(steps)) if x[1][0] != x[1][1]]
# print the results:
for growth in growths:
print(growth)
結果(フォーマットは
(list length, (old total size, new total size))
):
(0, (64, 96))
(4, (96, 128))
(8, (128, 192))
(16, (192, 264))
(25, (264, 344))
(35, (344, 432))
(46, (432, 528))
(58, (528, 640))
(72, (640, 768))
(88, (768, 912))
オーバーアロケーションはパフォーマンス上の理由から行われ、リストが大きくなるたびにメモリを割り当てることなく、リストを大きくすることができます (よりよい アモルファス パフォーマンスが向上します)。
リスト内包を使用した場合と異なる理由として考えられるのは、リスト内包は生成されるリストのサイズを決定論的に計算することはできませんが
list()
では可能だからです。これは、最終的にリストを埋めるまで、オーバーアロケーションを使用してリストを埋めながら、内包が継続的に成長することを意味します。
オーバーアロケーションが完了すると、未使用の割り当て済みノードでオーバーアロケーションバッファを拡大しない可能性があります (実際、ほとんどの場合、それはオーバーアロケーションの目的を達成するものではありません。)。
list()
は、最終的なリストサイズを事前に知っているので、リストサイズに関係なくいくつかのバッファを追加することができます。
もう 1 つの裏付けとなる証拠は、同じくソースにあるように
リスト内包が
LIST_APPEND
の使用を示しています。
list.resize
の使用を示しています。これは、プレアロケーションバッファがどの程度満たされるかを知らずに消費していることを示しています。これは、あなたが見ている動作と一致しています。
結論から言うと
list()
はリストサイズの関数として、より多くのノードを事前に割り当てます。
>>> sys.getsizeof(list([1,2,3]))
60
>>> sys.getsizeof(list([1,2,3,4]))
64
リスト内包はリストサイズを知らないので、リストが大きくなると追加操作を行い、プレアロケーションバッファを枯渇させます。
# one item before filling pre-allocation buffer completely
>>> sys.getsizeof([i for i in [1,2,3]])
52
# fills pre-allocation buffer completely
# note that size did not change, we still have buffered unused nodes
>>> sys.getsizeof([i for i in [1,2,3,4]])
52
# grows pre-allocation buffer
>>> sys.getsizeof([i for i in [1,2,3,4,5]])
68
関連
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み] 2つの同じリストが異なるメモリフットプリントを持つのはなぜですか?
-
[解決済み] Jupyterノートブックでenv変数を設定する方法
-
[解決済み] Pythonのキャッシュライブラリはありますか?
-
[解決済み] バブルソートの宿題
-
[解決済み] SQLAlchemy: 日付フィールドをフィルタリングする方法は?
-
[解決済み] 古いバージョンのPythonにおける辞書のキーの並び順
-
[解決済み] あるメソッドが複数の引数のうち1つの引数で呼び出されたことを保証する
-
[解決済み] Django filter queryset __in for *every* item in list
-
[解決済み] なぜタプルはリストよりも少ないメモリ容量で済むのですか?
-
[解決済み] メモリ上のリストのサイズ