linuxのawkコマンドを詳しく説明します。
1. AWKの紹介
AWKはテキストファイルを扱うための言語で、強力なテキストパースツールです。
2. AWKの構文
awk [option argument] 'script' var=value file(s)
or
awk [option argument] -f scriptfile var=value file(s)
オプション引数の説明。
-F fs または -field-separator fs
入力ファイルのフォールドセパレータを指定します。fsは文字列、または-Fのような正規表現です。-v var=value または -asign var=value
ユーザー定義変数を代入する。-f scripfile または -file scriptfile
スクリプトファイルから awk コマンドを読み込む。-mf nnn および -mr nnn
nnn 値に本質的な制限を設定し、-mf オプションは nnn に割り当てられるブロックの最大数を制限し、-mr オプションはレコードの最大数を制限する。これら 2 つの機能は Bell Labs 版 awk の拡張機能であり、標準の awk では利用できません。-W compact または -compat, -W traditional または -traditional
awk を互換モードで実行し、gawk は標準 awk と全く同じように動作し、awk の拡張機能は全て無視されます。-W copyleft または -copyleft、-W copyright または -copyright
短い著作権メッセージを表示します。-Wヘルプまたは-help、-W使用法または-usage
awk の全オプションと各オプションの短い説明を表示します。-W lint または -lint
レガシーな Unix プラットフォームに移植できない構造体に対する警告を表示します。-W lint-old または -lint-old
レガシーなUnixプラットフォームに移植できない構造物に関する警告を表示します。-W posix
互換モードをオンにします。以下の制約があり、認識されない。/x、関数キーワード、func、並べ換えシーケンス、fsがスペースのときにフィールドセパレータとしてニューラインを使用すること、演算子 と = は ^ と ^= を置き換えることはできない; fflush は有効でない。-W re-interval または -re-inerval
括弧付きの表現 [[:alpha:]] のような、(grep の Posix 文字クラス) 参照のインターバル正規表現を使用できるようにします。-W ソースプログラム-テキスト または -ソースプログラム-テキスト
program-textをソースコードとして使用し、-fコマンドと混在させることができます。-Wバージョンまたは-バージョン
バグ報告メッセージのバージョンを表示します。
3. 基本的な使い方
テキストの一部: cat log.txt
2 This is a test
3 Are you like awk
This's a test
10 There are orange,apple,mongo
使用法1
awk '{[パターン] アクション}' {ファイル名}. # ラインマッチ文 awk " シングルクォートのみ
例
# Each line is split by space or TAB (the default), outputting items 1 and 4 in the text
$ awk '{print $1,$4}' log.txt
---------------------------------------------
2 a
3 like
This's
10 orange,apple,mongo
---------------------------------------------
# Format the output
$ awk '{printf "%-8s %-10s\n",$1,$4}' log.txt
---------------------------------------------
2 a
3 like
This's
10 orange,apple,mongo
使用法2
awk -F #-F は組み込み変数 FS と等価で、分割文字を指定します。
例
# log.txt reads.
# 2,this,is,a,test
# 3 Are you like awk
$ awk -F, '{print $1,$2}' log.txt
---------------------------------------------
2 this
3 Are you like awk
# Use multiple separators. Split with spaces, then split the result with ","
$ awk -F '[,]' '{print $1,$2,$5}' log.txt
---------------------------------------------
2 this
3 Are
使用法3
awk -v # 変数を設定する
インスタンスです。
$ awk -va=1 '{print $1,$1+a}' log.txt
---------------------------------------------
2 3
3 4
This's 1
10 11
$ awk -va=1 '{print $1,$(1+a)}' log.txt
---------------------------------------------
2 this
3 Are
This's a
10 There
$ awk -va=1 -vb=s '{print $1,$1+a,$1b}' log.txt
---------------------------------------------
2 3 2s
3 4 3s
This's 1 This'ss
10 11 10s
使用法4
awk -f {awkスクリプト} {ファイル名}.
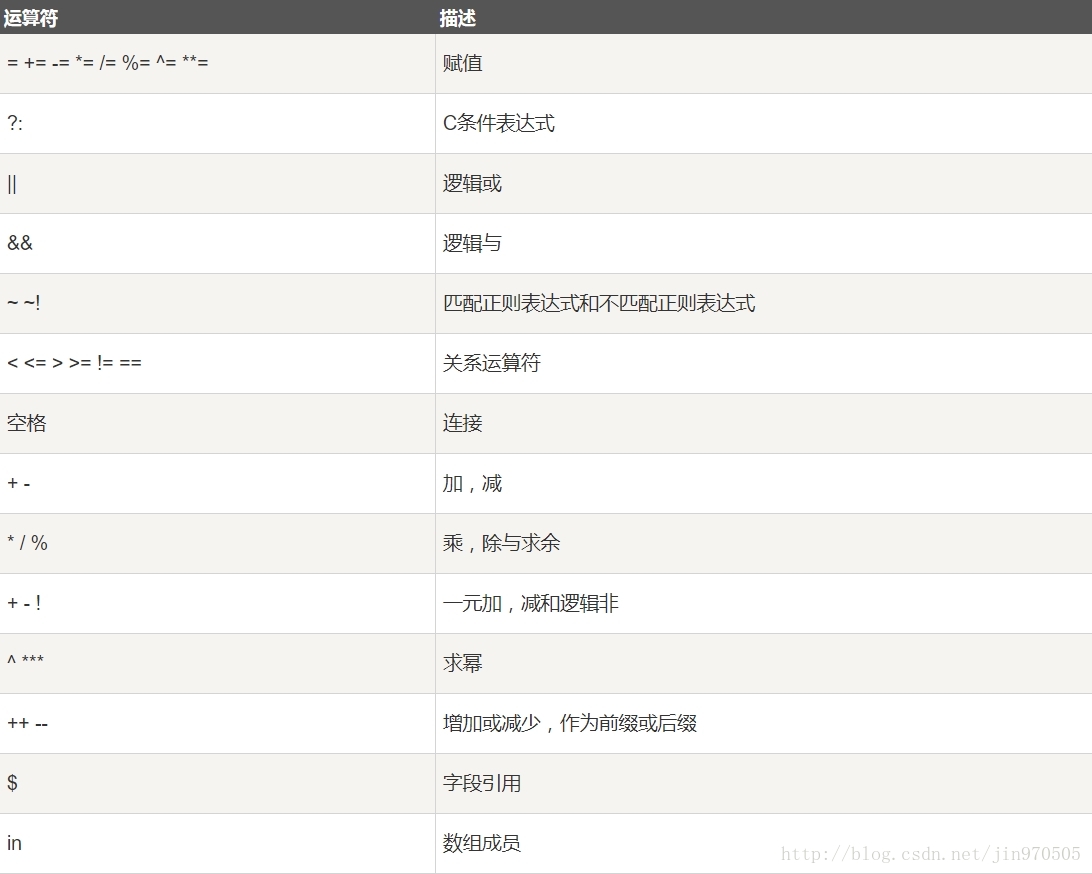
4. 演算子
最初の列が2より大きい行をフィルタリングする。
$ awk '$1>2' log.txt # command
# output
3 Are you like awk
This's a test
10 There are orange,apple,mongo
最初の列が2に等しい行をフィルタリングする。
$ awk '$1==2 {print $1,$3}' log.txt # command
# output
2 is
最初の列が2より大きく、2番目の列が'Are'に等しい行をフィルタリングする。
$ awk '$1>2 && $2=="Are" {print $1,$2,$3}' log.txt #command
#output
3 Are you
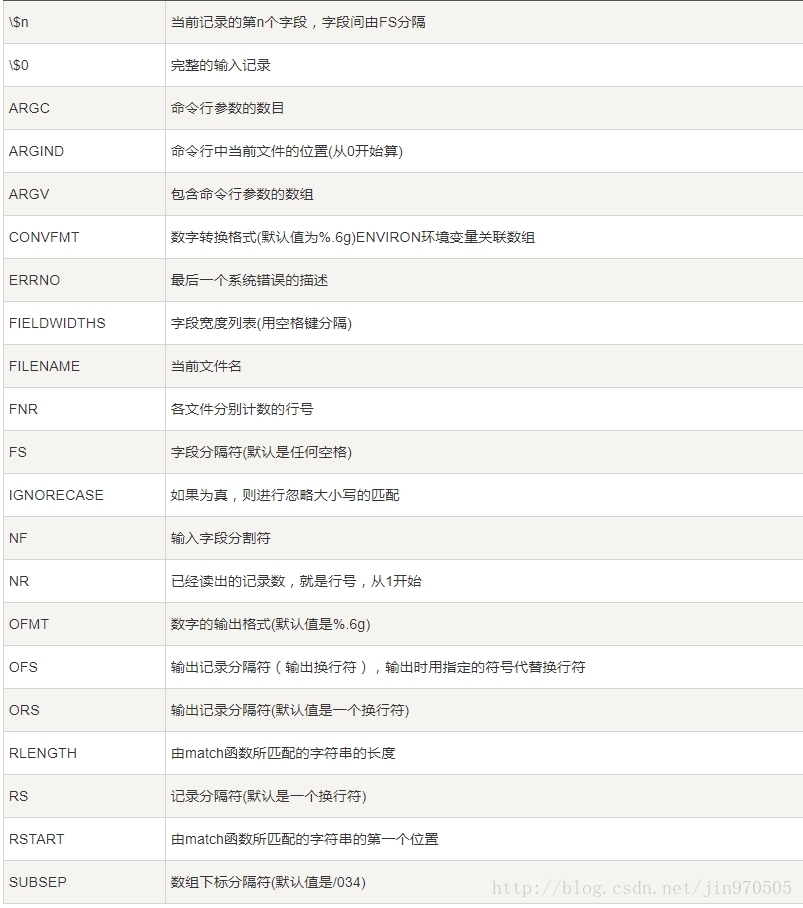
5. ビルトイン変数
# Output sequence number NR, matching text line number
$ awk '{print NR,FNR,$1,$2,$3}' log.txt
---------------------------------------------
1 1 2 This is
2 2 3 Are you
3 3 This's a test
4 4 10 There are
# Specify the output separator
$ awk '{print $1,$2,$5}' OFS=" $ " log.txt
---------------------------------------------
2 $ this $ test
3 $ Are $ awk
This's $ a $
10 $ There $
6. 正規表現の使用
# Output the second column containing "th" and print the second and fourth columns
$ awk '$2 ~ /th/ {print $2,$4}' log.txt
---------------------------------------------
this a
~ はパターン開始を示します。// In はパターンです。
# Output the line containing "re"
$ awk '/re/ ' log.txt
---------------------------------------------
3 Are you like awk
10 There are orange,apple,mongo
ケースを無視する。
$ awk 'BEGIN{IGNORECASE=1} /this/' log.txt
---------------------------------------------
2 this is a test
This's a test
パターン反転。
$ awk '$2 ! ~ /th/ {print $2,$4}' log.txt
---------------------------------------------
Are like
a
There orange,apple,mongo
$ awk '! /th/ {print $2,$4}' log.txt
---------------------------------------------
Are like
a
There orange,apple,mongo
7. awkスクリプト
awkスクリプトについては、BEGINとENDという2つのキーワードに注意する必要があります。
BEGIN{ 実行前のステートメントを入れる }.
END { これは、すべての行の処理が終わった後に実行されるステートメントを置きます }。
{各行が処理されたときに実行されるステートメントです}。
このようなファイル(生徒の成績表)があったとします。
$ cat score.txt
Marry 2143 78 84 77
Jack 2321 66 78 45
Tom 2122 48 77 71
Mike 2537 87 97 95
Bob 2415 40 57 62
awkスクリプトは以下の通りです。
$ cat cal.awk
#! /bin/awk -f
# before running
BEGIN {
math = 0
english = 0
computer = 0
printf "NAME NO. MATH ENGLISH COMPUTER TOTAL\n"
printf "---------------------------------------------\n"
}
# Running
{
math+=$3
english+=$4
computer+=$5
printf "%-6s %-6s %4d %8d %8d %8d\n", $1, $2, $3,$4,$5, $3+$4+$5
}
# After running
END {
printf "---------------------------------------------\n"
printf " TOTAL:%10d %8d %8d \n", math, english, computer
printf "AVERAGE:%10.2f %8.2f %8.2f\n", math/NR, english/NR, computer/NR
}
実行結果。
$ awk -f cal.awk score.txt
NAME NO. MATH ENGLISH COMPUTER TOTAL
---------------------------------------------
Marry 2143 78 84 77 239
Jack 2321 66 78 45 189
tom 2122 48 77 71 196
Mike 2537 87 97 95 279
Bob 2415 40 57 62 159
---------------------------------------------
TOTAL: 319 393 350
AVERAGE: 63.80 78.60 70.00
8. その他の例をいくつか紹介します。
ファイルサイズを計算する。
$ ls -l *.txt | awk '{sum+=$6} END {print sum}'
--------------------------------------------------
666581
ファイルから80より長い行を検索する。
awk 'length>80' log.txt
9-9-9の掛け算表を印刷する。
seq 9 | sed 'H;g' | awk -v RS='' '{for(i=1;i<=NF;i++)printf("%dx%d=%d%s", i, NR, i*NR, i==NR?"\n":"\t")}'
関連
-
"collect2: error: ld returned 1 exit status" の解決法
-
スクリプトが ssh を呼び出した後、stdin がターミナルでないため、疑似ターミナルが割り当てられない
-
MongoDBインストール+解決エラー。mongod.service の起動に失敗しました:until not found
-
VNC mesg を開くとき: ttyname に失敗しました。デバイスに不適切な ioctl
-
プログラム下部の2つのスイスアーミーナイフをこじ開ける
-
ImportError: Flaskという名前のモジュールがなく、パッケージのインポートに失敗しました。
-
PackagesNotFoundError: 以下のパッケージは、現在のチャネルから利用できません。
-
CentOS 7 エラー: curl#60 - "ピアの証明書は有効期限が切れています。"
-
ubuntuでグローバルシステムエージェントを設定する
-
シェルスクリプトに$0, $? , $! , $$, $*, $#, $@ などのシェルスクリプトとlinuxコマンド実行時の戻り値の意味
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
Racer版 - CentOS7システムインストールと構成図のチュートリアル
-
SSHパスワードフリーログイン設定後、stdinがターミナルでないため、疑似ターミナルが割り当てられない。
-
解決 ERROR: EnvironmentError のため、パッケージをインストールできませんでした。[Errno 28] デバイスに空き領域がありません。
-
警告について:互換性のないポインタ型からの初期化【デフォルトで有効
-
mach-mini2440.c:155: error: array type has incomplete element type
-
Linuxでビジー状態のテキストファイルでプログラムを実行する場合の対処法
-
Linuxでよくあるパーミッション関連のエラーとその解決法
-
nginx: [emerg] 0.0.0.0:80 への bind() に失敗しました (13: Permission denied)。
-
Ansibleの通常ユーザーsudoがコマンドを実行します。
-
dpkg: パッケージの処理エラー ***(--install): 依存関係の問題 - 未設定にする