知識蒸留法(Knowledge Distillation)
<スパン 1. ニューラルネットワークの知識の抽出
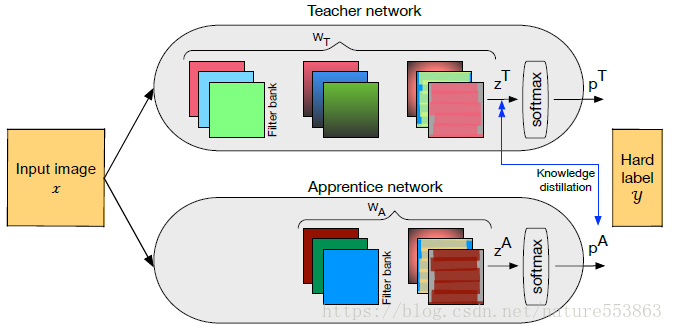
Hintonの論文 "Distilling the Knowledge in a Neural Network" は、知識移転のために教師ネットワーク(教師ネットワーク:複雑だが予測精度に優れている)に関連するソフトターゲット(Soft-)を導入することで、知識の蒸留(暗黙知抽出)の概念を最初に導入した。 Total lossの一部としてターゲット)により学生ネットワーク(学生ネットワーク:合理的、低複雑、推測展開により適した)の訓練を誘導し知識を移転させることができた。
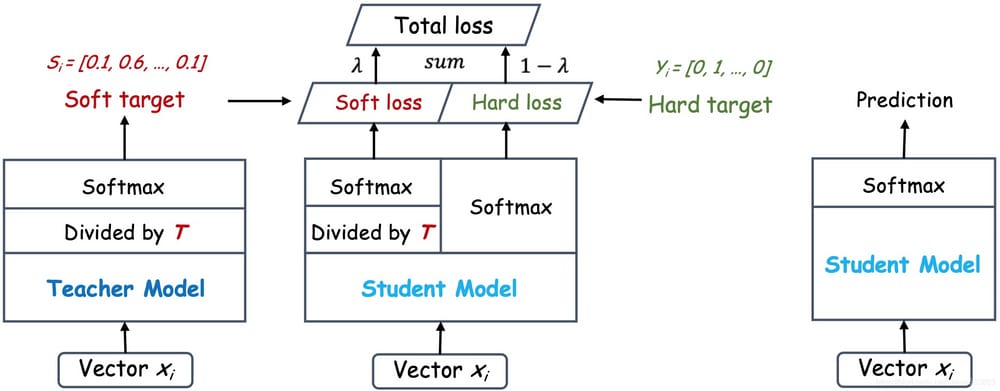
上図のように、教師ネットワークの予測出力(左)を温度パラメータ(Temperature)で割った後、Softmaxを計算し、0から1の間の値で、より緩やかな確率分布(ソフトターゲットまたはソフトラベル)を得る。 が減少すると、誤判別確率が増幅され、不必要なノイズが入る傾向がある。より困難な分類や検出タスクでは、教師ネットワークにおける正しい予測の寄与を確保するために、通常、温度は1とされる。一方、ハードターゲットはサンプルの真のラベリングであり、これはOne-hotベクトルによって表現されうる。 総損失は、ソフトターゲットとハードターゲットに対応するクロスエントロピーの加重平均(KD損失、CE損失と表記)として設計されており、ソフトターゲットのクロスエントロピーの加重係数が大きいほど、移動誘導が教師ネットワークの寄与に大きく依存することを示す。を助ける。 これは、学習初期には生徒ネットワークが簡単なサンプルを識別しやすくするために必要であるが、学習後期には真のラベリングが難しいサンプルを識別するのに役立つように、ソフトターゲットの重みを適切に減らす必要がある。また、通常、教師ネットワークの予測精度は生徒ネットワークよりも優れているが、モデル容量には特に制限がなく、教師ネットワークの推論精度が高いほど、生徒ネットワークの学習も良好になる。
<スパン また、教師ネットワークの暗黙知や学習スタイルが生徒ネットワークの学習に影響を与える場合、以下のように教師ネットワークと生徒ネットワークを共同学習させることができる(式中の3項は、教師ネットワークのSoftmax出力のクロスエントロピ損失、生徒ネットワークのSoftmax出力のクロスエントロピ損失、教師ネットワークの数値出力と生徒ネットワークのSoftmax出力のクロスエントロピ損失の3つである)。
共同学習した論文のアドレス。 https://arxiv.org/abs/1711.05852
![]()
2. 効率的なハードウェアソリューションのためのディープニューラルネットワークの知識抽出の探求
GitHubのアドレスです。 https://github.com/peterliht/knowledge-distillation-pytorch
この記事では、Total lossを以下のように再定義しています。
![]()
Total lossのPyTorchコードは以下の通りで、Teacherネットワーク出力に対するStreamlinedネットワーク出力のKL分散を導入し、誘導学習時にTeacherネットワークの予測出力を先にCPUメモリにキャッシュして、GPUメモリのOverheadを軽減することが可能です。
def loss_fn_kd(outputs, labels, teacher_outputs, params):
"""
Compute the knowledge-distillation (KD) loss given outputs, labels.
"Hyperparameters": temperature and alpha
NOTE: the KL Divergence for PyTorch comparing the softmaxs of teacher
and student expects the input tensor to be log probabilities!
"""
alpha = params.alpha
T = params.temperature
KD_loss = nn.KLDivLoss()(F.log_softmax(outputs/T, dim=1),
F.softmax(teacher_outputs/T, dim=1)) * (alpha * T * T) + \
F.cross_entropy(outputs, labels) * (1. - alpha)
return KD_loss
<スパン 3. 複数の講師によるアンサンブル
用紙の宛先です。 教師のアンサンブルから効率的に知識を抽出する|Request PDF
最初のアルゴリズム 複数の教師ネットワークから出力されたSoft labelを重み付きで結合して統一Soft labelを作成し、このSoft labelが生徒ネットワークの学習の指針となる: The

2つ目のアルゴリズム 加重平均アプローチは複数の教師ネットワークの予測値を弱め、滑らかにするため、特定の教師ネットワークのSoftラベルをGuidanceとしてランダムに選択することができます。

第3のアルゴリズム ここでも加重平均による平滑化を避けるため、教師ネットワークのSoft label出力をまずサンプルの再ラベル化に使い、データを補強してからモデルの学習に使うことで、同じサンプルデータの異なる特徴をより多くの視点から見て学習することができる。

<スパン 4. ヒントに基づく知識伝達
用紙の宛先です。 https://arxiv.org/abs/1412.6550
GitHubのアドレスです。 https://github.com/adri-romsor/FitNets
より深く、より薄い生徒ネットワーク(Deeper and thinner FitNet)の学習を誘導できるようにするためには、教師ネットワークの中間層のFeature Mapsを(Hintとして)考慮する必要があり、これは生徒ネットワークの対応するGuided層を誘導するために使われる。このとき、学習プロセスを誘導するためにL2損失を導入する必要があり、この損失は教師ネットワークのHint層と生徒ネットワークのGuided層の出力の間の差として算出する。両者の出力Feature Mapsの形状が一致しない場合、Guided層は以下のように追加で回帰層を通過させる必要がある。
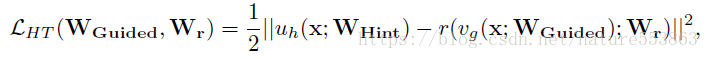
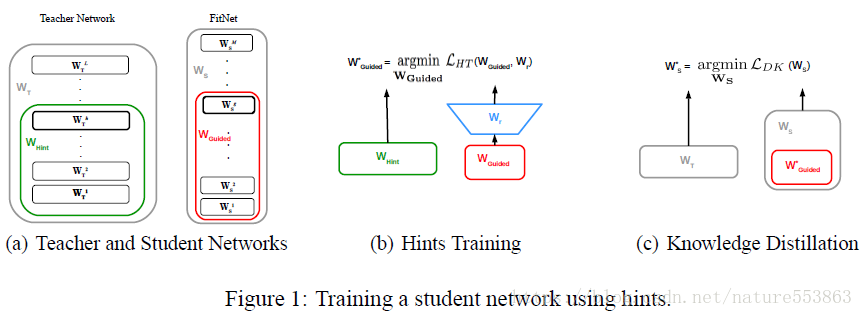
具体的なトレーニングの流れは、2段階に分けて完成させました。 第一段階では、ヒントに基づく損失を用いて、生徒ネットワークを適切な初期化状態に誘導する(W_GuidedとW_rのみを更新)。第二段階では、教師ネットワークのソフトラベルを用いて生徒ネットワーク全体の学習を誘導し(すなわち、知識蒸留)、Total lossのソフトターゲット関連部分の割合が徐々に減少していく 第二段階では、教師ネットワークのソフトラベルを用いて生徒ネットワーク全体の学習を誘導し(すなわち。知識蒸留)、ソフトターゲットに関連する全損失の割合が徐々に減少し、生徒ネットワークは簡単なサンプルと難しいサンプルを完全に識別できるようになる(教師ネットワークは簡単なサンプルを効果的に識別できるが、難しいサンプルは本当のラベル、すなわちハードターゲットが必要である)。

<スパン 5. アテンションからアテンションへの移行
用紙の宛先です。 https://arxiv.org/abs/1612.03928
GitHubのアドレスです。 https://github.com/szagoruyko/attention-transfer
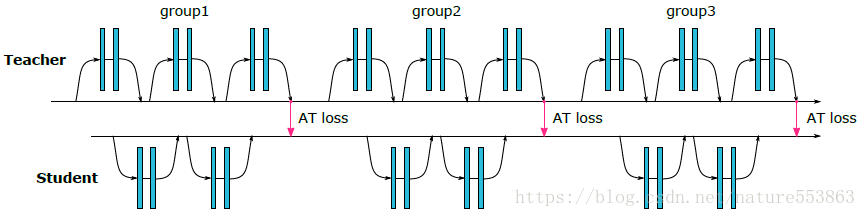
By ネットワークミドルティアのアテンションマップ 教師ネットワークと生徒ネットワーク間の知識の移行を完了させるものである。与えられたTensor Aを考えると、Activationに基づくAttention mapは以下の3つのうちの1つとして定義できる。
<イグ
<スパン ネットワークレベルが深くなるにつれて、重要な領域のアテンションレベルも高くなる。本稿では最終的にp=2をとる第2形式のアテンションマップを採用し、アクティベーションベースのアテンションマップの知識移動効果は勾配ベースのアテンションマップより優れており、損失定義と移動プロセスは以下の通りである。
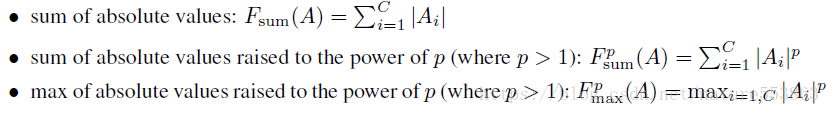
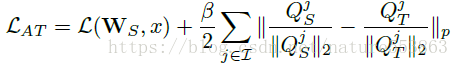
![]()
<スパン 6. 解答手順の流れ
用紙の宛先です。
http://openaccess.thecvf.com/content_cvpr_2017/papers/Yim_A_Gift_From_CVPR_2017_paper.pdf
暗黙知は学習された解答手順(FSP: Flow of Solution Procedure)としても表現でき、教師ネットワークや生徒ネットワークのFSP行列は次のように定義される(Gram形式の行列)。
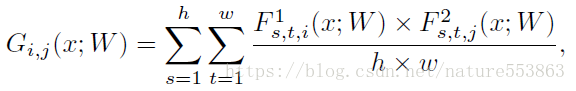
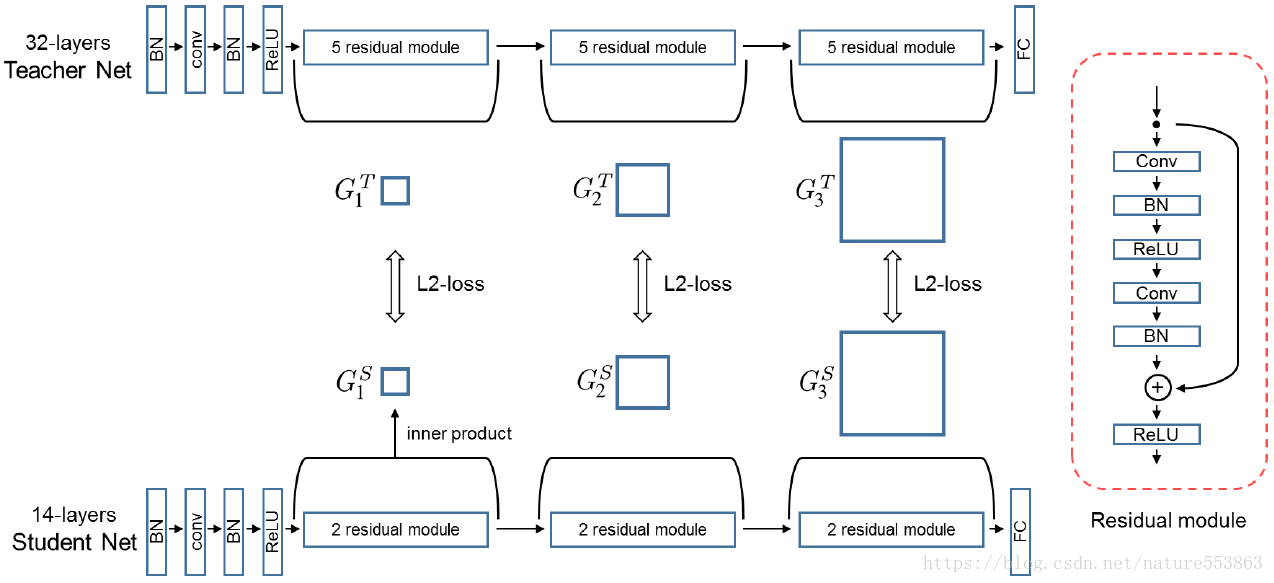
トレーニングの第一段階。教師ネットワークのFSP行列と生徒ネットワークのFSP行列の間のL2損失を最小化し、生徒ネットワークの訓練可能なパラメータを初期化する。
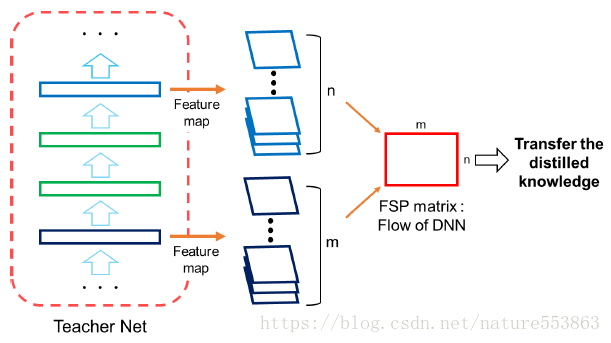
トレーニングの第2段階:ターゲットタスクのデータセットで生徒のネットワークを微調整する。これにより、知識の伝達、高速な収束、転移学習が実現される。
<スパン 7. 決定境界をサポートする逆境サンプルによる知識抽出
用紙の宛先です。 https://arxiv.org/abs/1805.05532
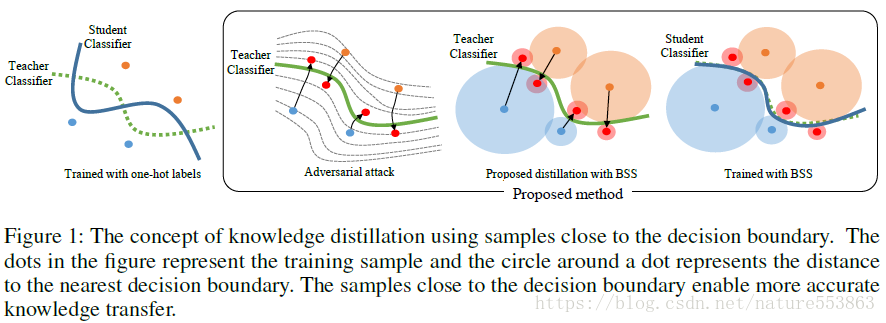
また、分類の決定境界については、教師ネットワークが生徒ネットワークに決定境界を効果的に識別させるプロセスとして理解することができ、識別がうまくいけば、モデルの一般化もうまくいくことになる。
本論文では、まず、敵対的攻撃戦略を用いて、ベースクラスのサンプルを決定境界付近に位置するターゲットクラスのサンプルに変換し(BSS: boundary supporting sample)、次に、敵対的生成サンプルを用いて、学生ネットワークの学習を誘導する。 これにより、決定境界に対する学生ネットワークの識別能力を効果的に向上させることが可能である。この論文では、以下のように停止条件を満たすまで、Loss関数の勾配(ベースクラスのスコアとターゲットクラスのスコアの差)の負の方向に沿って調整する必要がある、繰り返しアプローチで敵対的サンプルを生成している。
Loss関数は以下のように定義される。
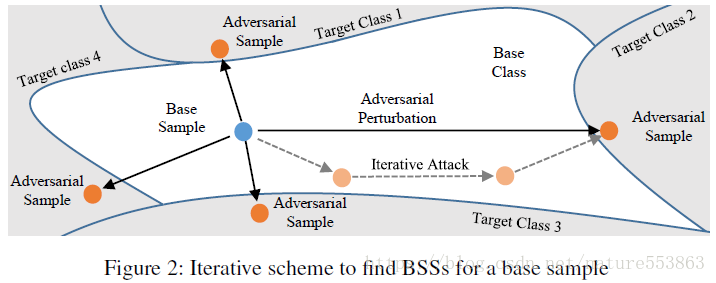
<スパン Loss関数の勾配の負の方向に沿ってサンプルを調整します。
![]()
<スパン 停止条件(3つのうち1つを満たしていればOK)。
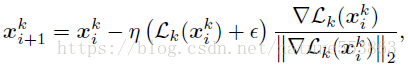
敵対的に生成されたサンプルと合わせて、教師ネットワークを用いた生徒ネットワークの学習に必要な総損失は、CE損失、KD損失、Boundary supporting損失(BS損失)である。
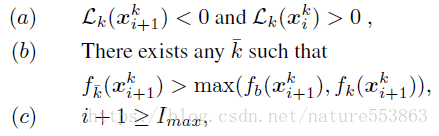
<スパン 8. Label Refinery: Label ProgressionによるImageNet分類の改善
GitHubのアドレスです。 https://github.com/hessamb/label-refinery
本論文では、学習時にサンプルのCropとLabelの不整合に着目した学習を繰り返し誘導し、Labelの質を高めることで、モデルの汎化能力をさらに向上させる。
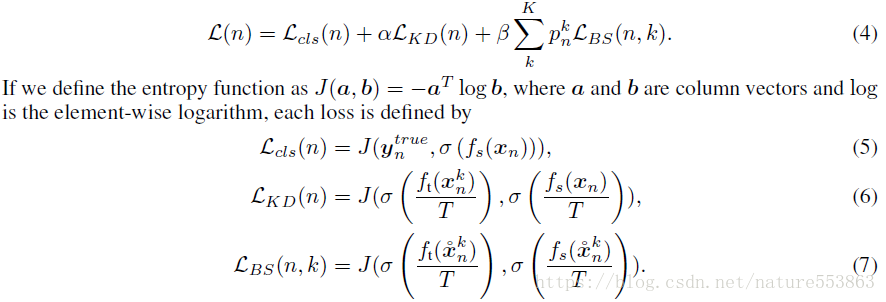
誘導中の総損失は、前回の反復(Label Refinery:教師ネットワークの役割と同様)の出力に対する今回の反復(t>1)のネットワークの予測出力(確率分布)のKL分散で表される。
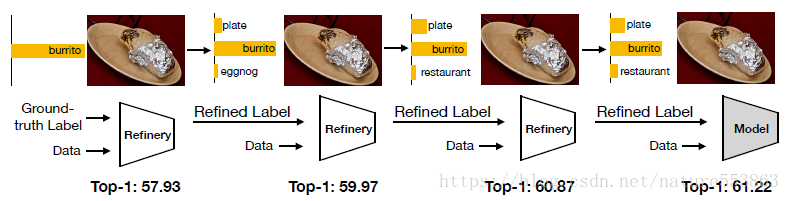
実験部分では、学習用ネットワークだけでなく、他の高品質ネットワーク(Resnet50など)をLabel Refinery Networkとして利用することが可能であることを示した。 また、データ拡張のための誘導過程でのサンプル生成に対抗することが可能であることを示した。
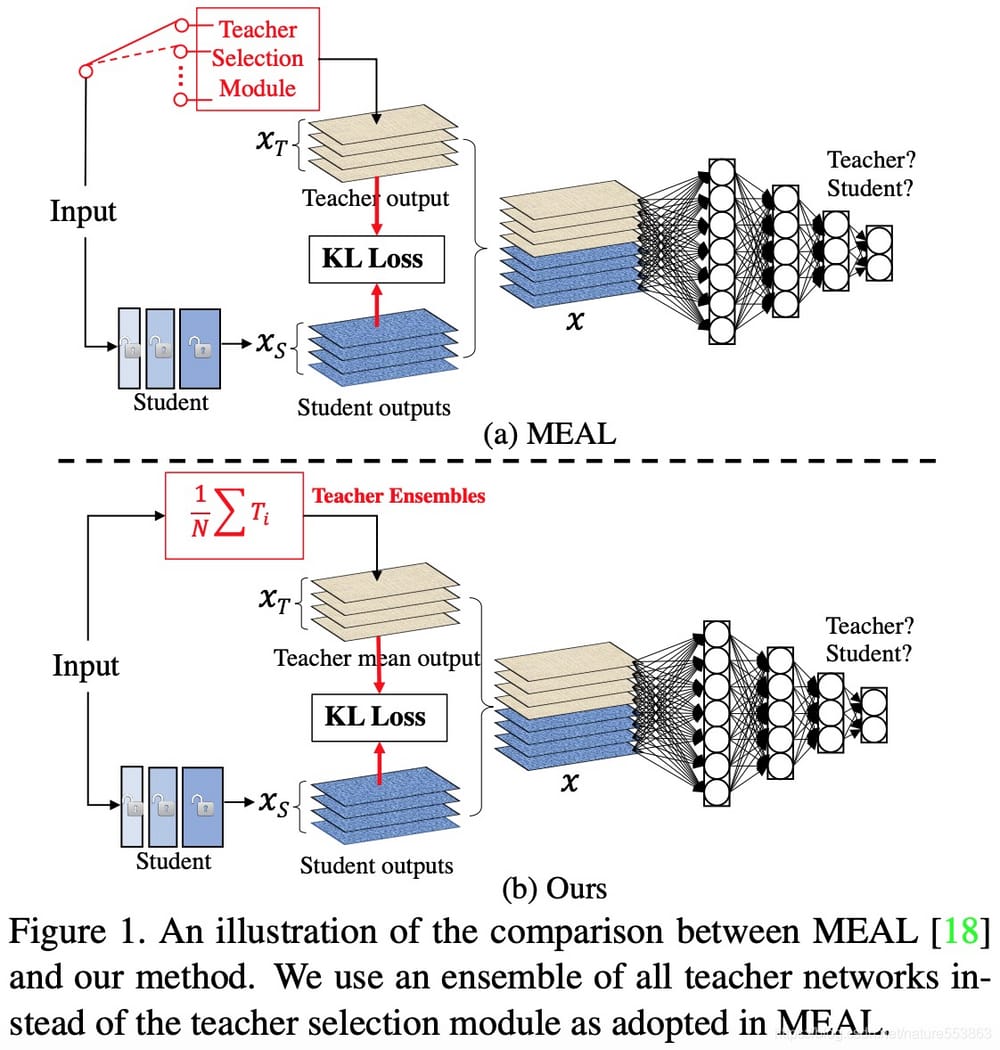
<スパン 9. ミールV2 KD(マルチティーチャーズによるアンサンブル)
用紙の宛先です。 https://arxiv.org/abs/2009.08453
GitHubです。 https://github.com/szq0214/MEAL-V2
MEAL V2の基本的な考え方は、複数の教師モデルの効果を、知識の蒸留によって、1つの生徒モデルにアンサンブル、移行することである。教師モデルの統合、KL scatterloss、および識別器:。
- 複数のTeachersの予測確率を平均化する。
- <スパン TeacherのSoftラベルのみに依存する。
- 正則化として作用する識別器。
- <スパン Studentは事前に学習されたモデルでスタートするため、蒸留学習のオーバーヘッドを軽減することができます。

<スパン 10. 軽量顔検出機用KD
論文のアドレス
顔検出モデルの分類予測出力であり、典型的な2値分類(0-背景、1-顔)である。顔検出モデルでは、通常、回帰マップよりも教師ネットワークと生徒ネットワークの分類マップの方が差が大きく、分類マップから得られるSoft labelが教師情報として利用される可能性が高いと考えられています。また、教師ネットワークと生徒ネットワークの出力スコアの差に基づいて、単純なサンプルをフィルタリングし、オンラインのハードケースマイニングを実装し、生徒ネットワークの学習に対して効果的な監視を行う必要がある。
<スパン 損失関数は以下のように実装されている。
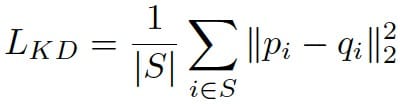
def kd_loss(teacher_output, student_output, alpha=50.0):
teacher_output = F.softmax(teacher_output, dim=-1)
student_output = F.softmax(student_output, dim=-1)
scale = 16.2 # when beta=6.4 and gamma=3.2
beta = 6.4
threshold = scale * torch.pow(torch.abs(teacher_output[:, :, 1] - 0.5), beta)
mask = teacher_output[:, :, 1] > threshold
t_feat = teacher_output[mask]
f_feat = student_output[mask]
loss = torch.nn.functional.mse_loss(t_feat, f_feat)
return loss * alpha
<スパン 11. 知識の蒸留と自己監視の出会い
用紙の宛先です。 https://arxiv.org/pdf/2006.07114.pdf
<スパン GitHub GitHub - xuguodong03/SSKD
SSKD (使用 S エルフ S の補助タスクとしての教師あり学習 K ナレッジ D イズティレーション ) 副次的なタスクとしての自己教師あり学習 を使い、知識の蒸留を行う。従来のKDでは、生徒ネットワークはタスク層に関する教師ネットワークの予測出力(分類、位置回帰など)を模倣するが、SSKDでは、変換されたデータセットと自己教師付き補助タスクでより豊かな構造化知識伝達を実現することが可能である。そのため 対照学習(Contrastive learning) は自己教師付き学習で良好なパフォーマンスを発揮するので SSKDは自己教師付き補助タスクとしてコントラスト学習を選択する。 コントラスト学習は、ネットワークが正と負のサンプルを区別できるようにすることで、変換前後の各サンプルの類似性を最大化し、モデルが変換不変性を持つ表現を学習することを可能にする。この論文では、異なる表現間の類似度を測定するためにコサイン関数を用い、類似度行列を構築する。次に類似度行列のSoftmaxを計算し、変換後のサンプルがある元のサンプルと正のサンプル対である確率を表現する。
<スパン SSKDでは、生徒が課題に関する知識(正または負のサンプル予測)を学ぶ一方で、教師の特徴量(正と負のサンプルの識別)の能力を模倣する必要があるため、次のようになります。 損失関数は次のように表される。 (LceはHard label driven loss、LkdはSoft label driven lossを意味する)。
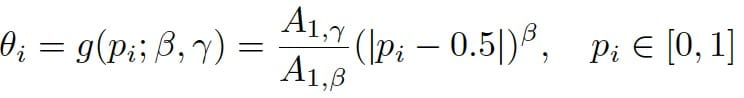
![]()
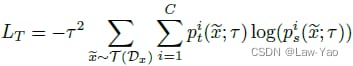
SSKDは次のような場合に最適です。 不適切な表示 (無印のシナリオではLceを削除することができます)。 および数発のアプリケーションシナリオ (表現に関連する知識の移行をコントラスト学習に依存する)。また、SSKDはFinal layerの移行知識のみに依存するため、異種ネットワークの誘導学習にも適している。 SSKDの具体的なアプリケーションフレームワークを下図に示す。 教師ネットワークと生徒ネットワークはともに、次のような構成になっています。 3つの要素 : 特徴抽出のためのバックボーン、一次タスクのための分類器、二次タスクのための自己教師付きモジュール。
![]()
<スパン 12. その他
<スパン -------- 知識の蒸留は、中間層間の関係を考慮した定量化と組み合わせて使うことができる Feature Maps 参照することができます。
定量的知識蒸留の組み合わせ(量子化ミミック)_AI Flash - CSDN Blog
-------- 知識蒸留とHint Learningの組み合わせによるFaster-RCNNの効率的な学習法 でご利用いただけます。
ターゲット検知のための知識抽出_AI Flash-CSDNブログ_ターゲット検知のための知識抽出
-------- ネットワークアーキテクチャ検索 (NAS) は、検索結果を向上させるために蒸留操作を採用することも可能です。 の(クリームNASのためのモデル間蒸留)を参照。
自己蒸留型ワンショットNAS--Cream of the Crop_AI Flash-CSDNブログ
-------- Transformerのモデル圧縮における知識蒸留、主にSelf-attention Knowledge Distillationを使用。 でご利用いただけます。
Transformerのエンドサイドモデル圧縮 - Mobile Transformer_AI Flash-CSDNブログ
<スパン 圧縮の側面についてのより詳細な議論は、--------モデルの ご参照ください。
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
ハートビート・エフェクトのためのHTML+CSS
-
HTML ホテル フォームによるフィルタリング
-
HTML+cssのボックスモデル例(円、半円など)「border-radius」使いやすい
-
HTMLテーブルのテーブル分割とマージ(colspan, rowspan)
-
ランダム・ネームドロッパーを実装するためのhtmlサンプルコード
-
Html階層型ボックスシャドウ効果サンプルコード
-
QQの一時的なダイアログボックスをポップアップし、友人を追加せずにオンラインで話す効果を達成する方法
-
sublime / vscodeショートカットHTMLコード生成の実装
-
HTMLページを縮小した後にスクロールバーを表示するサンプルコード
-
html のリストボックス、テキストフィールド、ファイルフィールドのコード例