[解決済み] KerasのLSTMを理解する
質問
私は、LSTMについての私の理解と、ここで指摘されていることを調和させようとしています。 Christopher Olahの投稿 をKerasで実装しました。を追っています。 ジェイソン・ブラウンリー氏によるブログ のチュートリアルのためです。私が主に混乱しているのは、次のとおりです。
-
データ系列のリシェイプを
[samples, time steps, features]とします。 - ステートフルLSTMの
上記の2つの質問について、以下に貼り付けたコードを参照しながら考えてみましょう。
# reshape into X=t and Y=t+1
look_back = 3
trainX, trainY = create_dataset(train, look_back)
testX, testY = create_dataset(test, look_back)
# reshape input to be [samples, time steps, features]
trainX = numpy.reshape(trainX, (trainX.shape[0], look_back, 1))
testX = numpy.reshape(testX, (testX.shape[0], look_back, 1))
########################
# The IMPORTANT BIT
##########################
# create and fit the LSTM network
batch_size = 1
model = Sequential()
model.add(LSTM(4, batch_input_shape=(batch_size, look_back, 1), stateful=True))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
for i in range(100):
model.fit(trainX, trainY, nb_epoch=1, batch_size=batch_size, verbose=2, shuffle=False)
model.reset_states()
注:create_datasetは,長さNのシーケンスを受け取り
N-look_back
の配列で、各要素は
look_back
長さのシーケンスです。
タイムステップとフィーチャーとは?
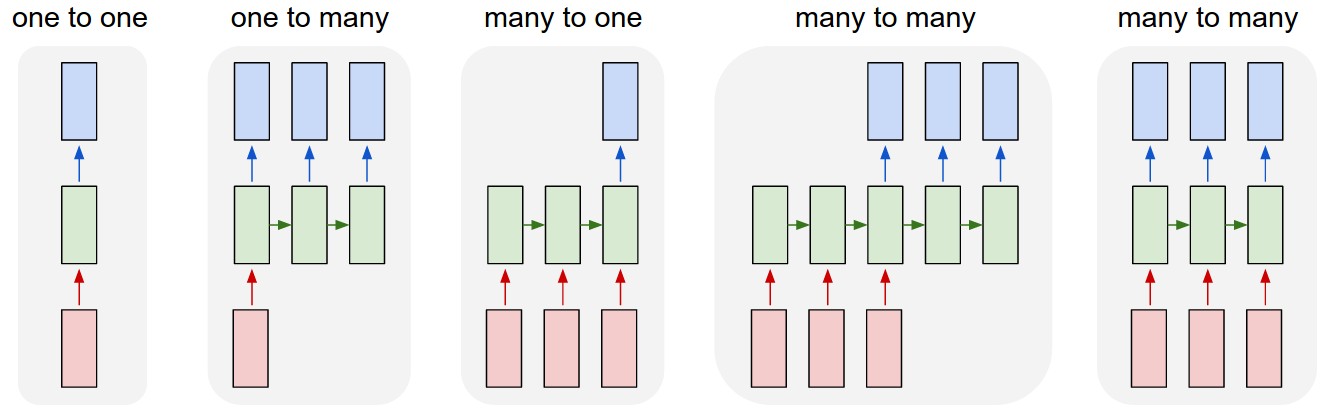
TrainXは3次元配列で、Time_stepsとFeatureはそれぞれ最後の2次元(このコードでは3および1)です。下の画像に関して、これは私たちが
many to one
の場合、ピンクのボックスの数は3でしょうか?それとも文字通り、チェーンの長さが3である(つまり、3つの緑のボックスだけを考慮する)ことを意味するのでしょうか?
多変量解析を行う場合、特徴量に関する議論は重要ですか?
ステートフルLSTM
ステートフルLSTMとは、バッチの実行の間にセルメモリの値を保存するということでしょうか?もしそうであれば
batch_size
が1つで、学習実行の間にメモリはリセットされるので、ステートフルと言ったのは何だったのでしょう。トレーニングデータがシャッフルされないことと関係があると思いますが、どうなんでしょう。
何かご意見はありますか? 画像参照 http://karpathy.github.io/2015/05/21/rnn-effectiveness/
1を編集します。
赤と緑のボックスが等しいという@vanのコメントについて、少し混乱しています。では、確認ですが、以下のAPIコールは展開された図に対応しているのでしょうか?特に2番目のダイアグラム(
batch_size
は任意に選択しました)。
<イグ
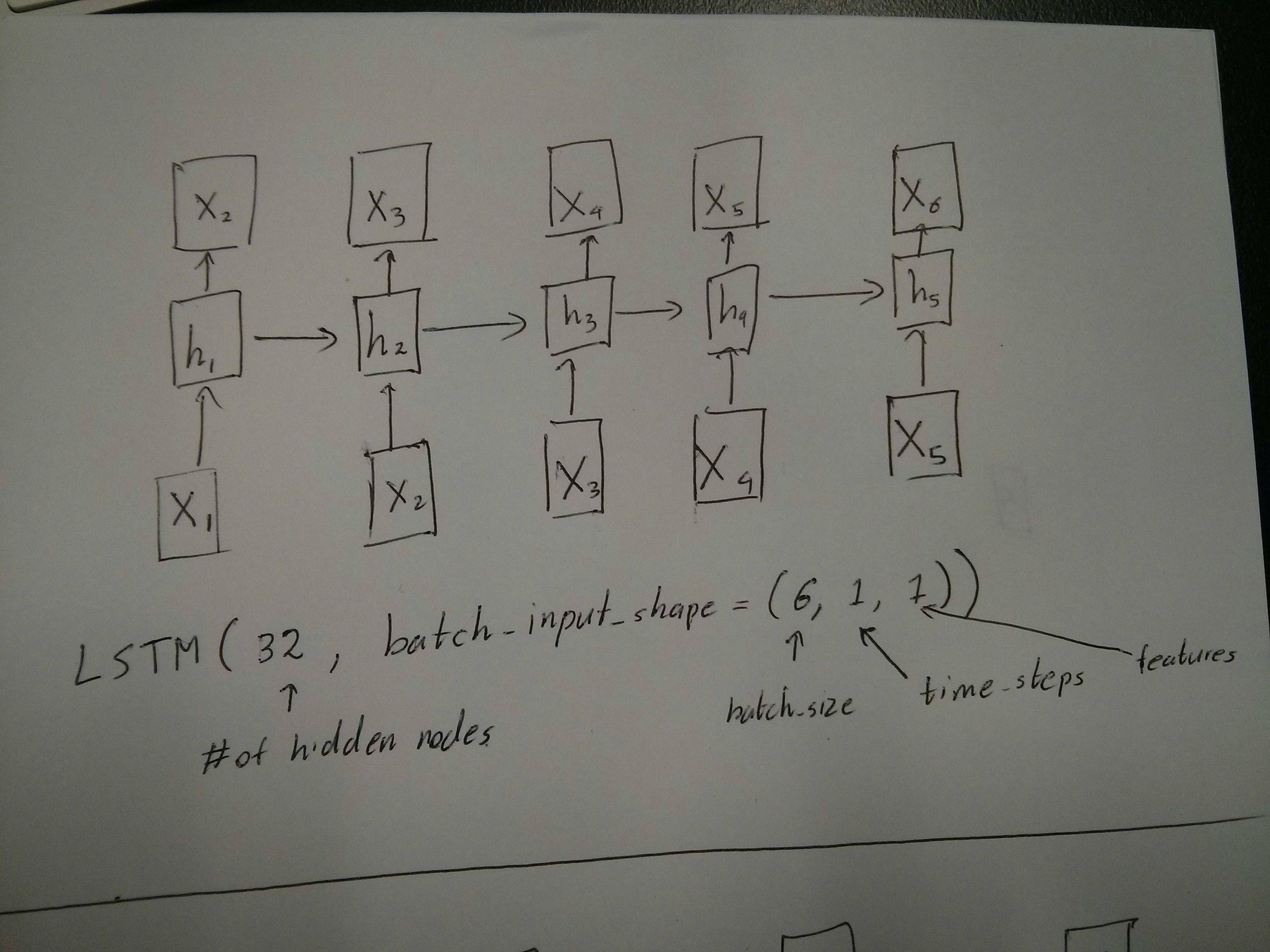
2を編集します。
Udacityのディープラーニング講座をやって、それでもtime_stepの引数に戸惑う人は、以下の議論を見てください。 https://discussions.udacity.com/t/rnn-lstm-use-implementation/163169
更新情報
それが判明したのは
model.add(TimeDistributed(Dense(vocab_len)))
は、私が探していたものでした。以下はその例です。
https://github.com/sachinruk/ShakespeareBot
Update2です。
LSTMに関する私の理解の大部分をここにまとめました。 https://www.youtube.com/watch?v=ywinX5wgdEU
解決方法は?
まず、素晴らしいチュートリアルを選びます( 1 , 2 )を開始します。
タイムステップの意味
:
Time-steps==3
X.shape(データの形状を記述する)でピンクのボックスが3つあることを意味します。Kerasでは各ステップで入力が必要なので、通常、緑のボックスの数は赤のボックスの数と同じになるはずです。構造をハックしない限り。
多対多と多対一の比較
: kerasでは
return_sequences
を初期化する際に、パラメータ
LSTM
または
GRU
または
SimpleRNN
. いつ
return_sequences
は
False
(デフォルト)であれば、それは
多対一
のようになります。その戻り形状は
(batch_size, hidden_unit_length)
これは最後の状態を表しています。このとき
return_sequences
は
True
であれば、それは
多対多
. その返送形状は
(batch_size, time_step, hidden_unit_length)
機能に関する議論が重要になるか
: Feature引数とは
赤い箱の大きさはどのくらいですか?
とか、各ステップの入力次元がどうなっているかとか。例えば8種類の市場情報から予測したい場合、データを生成する際に
feature==8
.
ステートフル
: を調べることができます。
ソースコード
. 状態を初期化するとき、もし
stateful==True
であれば、前回の学習時の状態が初期状態として使用され、そうでなければ新しい状態が生成されます。をオンにしていない。
stateful
はまだです。しかし、私はそのことに反対です
batch_size
が1であるときだけです。
stateful==True
.
現在、収集したデータでデータを生成しています。在庫情報が流れてくるイメージで、1日かけてシーケンシャルに収集するのではなく、入力データを生成したい。
オンライン
ネットワークで学習/予測しながら。もし、400の銘柄が同じネットワークを共有しているのであれば、以下のように設定する。
batch_size==400
.
関連
-
opencvとpillowを用いた顔認証システム(デモあり)
-
pythonサイクルタスクスケジューリングツール スケジュール詳解
-
python implement mysql add delete check change サンプルコード
-
Pythonの画像ファイル処理用ライブラリ「Pillow」(グラフィックの詳細)
-
FacebookオープンソースワンストップサービスpythonのタイミングツールKats詳細
-
[解決済み】RuntimeWarning: invalid value encountered in double_scalars で numpy の除算ができない。
-
[解決済み】socket.error: [Errno 48] アドレスはすでに使用中です。
-
[解決済み】 AttributeError("'str' object has no attribute 'read'")
-
[解決済み】NameError: 名前 'self' が定義されていません。
-
[解決済み] スライス表記を理解する
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
pythonを使ったオフィス自動化コード例
-
Python関数の高度な応用を解説
-
Pythonを使って簡単なzipファイルの解凍パスワードを手作業で解く
-
[解決済み】TypeError: unhashable type: 'numpy.ndarray'.
-
[解決済み】Python regex AttributeError: 'NoneType' オブジェクトに 'group' 属性がない。
-
[解決済み】終了コード -1073741515 (0xC0000135)でプロセス終了)
-
[解決済み] 'DataFrame' オブジェクトに 'sort' 属性がない
-
[解決済み】NameError: 名前 'self' が定義されていません。
-
[解決済み】Python - "ValueError: not enough values to unpack (expected 2, got 1)" の修正方法 [閉店].
-
[解決済み] Kerasの入力説明:input_shape, units, batch_size, dim, etc.