[解決済み] 複数のINSERTステートメントと複数のVALUESを持つ単一のINSERTの比較
質問
1000個のINSERT文を使用した場合のパフォーマンス比較を行っています。
INSERT INTO T_TESTS (TestId, FirstName, LastName, Age)
VALUES ('6f3f7257-a3d8-4a78-b2e1-c9b767cfe1c1', 'First 0', 'Last 0', 0)
INSERT INTO T_TESTS (TestId, FirstName, LastName, Age)
VALUES ('32023304-2e55-4768-8e52-1ba589b82c8b', 'First 1', 'Last 1', 1)
...
INSERT INTO T_TESTS (TestId, FirstName, LastName, Age)
VALUES ('f34d95a7-90b1-4558-be10-6ceacd53e4c4', 'First 999', 'Last 999', 999)
...1000の値を持つ単一のINSERT文を使用する場合と比較して。
INSERT INTO T_TESTS (TestId, FirstName, LastName, Age)
VALUES
('db72b358-e9b5-4101-8d11-7d7ea3a0ae7d', 'First 0', 'Last 0', 0),
('6a4874ab-b6a3-4aa4-8ed4-a167ab21dd3d', 'First 1', 'Last 1', 1),
...
('9d7f2a58-7e57-4ed4-ba54-5e9e335fb56c', 'First 999', 'Last 999', 999)
大きな驚きですが、結果は私が考えていたのとは逆でした。
- 1000 件の INSERT ステートメント。 290 msec.
- 1000 VALUESのINSERT文が1つ。 2800 msec.
このテストは、測定に SQL Server Profiler を使用し、MSSQL Management Studio で直接実行されます (さらに、SqlClient を使用して C# コードから実行しても同様の結果が得られ、すべての DAL 層のラウンドトリップを考えるとさらに驚かされます)。
これは妥当なことなのでしょうか、あるいは何らかの形で説明できるのでしょうか。なぜ、より高速なはずの方法が 10 倍 (!) の結果になるのでしょうか。 より悪い パフォーマンスになってしまうのでしょうか?
ありがとうございます。
EDIT: 両方の実行計画を添付します。
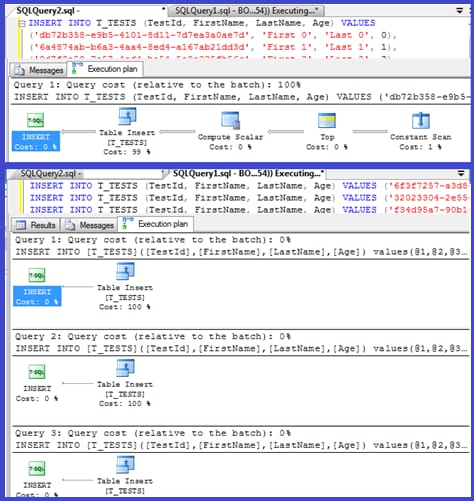
どのように解決するのですか?
<ブロッククオート追加です。 SQL Server 2012 は、この領域でいくつかのパフォーマンスの向上を示していますが、以下に示す特定の問題には対処していないようです。これは は はどうやら修正されたようで 次のメジャーバージョンで 後 SQL Server 2012 になります。
あなたのプランでは、単一の挿入はパラメータ化されたプロシージャ(おそらく自動パラメータ化)を使用しているので、これらのための解析/コンパイル時間は最小限であるべきです。
しかし、もう少し調べてみようと思い、ループをセットアップしました (
スクリプト
) を設定し
VALUES
節を調整し、コンパイル時間を記録してみました。
次に、節ごとの平均コンパイル時間を得るために、コンパイル時間を行数で割りました。その結果は以下のとおりです。
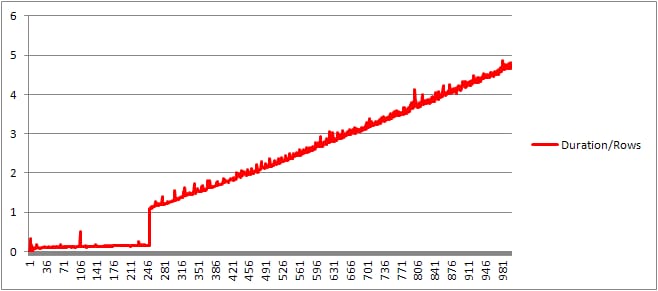
250まで
VALUES
節が存在するまでは、コンパイル時間 / 節の数はわずかに増加する傾向がありますが、それほど劇的ではありません。
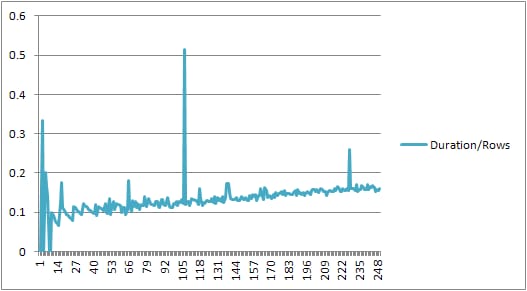
しかし、その後に急変がある。
その部分のデータは以下の通りです。
+------+----------------+-------------+---------------+---------------+
| Rows | CachedPlanSize | CompileTime | CompileMemory | Duration/Rows |
+------+----------------+-------------+---------------+---------------+
| 245 | 528 | 41 | 2400 | 0.167346939 |
| 246 | 528 | 40 | 2416 | 0.162601626 |
| 247 | 528 | 38 | 2416 | 0.153846154 |
| 248 | 528 | 39 | 2432 | 0.157258065 |
| 249 | 528 | 39 | 2432 | 0.156626506 |
| 250 | 528 | 40 | 2448 | 0.16 |
| 251 | 400 | 273 | 3488 | 1.087649402 |
| 252 | 400 | 274 | 3496 | 1.087301587 |
| 253 | 400 | 282 | 3520 | 1.114624506 |
| 254 | 408 | 279 | 3544 | 1.098425197 |
| 255 | 408 | 290 | 3552 | 1.137254902 |
+------+----------------+-------------+---------------+---------------+
キャッシュされたプランのサイズは直線的に増加していましたが、突然減少し、CompileTimeは7倍、CompileMemoryは急上昇しました。これは、計画が自動パラメトリックなもの(1,000個のパラメータを持つ)からパラメトリックでないものになる間のカットオフ点です。その後、(与えられた時間内に処理される値句の数に関して)線形的に効率が悪くなるようです。
なぜそうなるのかはよくわかりません。おそらく、特定のリテラル値に対してプランをコンパイルしているとき、線形にスケールしない何らかのアクティビティ (ソートなど) を実行しなければならないのでしょう。
重複行のみで構成されるクエリを試した場合、キャッシュされたクエリプランのサイズには影響しないように思えますし、定数テーブルの出力順序にも影響しません(そして、ヒープに挿入しているため、ソートに費やした時間は、たとえそれがあったとしても、いずれにせよ無意味なものになるでしょう)。
さらに、もしクラスタ化インデックスがテーブルに追加された場合、計画はまだ明示的なソートステップを表示しますので、実行時のソートを避けるためにコンパイル時にソートしているようには見えません。

デバッガでこれを見ようとしましたが、私の SQL Server 2008 のバージョンではパブリックシンボルが利用できないようです。
UNION ALL
の構造を見てみる必要がありました。
典型的なスタックトレースは以下のとおりです。
sqlservr.exe!FastDBCSToUnicode() + 0xac bytes
sqlservr.exe!nls_sqlhilo() + 0x35 bytes
sqlservr.exe!CXVariant::CmpCompareStr() + 0x2b bytes
sqlservr.exe!CXVariantPerformCompare<167,167>::Compare() + 0x18 bytes
sqlservr.exe!CXVariant::CmpCompare() + 0x11f67d bytes
sqlservr.exe!CConstraintItvl::PcnstrItvlUnion() + 0xe2 bytes
sqlservr.exe!CConstraintProp::PcnstrUnion() + 0x35e bytes
sqlservr.exe!CLogOp_BaseSetOp::PcnstrDerive() + 0x11a bytes
sqlservr.exe!CLogOpArg::PcnstrDeriveHandler() + 0x18f bytes
sqlservr.exe!CLogOpArg::DeriveGroupProperties() + 0xa9 bytes
sqlservr.exe!COpArg::DeriveNormalizedGroupProperties() + 0x40 bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x18a bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x146 bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x146 bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x146 bytes
sqlservr.exe!CQuery::PqoBuild() + 0x3cb bytes
sqlservr.exe!CStmtQuery::InitQuery() + 0x167 bytes
sqlservr.exe!CStmtDML::InitNormal() + 0xf0 bytes
sqlservr.exe!CStmtDML::Init() + 0x1b bytes
sqlservr.exe!CCompPlan::FCompileStep() + 0x176 bytes
sqlservr.exe!CSQLSource::FCompile() + 0x741 bytes
sqlservr.exe!CSQLSource::FCompWrapper() + 0x922be bytes
sqlservr.exe!CSQLSource::Transform() + 0x120431 bytes
sqlservr.exe!CSQLSource::Compile() + 0x2ff bytes
スタックトレースの名前からすると、文字列の比較に多くの時間を費やしているように見えます。
この KB の記事
は
DeriveNormalizedGroupProperties
と呼ばれていたものと関連しています。
正規化
段階と呼ばれていました。
この段階はバインディングまたはアルジブライジングと呼ばれ、前の解析段階から出力された式解析ツリーを受け取り、最適化(この場合は些細な計画の最適化)に進むためにアルジブライズされた式ツリー(クエリプロセッサーツリー)を出力します。 参照 .
もう一つ実験してみました( スクリプト ) で、3つの異なるケースを見ながら元のテストを再実行しました。
- 長さ 10 文字の名前と姓の文字列で、重複がないこと。
- 名前と姓の文字列。長さは50文字で、重複はありません。
- 長さ10文字の名前と姓の文字列、重複はありません。
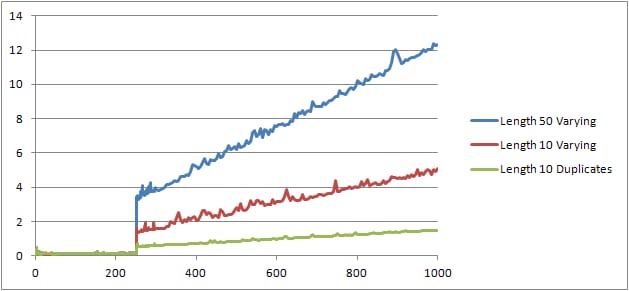
文字列が長くなればなるほど状況が悪くなり、逆に重複が多くなればなるほど状況が良くなることがはっきりとわかります。前述したように、重複はキャッシュされた計画のサイズに影響を与えないので、代数化された式木を構築する際に重複を識別するプロセスがあるはずだと推測されます。
編集
この情報が活用されている場所として で、@Lieven がここで示しています。
SELECT *
FROM (VALUES ('Lieven1', 1),
('Lieven2', 2),
('Lieven3', 3))Test (name, ID)
ORDER BY name, 1/ (ID - ID)
なぜなら、コンパイル時に
Name
カラムに重複がないと判断できるため、二次カラムである
1/ (ID - ID)
式による順序付けをスキップします (プランのソートは、1つの
ORDER BY
列を持ちます)、ゼロによる除算エラーは発生しません。重複がテーブルに追加された場合、ソート演算子は2つのorder by列を表示し、期待されるエラーが発生します。
関連
-
[解決済み] SQLiteのINSERT/per-secondのパフォーマンスを向上させる
-
[解決済み] SQLテーブルで重複する値を検索する
-
[解決済み] SQL Server で複数行のテキストを 1 つのテキスト文字列に連結する方法
-
[解決済み] SQL Server の DateTime データ型から日付だけを返す方法
-
[解決済み] ...値に挿入する ( SELECT ... FROM ... )
-
[解決済み] SQL ServerでJOINを使用してUPDATE文を実行するにはどうすればよいですか?
-
[解決済み] 複数の列でgroup byを使用する
-
[解決済み] VARCHARとCHARの違いは何ですか?
-
[解決済み】SQL Serverで既存のテーブルにデフォルト値を持つカラムを追加する
-
[解決済み] SQL ServerでINNER JOINを使用して削除するにはどうすればよいですか?
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
解決策:java.sql.SQLException: ユーザー ''@'localhost'' (パスワード: YES を使用) のアクセスが拒否されました。
-
plsql-stored-procedure ORA-06550 エラー処理
-
MHAクラスタエラーサマリーの構築
-
[解決済み] SQL Serverで実行中の合計を計算する
-
[解決済み] ATTACHで開いたSQLiteデータベースファイルのテーブルを一覧表示するにはどうすればよいですか?
-
[解決済み] 最初の行への結合方法
-
[解決済み] mysqldumpで特定のテーブルをスキップする
-
[解決済み] SQLiteデータベースで、一度に複数行を挿入することは可能ですか?
-
[解決済み] VARCHARとCHARの違いは何ですか?
-
[解決済み】複数のシングルINSERTと1つの複数行のINSERTはどちらが速いですか?