[解決済み] タグシステムの導入方法
質問
SOで使われているようなタグシステムを実装するのに一番良い方法は何だろうと考えていました。私はこれを考えていましたが、良いスケーラブルな解決策を思いつきません。
私は基本的な3テーブルのソリューションを考えていました。
tags
テーブルと
articles
テーブルと
tag_to_articles
テーブルを使用します。
これはこの問題に対する最良の解決策でしょうか、それとも代替案があるのでしょうか?この方法を使用すると、テーブルが非常に大きくなり、検索にはあまり効率的ではないと思います。一方、クエリが高速に実行されることはそれほど重要ではありません。
どのように解決するのですか?
このブログの記事は興味深いものだと思います。 タグ データベーススキーマ
<ブロッククオート問題点: データベーススキーマで ブックマーク (またはブログの記事など) に好きなだけタグを付けることができます。 その後、クエリを実行して、ブックマークをタグの結合または交差に制約したいとします。 タグの結合または交差を制約するクエリを実行したいとします。また、あるタグを検索結果から除外(例えばマイナス)したいとします。 検索結果からいくつかのタグを除外したい。
"MySQLicious" ソリューション
このソリューションでは、スキーマはただ1つのテーブルを持ち、それは非正規化されています。MySQLiciousがdel.icio.usのデータをこの構造のテーブルにインポートするため、このタイプは「MySQLiciousソリューション」と呼ばれています。


交差点(AND) search+webservice+semweb "のクエリ。
SELECT *
FROM `delicious`
WHERE tags LIKE "%search%"
AND tags LIKE "%webservice%"
AND tags LIKE "%semweb%"
ユニオン(OR) search|webservice|semweb "のクエリ。
SELECT *
FROM `delicious`
WHERE tags LIKE "%search%"
OR tags LIKE "%webservice%"
OR tags LIKE "%semweb%"
マイナス search+webservice-semweb "のクエリ。
SELECT *
FROM `delicious`
WHERE tags LIKE "%search%"
AND tags LIKE "%webservice%"
AND tags NOT LIKE "%semweb%"
「スカットル」ソリューション
スカットル は、2つのテーブルでデータを整理している。scCategories "テーブルは "tag "テーブルであり、"bookmark "テーブルへの外部キーを持っています。
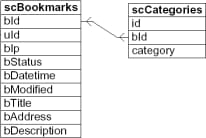
交差点(AND) bookmark+webservice+semweb "のクエリ。
SELECT b.*
FROM scBookmarks b, scCategories c
WHERE c.bId = b.bId
AND (c.category IN ('bookmark', 'webservice', 'semweb'))
GROUP BY b.bId
HAVING COUNT( b.bId )=3
まず、すべてのブックマークとタグの組み合わせを検索し、タグが「bookmark」、「webservice」、「semweb」の場合(c.category IN ('bookmark', 'webservice', 'semweb') )、次に、検索した3つのタグすべてを持つブックマークだけが考慮されます(HAVING COUNT(b.bId)=3).
ユニオン(OR) bookmark|webservice|semweb "のクエリ。 HAVING句を省くだけでユニオンになります。
SELECT b.*
FROM scBookmarks b, scCategories c
WHERE c.bId = b.bId
AND (c.category IN ('bookmark', 'webservice', 'semweb'))
GROUP BY b.bId
マイナス(除外) bookmark+webservice-semweb "のクエリ、つまり、bookmark AND webservice AND NOT semwebのクエリ。
SELECT b. *
FROM scBookmarks b, scCategories c
WHERE b.bId = c.bId
AND (c.category IN ('bookmark', 'webservice'))
AND b.bId NOT
IN (SELECT b.bId FROM scBookmarks b, scCategories c WHERE b.bId = c.bId AND c.category = 'semweb')
GROUP BY b.bId
HAVING COUNT( b.bId ) =2
HAVING COUNTを省くと、"bookmark|webservice-semweb "のクエリになります。
「トキシソリューション
Toxi という3つのテーブル構造を思いつきました。タグマップというテーブルで、ブックマークとタグはn対mの関係になっています。各タグは、異なるブックマークと一緒に使うことができ、その逆も可能です。このDBスキーマは、wordpressでも使われています。 クエリーは "scuttle "ソリューションと全く同じです。
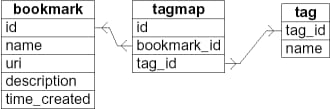
交差点(AND) "bookmark+webservice+semweb "のクエリ
SELECT b.*
FROM tagmap bt, bookmark b, tag t
WHERE bt.tag_id = t.tag_id
AND (t.name IN ('bookmark', 'webservice', 'semweb'))
AND b.id = bt.bookmark_id
GROUP BY b.id
HAVING COUNT( b.id )=3
ユニオン(OR) bookmark|webservice|semweb "のクエリ。
SELECT b.*
FROM tagmap bt, bookmark b, tag t
WHERE bt.tag_id = t.tag_id
AND (t.name IN ('bookmark', 'webservice', 'semweb'))
AND b.id = bt.bookmark_id
GROUP BY b.id
マイナス(除外) bookmark+webservice-semweb "のクエリ、つまり、bookmark AND webservice AND NOT semwebのクエリ。
SELECT b. *
FROM bookmark b, tagmap bt, tag t
WHERE b.id = bt.bookmark_id
AND bt.tag_id = t.tag_id
AND (t.name IN ('Programming', 'Algorithms'))
AND b.id NOT IN (SELECT b.id FROM bookmark b, tagmap bt, tag t WHERE b.id = bt.bookmark_id AND bt.tag_id = t.tag_id AND t.name = 'Python')
GROUP BY b.id
HAVING COUNT( b.id ) =2
HAVING COUNTを省くと、"bookmark|webservice-semweb "のクエリになります。
関連
-
[解決済み] NPとco-NPの違いは何ですか?
-
[解決済み] k-meansの時間計算量はどの程度ですか?
-
[解決済み] JavaScript で配列に値が含まれているかどうかを確認するにはどうすればよいですか?
-
[解決済み] 山積みされた靴下を効率よく組み合わせるには?
-
[解決済み] Androidのシステムバージョンを確認するにはどうすればよいですか?
-
[解決済み] フラットテーブルをツリーにパースする最も効率的/エレガントな方法は何ですか?
-
[解決済み】アルゴリズムの時間複雑性を求めるには?
-
[解決済み】固定長 6 int 配列の最速ソート
-
[解決済み] キャッシュの無効化 - 一般的な解決策はありますか?
-
[解決済み] luceneはどのように文書をインデックスするのですか?
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン