[解決済み] カラム内のカンマ区切り文字列を別の行に分割する
質問
このようなデータフレームがあります。
data.frame(director = c("Aaron Blaise,Bob Walker", "Akira Kurosawa",
"Alan J. Pakula", "Alan Parker", "Alejandro Amenabar", "Alejandro Gonzalez Inarritu",
"Alejandro Gonzalez Inarritu,Benicio Del Toro", "Alejandro González Iñárritu",
"Alex Proyas", "Alexander Hall", "Alfonso Cuaron", "Alfred Hitchcock",
"Anatole Litvak", "Andrew Adamson,Marilyn Fox", "Andrew Dominik",
"Andrew Stanton", "Andrew Stanton,Lee Unkrich", "Angelina Jolie,John Stevenson",
"Anne Fontaine", "Anthony Harvey"), AB = c('A', 'B', 'A', 'A', 'B', 'B', 'B', 'A', 'B', 'A', 'B', 'A', 'A', 'B', 'B', 'B', 'B', 'B', 'B', 'A'))
ご覧のように
director
カラムのいくつかのエントリは、カンマで区切られた複数の名前です。これらのエントリを、他の列の値を維持したまま別の行に分割したいと思います。例として、上記のデータフレームの最初の行を 2 つの行に分割し、それぞれ単一の名前で
director
カラムにそれぞれ単一の名前を、'A' は
AB
カラムに
どのように解決するのですか?
この古い質問は頻繁にダブりのターゲットとして使用されています (タグは
r-faq
). 今日の時点で、この質問は3回回答され、6つの異なるアプローチを提供していますが
はベンチマークを欠いています。
どのアプローチが最速なのかのガイダンスとして
1
.
ベンチマークされたソリューションは以下の通りです。
- Matthew Lundbergの基本的なRのアプローチ に従って修正されていますが Rich Scrivenのコメント ,
-
Jaap の
二
data.tableメソッドと、2つのdplyr/tidyrをアプローチします。 -
アナンダの
splitstackshape解決策 , -
と、Jaap の 2 つの追加のバリエーションである
data.tableメソッドを追加しました。
全体として8つの異なるメソッドが、6つの異なるサイズのデータフレームを使用してベンチマークされました。
microbenchmark
パッケージを使ってベンチマークを行いました(以下のコードを参照)。
OPによって与えられたサンプルデータは20行で構成されているだけです。より大きなデータフレームを作成するために、この20行を1、10、100、1000、10000、100000回繰り返すだけで、最大200万行の問題サイズを得ることができます。
ベンチマーク結果
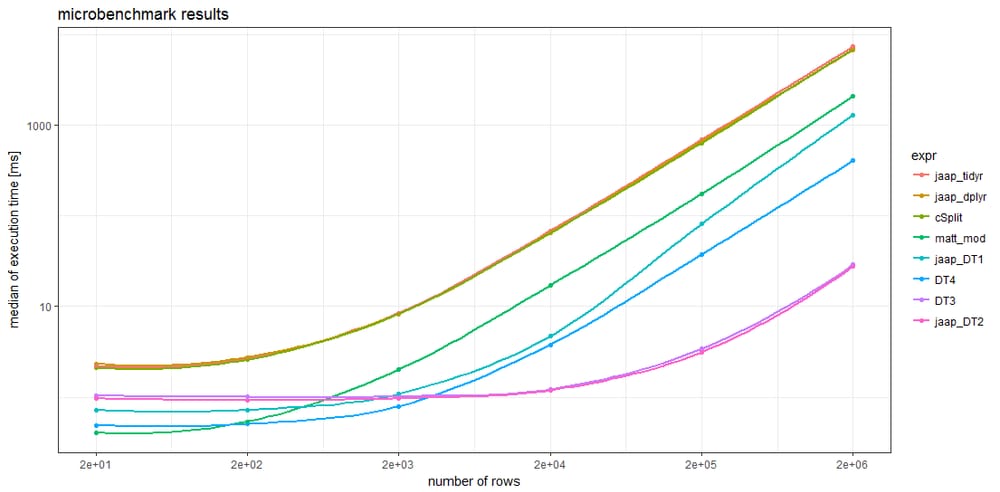
ベンチマークの結果、十分に大きなデータフレームに対して、すべての
data.table
メソッドは他のどのメソッドよりも高速であることがわかります。約5000行以上のデータフレームに対しては、Jaapの
data.table
メソッド 2 とバリアント
DT3
は最速で、最も遅いメソッドより何倍も速いです。
驚くべきことに、2つの
tidyverse
メソッドと
splistackshape
のソリューションは非常によく似ているため、グラフの曲線を区別するのは困難です。これらは、すべてのデータ フレームのサイズにわたって、ベンチマークされたメソッドの中で最も遅いです。
より小さいデータフレームでは、Matt の基本的な R ソリューションと
data.table
メソッド4は、他のメソッドよりもオーバーヘッドが少ないようです。
コード
director <-
c("Aaron Blaise,Bob Walker", "Akira Kurosawa", "Alan J. Pakula",
"Alan Parker", "Alejandro Amenabar", "Alejandro Gonzalez Inarritu",
"Alejandro Gonzalez Inarritu,Benicio Del Toro", "Alejandro González Iñárritu",
"Alex Proyas", "Alexander Hall", "Alfonso Cuaron", "Alfred Hitchcock",
"Anatole Litvak", "Andrew Adamson,Marilyn Fox", "Andrew Dominik",
"Andrew Stanton", "Andrew Stanton,Lee Unkrich", "Angelina Jolie,John Stevenson",
"Anne Fontaine", "Anthony Harvey")
AB <- c("A", "B", "A", "A", "B", "B", "B", "A", "B", "A", "B", "A",
"A", "B", "B", "B", "B", "B", "B", "A")
library(data.table)
library(magrittr)
問題サイズのベンチマーク実行のための関数を定義する
n
run_mb <- function(n) {
# compute number of benchmark runs depending on problem size `n`
mb_times <- scales::squish(10000L / n , c(3L, 100L))
cat(n, " ", mb_times, "\n")
# create data
DF <- data.frame(director = rep(director, n), AB = rep(AB, n))
DT <- as.data.table(DF)
# start benchmarks
microbenchmark::microbenchmark(
matt_mod = {
s <- strsplit(as.character(DF$director), ',')
data.frame(director=unlist(s), AB=rep(DF$AB, lengths(s)))},
jaap_DT1 = {
DT[, lapply(.SD, function(x) unlist(tstrsplit(x, ",", fixed=TRUE))), by = AB
][!is.na(director)]},
jaap_DT2 = {
DT[, strsplit(as.character(director), ",", fixed=TRUE),
by = .(AB, director)][,.(director = V1, AB)]},
jaap_dplyr = {
DF %>%
dplyr::mutate(director = strsplit(as.character(director), ",")) %>%
tidyr::unnest(director)},
jaap_tidyr = {
tidyr::separate_rows(DF, director, sep = ",")},
cSplit = {
splitstackshape::cSplit(DF, "director", ",", direction = "long")},
DT3 = {
DT[, strsplit(as.character(director), ",", fixed=TRUE),
by = .(AB, director)][, director := NULL][
, setnames(.SD, "V1", "director")]},
DT4 = {
DT[, .(director = unlist(strsplit(as.character(director), ",", fixed = TRUE))),
by = .(AB)]},
times = mb_times
)
}
異なる問題サイズでのベンチマーク実行
# define vector of problem sizes
n_rep <- 10L^(0:5)
# run benchmark for different problem sizes
mb <- lapply(n_rep, run_mb)
プロット用のデータを準備する
mbl <- rbindlist(mb, idcol = "N")
mbl[, n_row := NROW(director) * n_rep[N]]
mba <- mbl[, .(median_time = median(time), N = .N), by = .(n_row, expr)]
mba[, expr := forcats::fct_reorder(expr, -median_time)]
グラフの作成
library(ggplot2)
ggplot(mba, aes(n_row, median_time*1e-6, group = expr, colour = expr)) +
geom_point() + geom_smooth(se = FALSE) +
scale_x_log10(breaks = NROW(director) * n_rep) + scale_y_log10() +
xlab("number of rows") + ylab("median of execution time [ms]") +
ggtitle("microbenchmark results") + theme_bw()
セッション情報 & パッケージのバージョン (抜粋)
devtools::session_info()
#Session info
# version R version 3.3.2 (2016-10-31)
# system x86_64, mingw32
#Packages
# data.table * 1.10.4 2017-02-01 CRAN (R 3.3.2)
# dplyr 0.5.0 2016-06-24 CRAN (R 3.3.1)
# forcats 0.2.0 2017-01-23 CRAN (R 3.3.2)
# ggplot2 * 2.2.1 2016-12-30 CRAN (R 3.3.2)
# magrittr * 1.5 2014-11-22 CRAN (R 3.3.0)
# microbenchmark 1.4-2.1 2015-11-25 CRAN (R 3.3.3)
# scales 0.4.1 2016-11-09 CRAN (R 3.3.2)
# splitstackshape 1.4.2 2014-10-23 CRAN (R 3.3.3)
# tidyr 0.6.1 2017-01-10 CRAN (R 3.3.2)
1
私の好奇心を刺激したのは
というコメントで興味をそそられました。
素晴らしい! 桁外れに速い!
を
tidyverse
の答えになります。
質問
の回答で、この質問と重複しているとして閉じられました。
関連
-
[解決済み] リストを均等な大きさの塊に分割するには?
-
[解決済み] IList<string> または IEnumerable<string> からカンマ区切りリストを作成する。
-
[解決済み] カンマ区切りの文字列を配列に変換するにはどうすればよいですか?
-
[解決済み] Bashで文字列を配列に分割する方法は?
-
[解決済み] 配列をチャンクに分割する
-
[解決済み] SwiftでStringを配列に分割する?
-
[解決済み] 文字列を複数の単語境界のデリミタで単語に分割する
-
[解決済み] 文字列のリストからカンマで区切られた文字列を作るには?
-
[解決済み] カンマ区切りの文字列をリストに変換するには?
-
[解決済み】データフレームの文字列カラムを複数カラムに分割する
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
R - よくあるエラーとその原因 - 注意事項
-
[解決済み] Rでcは何をするのですか?重複] [重複
-
[解決済み] データフレームを結合(マージ)する方法(内側、外側、左側、右側)
-
[解決済み] ggplot2 の軸ラベルを回転させ、間隔を空ける
-
[解決済み] 空のdata.frameを作成する
-
[解決済み] データフレームのリストを行単位で1つのデータフレームに結合する
-
[解決済み] data.frameの1つの列の名前を変更する方法は?
-
[解決済み] R および RStudio のコンソールをクリアする関数
-
[解決済み] Rでオブジェクト(変数)が定義されているかどうかを確認するには?
-
[解決済み] 列の区切り文字列を分割し、新しい行として挿入する【重複