[解決済み】初めてのデータベース設計:私は過剰なエンジニアリングをしているのでしょうか?[クローズド]
質問
背景
私はCS1年生で、父が経営する中小企業でパートタイムで働いています。実世界でのアプリケーション開発の経験はありません。Pythonでスクリプトを書いたり、C言語のコースワークをしたことはありますが、このようなものはありません。
私の父は小さな研修事業を行っており、現在、すべての授業は外部のWebアプリケーションを介してスケジュール、記録、フォローアップされています。エクスポート/"レポート"機能がありますが、それは非常に一般的なもので、私たちは特定のレポートを必要としています。私たちは、クエリを実行するために実際のデータベースにアクセスすることができません。カスタムレポートシステムを構築するよう依頼されています。
私のアイデアは、一般的なCSVエクスポートを作成し、(おそらくPythonで)毎晩オフィスでホストされているMySQLデータベースにインポートし、そこから必要な特定のクエリを実行できるようにすることです。私はデータベースの経験がありませんが、非常に基本的なことは理解しています。データベースの作成と通常のフォームについて少し読んだことがあります。
近々、海外のクライアントが来るかもしれないので、その時にデータベースが爆発しないようにしたいです。また、現在、いくつかの大企業をクライアントとして持っており、それぞれ異なる部門を持っています(例:ACME親会社、ACMEヘルスケア部門、ACMEボディケア部門など)。
私が考えたスキーマは以下の通りです。
-
クライアントから見て
- クライアントがメインテーブル
-
顧客は所属する部門にリンクされている
- 部署が全国に散らばっていることがある。人事部はロンドン、マーケティング部はスウォンジー、など。
- 部門は会社の部門と連動している
- 部門は親会社にリンクしています
-
クラスから見た場合。
-
Sessionsはメインテーブル
- 各セッションに教師がリンクされています
- 各セッションにステータスIDが付与されます。例:0 - 終了、1 - キャンセル
- セッションは、任意の大きさのパックにグループ化されます。
- 各パックは、クライアントに割り当てられる
-
Sessionsはメインテーブル
スキーマを紙に書いて、第3形式に正規化するように設計しました。そして、それを MySQL Workbench に接続すると、すべてきれいに仕上げてくれました。
(
フルサイズの画像はこちら
)
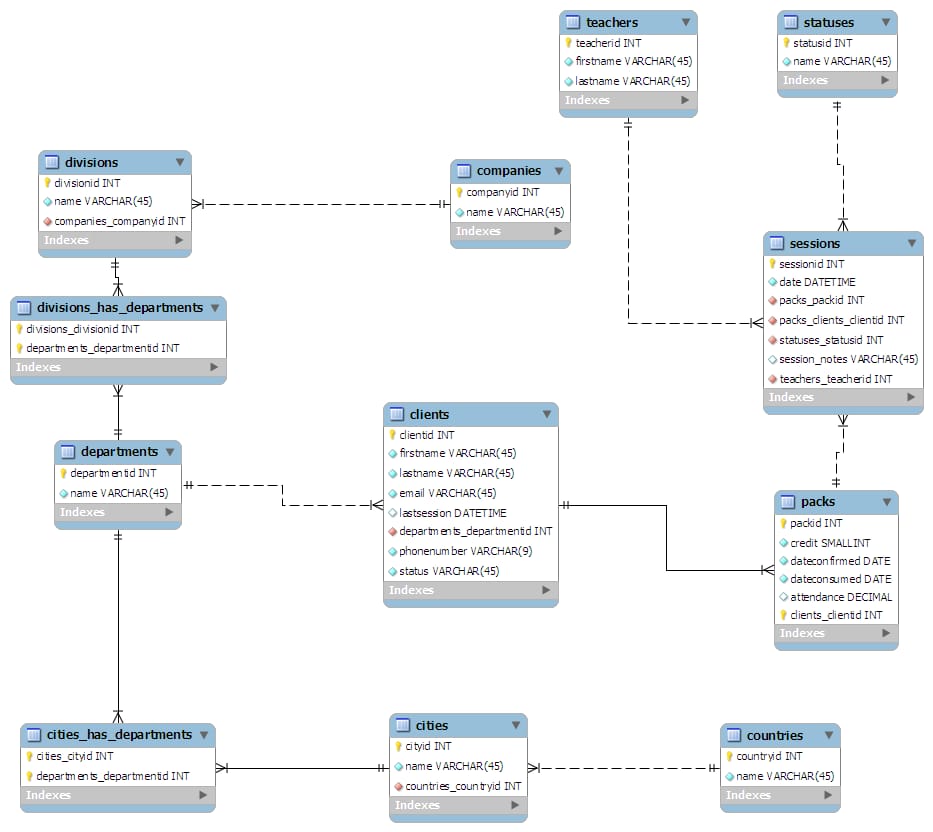
<サブ
(出典
maian.org
)
実行するクエリーの例
- クレジットの残っている顧客のうち、非アクティブな顧客(今後クラスの予定がない顧客)はどれか
- クライアント/部署/部門ごとの出席率はどうか(各セッションのステータスIDで測定しています)
- ある講師が1ヶ月に行った授業の数
- 出席率の低いクライアントにフラグを付ける
- 人事部向けに、所属する人の出勤率をカスタムレポート化
質問(複数可)
- これはオーバーエンジニアリングでしょうか、それとも正しい方向でしょうか?
- ほとんどのクエリで複数のテーブルを結合する必要があるため、パフォーマンスが大きく低下するのではないでしょうか?
- 一般的なクエリになると思われるので、クライアントに「lastsession」カラムを追加しました。これは良いアイデアでしょうか、それともデータベースを厳密に正規化した方が良いのでしょうか?
お忙しい中、ありがとうございました。
解決方法は?
ご質問に対する回答をいくつかご紹介します。
1) このような問題に初めて取り組む人にとっては、かなり的を射ていると思います。 この質問に対する他の人からの指摘は、これまでのところ、ほぼ網羅されていると思います。よくやった
2 & 3) あなたが受けるパフォーマンスのヒットは、あなたの特定のクエリ/プロシージャと、より重要なレコードの量に対して適切なインデックスを持ち、最適化することに大きく依存します。 メインテーブルのレコード数が100万を超えない限り、十分なメインストリーム設計の軌道に乗っているようなので、妥当なハードウェアであればパフォーマンスは問題にならないでしょう。
とはいえ、これは質問3に関連することですが、あなたのスタート時点では、パフォーマンスや正規化のオーソドックスさに対する過度の心配をする必要はないでしょう。 これは、あなたが構築しているレポートサーバーであって、トランザクションベースのアプリケーションバックエンドではありませんし、パフォーマンスや正規化の重要性に関しても、はるかに異なるプロファイルを持っているでしょう。 ライブサインアップとスケジューリングアプリケーションを支えるデータベースは、データを返すのに数秒かかるようなクエリに注意する必要があります。 レポートサーバーの機能は、複雑で長いクエリに対してより寛容であるだけでなく、パフォーマンスを向上させるための戦略も大きく異なっています。
例えば、トランザクションベースのアプリケーション環境では、ストアドプロシージャやテーブル構造を徹底的にリファクタリングしたり、よくリクエストされる少量のデータに対してキャッシュ戦略を開発することが、パフォーマンス向上の選択肢に含まれるかもしれません。 レポート環境では、このようなことはもちろん可能ですが、スナップショットのメカニズムを導入することで、パフォーマンスにさらに大きな影響を与えることができます。スケジュールされたプロセスが実行され、事前に設定されたレポートが保存され、ユーザーはリクエストごとにデータベース層に負荷をかけることなくスナップショットデータにアクセスすることができます。
以上、長文になりましたが、作成するデータベースの役割によって、採用する設計方針やトリックが異なる可能性があることを説明しました。 ご参考になれば幸いです。
関連
-
[解決済み】MySQLを使用してランダムでユニークな8文字の文字列を生成する方法
-
[解決済み] エラー 1115 (42000)。不明な文字セットです。'utf8mb4'
-
[解決済み] MySQL エラー 1093 - FROM 句で更新のターゲット テーブルを指定できません。
-
[解決済み] MySQLで日付のみのパラメータを使用してタイムスタンプの日付を比較する方法は?
-
[解決済み] エラー 1044 (42000)。データベース 'db' へのユーザー ''@'localhost'' のアクセスが拒否されました。
-
[解決済み] DEFAULT NULLとCHECKBOX NULL mysqlの違いは何ですか?
-
[解決済み] ATTACHで開いたSQLiteデータベースファイルのテーブルを一覧表示するにはどうすればよいですか?
-
[解決済み] MySQLデータベースの名前を素早く変更する(スキーマ名を変更する)方法は?
-
[解決済み] mysqlデータベースのサイズを取得する方法は?
-
[解決済み] データベースのカラムに区切りリストを格納することは、本当に悪いことなのか?
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み】autoカラムは1つしか存在できない
-
[解決済み】#1273 - 不明な照合順序:'utf8mb4_unicode_520_ci'
-
[解決済み】MAMPのmysqlサーバーが起動しない。mysqlのプロセスが起動していない
-
[解決済み] MySQLのforeachループ
-
[解決済み] mysql.pluginテーブルを開くことができません。mysql_upgradeを実行し、作成してください。
-
[解決済み] SQLZOO - select from world チュートリアル #13
-
[解決済み] MYSQLのTIMESTAMP比較
-
[解決済み] MongoDBのようにMySQLにもTTLがあるのでしょうか?
-
[解決済み] mysql サーバーがクラッシュした -mysqld got signal 6
-
[解決済み] テーブルがクラッシュしたと判定されたため、修復する必要があります。