ハッシュマップの実装原理と拡張機構を解説
内容
HashMapの基本
HashMap は AbstractMap クラスを継承し、Map、Cloneable、Serializable の各インターフェイスを実装しています。
HashMap の容量。デフォルトは 16 です。
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
HashMapのロードファクター、デフォルトは0.75です。
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
HashMapの要素数が容量*負荷率を超えると、HashMapが拡張される。
HashMapの実装原理
ノードとノードチェーン
まずは、HashMapの要素型を理解することから始めましょう。
HashMapクラスの要素はNodeクラスで、これはノードと訳され、Map.Entryインターフェイスを実装したHashMapで定義される内部クラスである。
Nodeクラスは以下のように定義されています。
/**
* Basic hash bin node, used for most entries. (See below for
* TreeNode subclass, and in LinkedHashMap for its Entry subclass.)
*/
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<? ,? > e = (Map.Entry<? ,? >)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue())))
return true;
}
return false;
}
}
ご覧の通り、Nodeクラスの基本的なプロパティは以下の通りです。
ハッシュ : キーのハッシュ
キー : ノードのキー。HashMap を定義するために使用されるキーと同じタイプである。
値 : ノードの値で、HashMap を定義するために使用された値と同じタイプです。
次 : このノードの次のノード
注目すべきは、そこにある次のノード自身を記録するnext属性もNodeノードであり、このNodeノードも次のノードを記録するnext属性を持っているので、常にNode.next.next......と呼ぶことで、次のようになることです。
Node--> next Node--> next next Node ......--> null
このようなリンクテーブル構造で、HashMapの場合、各チェーンの最初のノードが明示的に記録されていれば、チェーン上のすべてのノードを順次トラバースすることができる。
鎖の引き方
HashMapは、その中の各ノードを管理するために、zipperメソッドを使用します。
HashMapはNodeノードからチェーンテーブルを形成した後、Nodeの配列を定義する。
transient Node<K,V>[] table;
この配列には各チェーンテーブルの最初のノードが記録され、以下のようなHashMapのデータ構造になります。
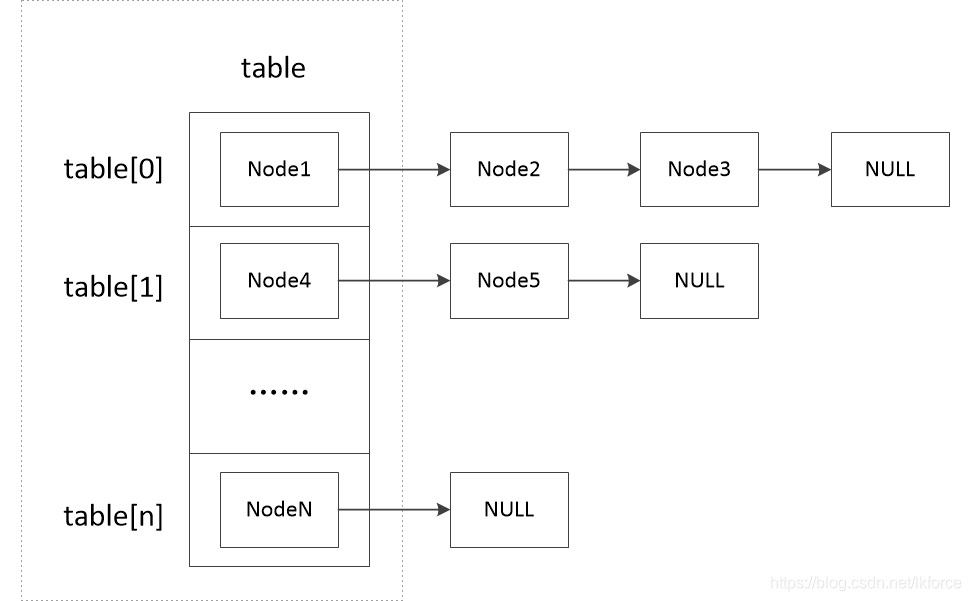
この配列+チェーンテーブルのデータ構造により、HashMapは各ノードをより効率的に管理することができます。
ノード配列テーブルについて
テーブルについて理解しておくと、後でスケーリングについて理解するのに便利です。
tableは、HashMapに初めて要素を入れたときに初期化されます。
HashMapの初期化時に容量が指定されていない場合、テーブルはデフォルトの デフォルトの初期容量 パラメータは16で、これが初期化時のテーブルの長さです。
HashMapの初期化時に容量が指定された場合、この容量を2の倍数に修正し、対応する長さのテーブルを作成します。
テーブルの長さは、HashMap が拡張されたときに 2 倍になります。
したがって、tableの長さは2の倍数でなければなりません。
容量を修正する方法はこうです。
/**
* Returns a power of two size for the given target capacity.
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
つまり、HashMapに1000個の要素を入れたいが、HashMapがどんどん膨張するのが嫌な場合は、最初に容量を2048に設定するのがベストで、1024に設定しても、要素が700個以上追加されると膨張するのでうまくいかないので注意しましょう。
ハッシュアルゴリズム
HashMap.put()メソッドが呼ばれると、次のような手順が経験されます。
1, キーに対応するハッシュ値を計算する。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> > 16);
}
2、ハッシュ値とtable.length moduloの関係
モジュロは (table.length - 1) & hash で、バイナリハッシュ値のうち table.length 以上のビットは table.length の 2 の n 乗を表すので、アルゴリズムは直接破棄します。
モジュロの結果は、Nodeがテーブルに入れる添え字になります。
例えば、あるNodeのハッシュ値が5でテーブル長が4の場合、余りの結果は1であり、そのNodeはtable[1]で表される鎖に入れられることになる(table[1]自体が鎖の最初のノードを指し示している)。
3, 要素を追加する
この時点でtableの対応する位置に要素がない場合、つまりtable[i]=nullの場合は、table[i]の位置に直接Nodeを入れ、このNodeのnext==nullを指定します。
この時点でtableの対応する位置がNodeであれば、対応する位置にNodeチェーンが保存されていることを意味するので、チェーンをたどり、同じハッシュ値があればNodeノードを置き換え、なければ新しいNodeを前の終了Nodeの次としてチェーンの最後に挿入し、新しいNodeの次 == nullを指定する必要があります。
この時点でtableの対応する位置がTreeNodeであれば、チェーンを赤黒木に変換し、ハッシュ値に基づいて赤黒木にTreeNodeを追加または置換する(JDK1.8)。
4、要素追加後、Node chainのノード数が8を超えた場合、red-black treeへの変換を検討する。(JDK1.8)
5, 要素追加後、HashMapのノード総数が閾値を超えると、HashMapが拡張されます。
該当するコードは以下のようになります。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null) // comment 1
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key ! = null && key.equals(k)))) //Note 2
e = p;
else if (p instanceof TreeNode) //Note 3
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash); // comment 4
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key ! = null && key.equals(k))))
break;
p = e;
}
}
if (e ! = null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold) //comment 5
resize();
afterNodeInsertion(evict);
return null;
}
コード解析中。
1、コメント1、テーブルの対応する位置にノードがない、その後、新しいノードノードを作成して対応する位置に置く。
2, コメント 2, テーブルの対応する場所にノードがあり、ハッシュ値が一致すれば、それを置き換える。
3, comment 3, table has a node at corresponding location. tableの対応する場所が既にTreeNodeであり、Nodeでなくなっている場合、つまりtableの対応する場所がTreeNodeであり、チェーンから赤黒木に変換されたことを示す場合、赤黒木ノードを挿入するロジックが実行される。
コメント4、tableが対応する位置にノードを持ち、そのノードがNode(赤黒木ではなくチェーンの状態)であり、チェーンのノード数がTREEIFY_THRESHOLDより大きい場合、赤黒木に変更することを検討します。実際には、それは本当にすぐに変更されませんが、拡張も問題を解決することができるときにテーブルが短く、コードは後で言及されます。
5、コメント5、HashMapのノード数が閾値より大きいので、拡張されます。
HashMapと赤黒い木
JDK 1.8 以降、HashMap 内部で定数 TREEIFY_THRESHOLD が定義され、デフォルトは 8 です。チェーンのノード数がTREEIFY_THRESHOLDより大きい場合、チェーンは赤黒木とみなされます。そのためのコードは、上記のputVal()メソッドのこのセクションに記載されています。
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key ! = null && key.equals(k))))
break;
p = e;
}
treeifyBin()メソッドは、チェーンテーブルから赤黒いツリーにするメソッドで、このメソッドのコードは次のようになります。
/**
* Replaces all linked nodes in bin at index for given hash unless
* table is too small, in which case resizes instead.
*/
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) ! = null) {
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) ! = null);
if ((tab[index] = hd) ! = null)
hd.triify(tab);
}
}
MIN_TREEIFY_CAPACITYのデフォルト値は64です。これを拡張して再ハッシュ化するだけです。
コードの後半にあるように、テーブルの長さが64に達した場合、赤黒木に変わり始め、else ifのコードは元のNodeノードをTreeNodeノードに変え、赤黒木変換を行うのです。
TreeNodeについて
HashMapが鎖状テーブルを赤黒い木に変えるとき、元のNodeノードはTreeNodeノードに変わりますが、これもHashMapで定義された内部クラスで、おおよそ次のように定義されます。
/**
* Entry for Tree bins. extends LinkedHashMap.Entry (which in turn
* Entry (which in turn extends Node) so can be used as extension of either regular or
Entry (which in turn * extends Node) so can be used as extension of either regular or * linked node.
*/
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
/**
* Returns the root of tree containing this node.
*/
final TreeNode<K,V> root() {
for (TreeNode<K,V> r = this, p;;) {
if ((p = r.parent) == null)
return r;
r = p;
}
}
/**
* Ensures that the given root is the first node of its bin.
*/
static <K,V> void moveRootToFront(Node<K,V>[] tab, TreeNode<K,V> root) {
int n;
if (root ! = null && tab ! = null && (n = tab.length) > 0) {
int index = (n - 1) & root.hash;
TreeNode<K,V> first = (TreeNode<K,V>) tab[index];
if (root ! = first) {
Node<K,V> rn;
tab[index] = root;
TreeNode<K,V> rp = root.prev;
if ((rn = root.next) ! = null)
((TreeNode<K,V>)rn).prev = rp;
if (rp ! = null)
rp.next = rn;
if (first ! = null)
first.prev = root;
root.next = first;
root.prev = null;
}
assert checkInvariants(root);
}
}
/**
* Finds the node starting at root p with the given hash and key.
* The kc argument caches comparableClassFor(key) upon first use
* comparing keys.
*/
final TreeNode<K,V> find(int h, Object k, Class<? > kc) {
TreeNode<K,V> p = this;
do {
int ph, dir; K pk;
TreeNode<K,V> pl = p.left, pr = p.right, q;
if ((ph = p.hash) > h)
p = pl;
else if (ph < h)
p = pr;
else if ((pk = p.key) == k || (k ! = null && k.equals(pk))))
return p;
else if (pl == null)
p = pr;
else if (pr == null)
p = pl;
else if ((kc ! = null ||
(kc = comparableClassFor(k)) ! = null) &&
(dir = compareComparables(kc, k, pk)) ! = 0)
p = (dir < 0) ? pl : pr;
else if ((q = pr.find(h, k, kc)) ! = null)
return q;
else
p = pl;
} while (p ! = null);
return null;
}
このように、TreeNode は LinkedHashMap の Entry を継承し、ハッシュ値、キー、値、次のノード next を指定して、Node と同じ構造を持つノードを構築しています。
また、TreeNode は親 parent、左子 left、右子 right、前ノード prev、および赤黒木に使用される red 属性を保持します。
赤黒い木の基本
赤黒木は、絶対的なバランスはとれないが、任意のノードの左右の部分木の高さの差が、低い方の高さの2倍を超えないことが保証された、近似バランス2分木である。
赤黒い木は次のような特徴がある。
<ブロッククオート1、各ノードが赤か黒のどちらかである。
2、ルートノードは黒でなければならない。リーフノードは黒のNULLノードでなければならない。
3, 赤色のノードは連続できません。
4, 各ノードについて、その点から葉ノードまでのどのパスも同じ数の黒ノードを含む。
5, 検索、挿入、削除の操作を O(log2(N)) の時間計算量で実行できる。また、アンバランスは3回転以内に解消される。
HashMapのスケーリング機構
HashMap がその容量を拡大することを決定したとき、HashMap は resize(int newCapacity) メソッドに、新しいテーブルの長さを引数として渡します。JDK1.7とJDK1.8では、拡張の仕組みが大きく異なります。
JDK1.7でのスケーリングメカニズム
JDK1.7でのresize()メソッドは以下のようになります。
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
コードにあるように、元のテーブルの長さが制限に達した場合、それ以上拡張されなくなります。
制限に達していない場合は、新しいテーブルが作成され、転送メソッドが呼び出されます。
/**
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null ! = e) {
Entry<K,V> next = e.next; //comment 1
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity); //Note 2
e.next = newTable[i]; //Note 3
newTable[i] = e; //annotation 4
e = next; //comment 5
}
}
}
転送メソッドの機能は、元のテーブルのNodeを新しいテーブルに入れることです。 ヘッダー挿入方式 というのは、新しいテーブルのリンクの順番が古いリストと逆になり、HashMap のスレッドインセキュリティの場合、このヘッド挿入によりリングノードが発生する可能性があるからです。
whileループでは、ヘッダ挿入の処理を記述しています。ロジックは少し複雑なので、コードを解析するための例を示します。
元のテーブルレコードのある連鎖、例えばtable[1]=3、3-->5-->7と仮定すると、処理の流れは次のようになります。
1, comment 1: e.nextの値を記録する。最初のeはtable[1]なので、e==3、e.next==5となり、この時点でnext==5となる。
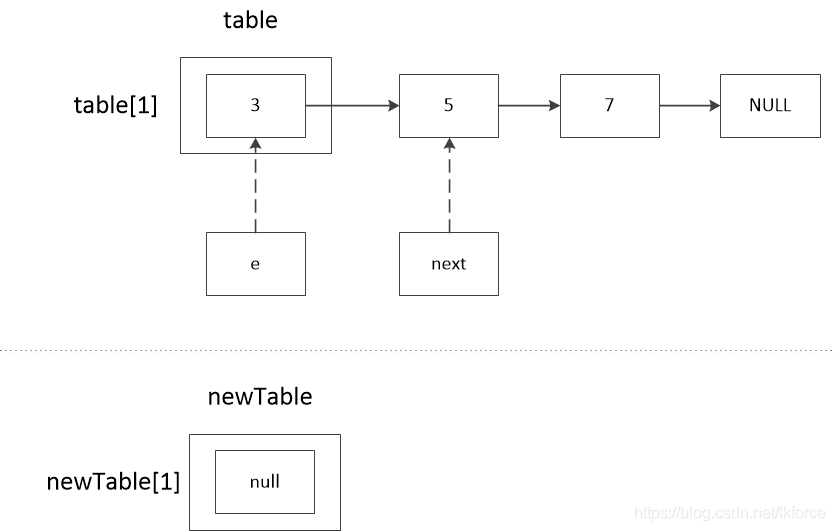
2のコメント2は、newTableのeのノードを計算する。ヘッダ補間の逆順結果を示すため、ここではeが再びnewTable[1]のチェーンにハッシュ化されることを仮定している。
3, comment 3, newTable [1] を e.next に代入。newTable は新規に作成されているので、newTable[1]==null で、この時点では 3.next==null です。
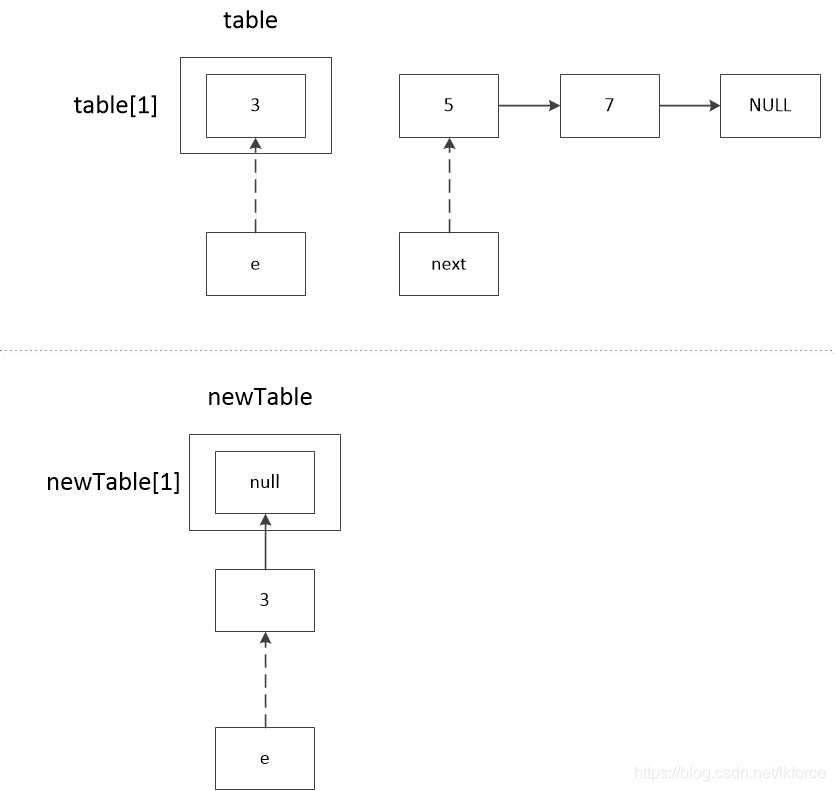
4, コメント 4, e が newTable[1] に代入されます。この時点でnewTable[1]=3です。
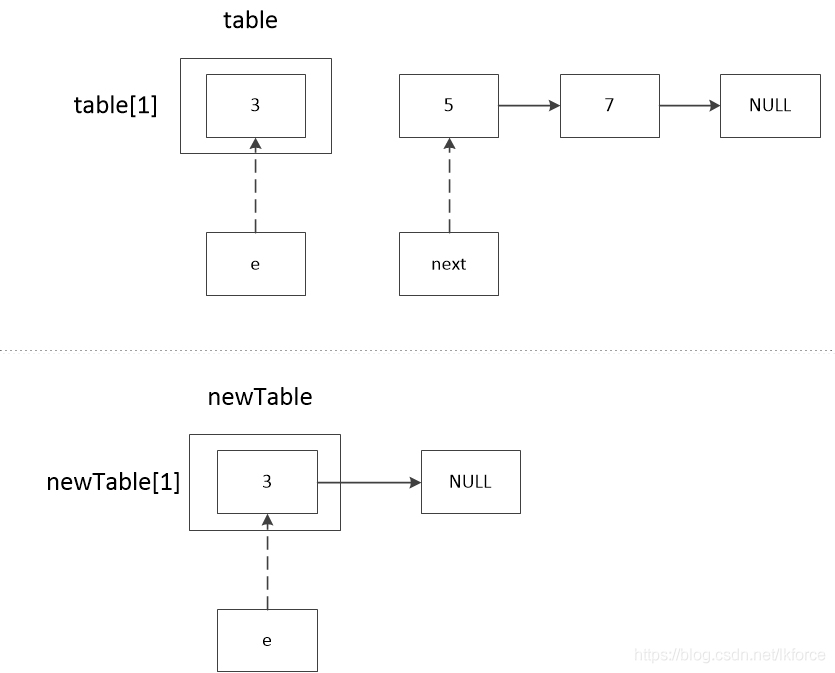
5, comment 5, next が e に代入されています。この時点で e==5 です。
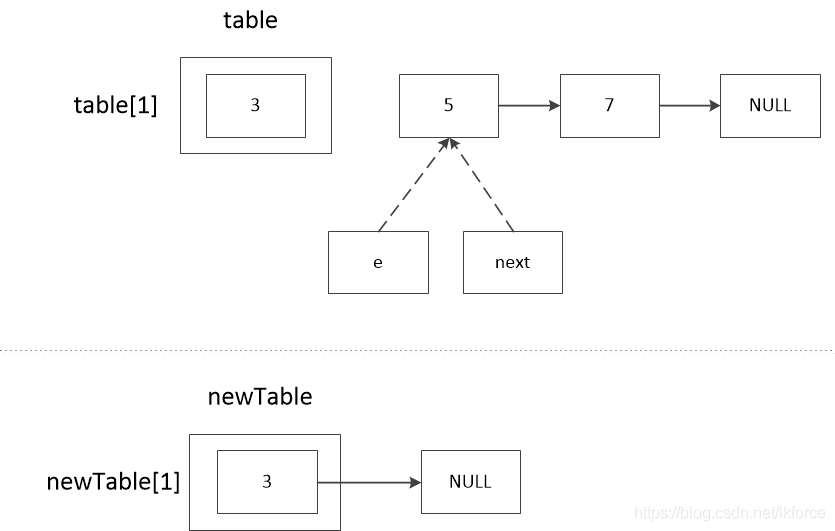
この時点で、最初のノード3がnewTable[1]に追加され、以下は2番目のループに入り、e==5で始まる。
1, comment 1: e.nextの値を記録する。5.nextは7なので、next==7です。
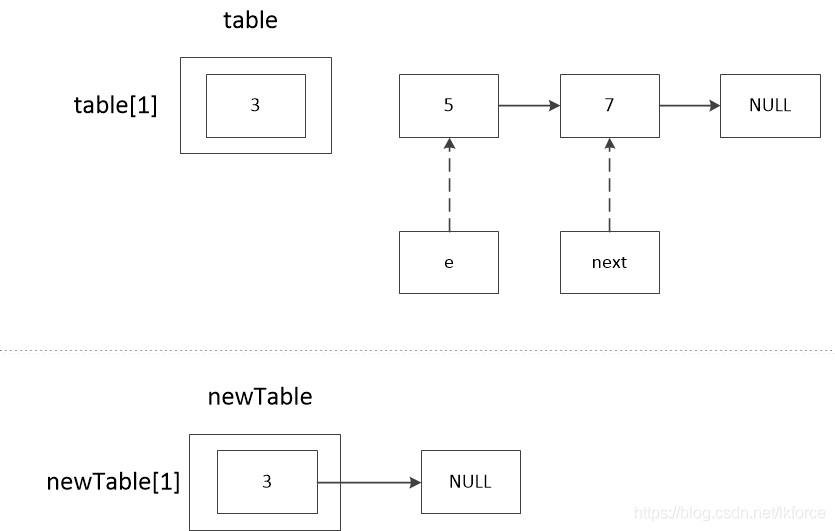
2のコメント2は、newTableのeのノードを計算する。ヘッダ補間の逆順結果を示すため、ここではeが再びnewTable[1]のチェーンにハッシュ化されることを仮定している。
3 のコメント 3 では、e.next に newTable [1] を代入しています。newTable [1]は3(前のループのコメント4参照)、eは5なので、5.next == 3となります。
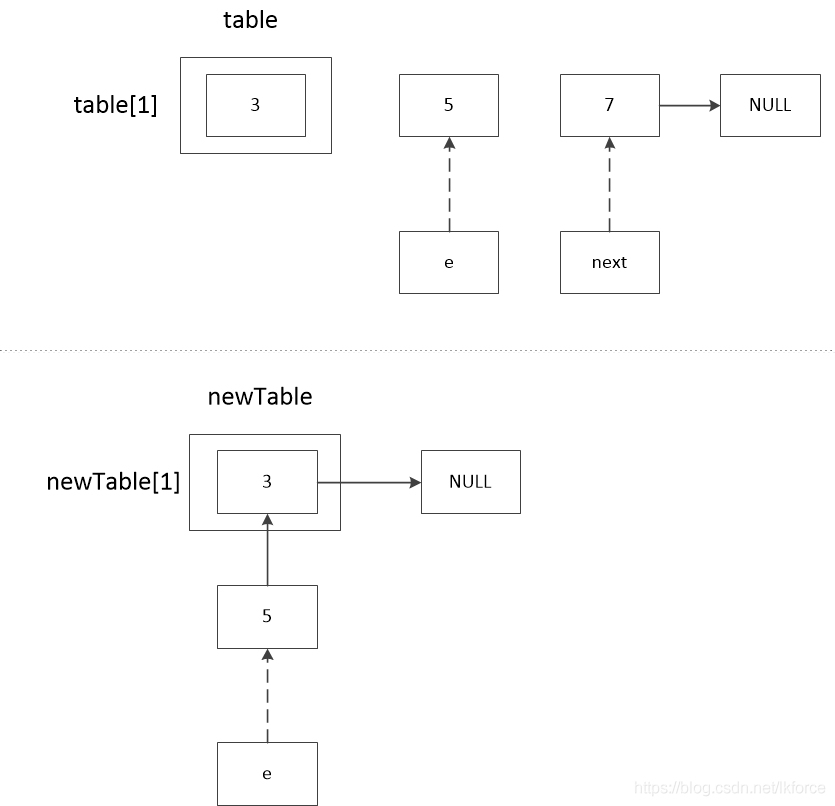
4, コメント 4, e が newTable[1] に代入されています。この時点でnewTable[1]==5です。
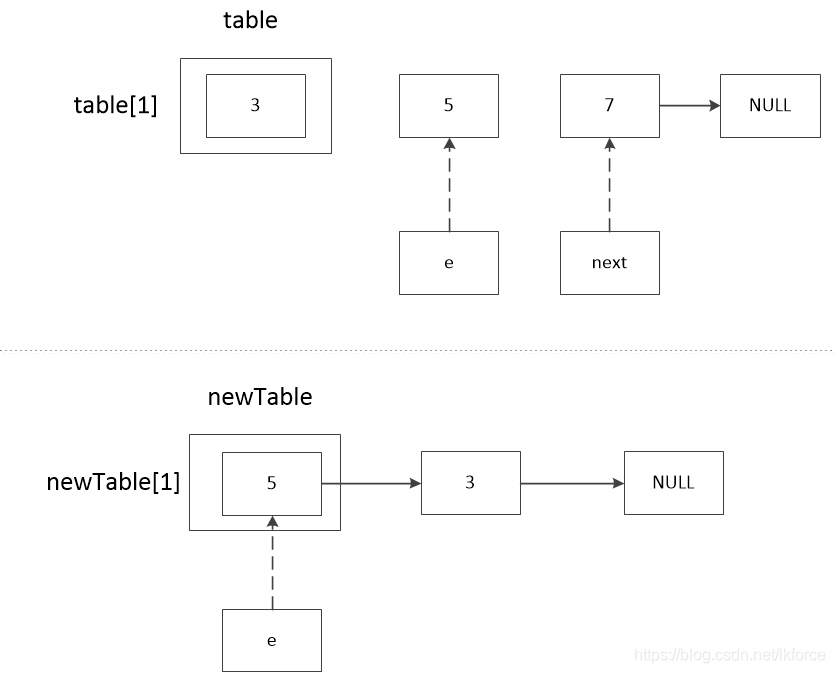
5, comment 5, next が e に代入されます。この時点で e==7 です。
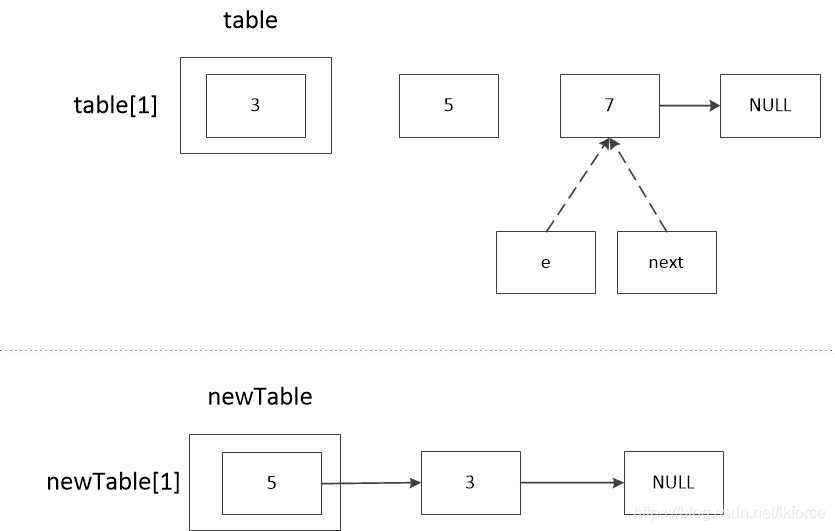
この時点でnewTable[1]は5であり、連鎖の順番は5-->3である。
ここで3回目のループに入り、2回目のループはe==7で始まる。
1, コメント 1: e.next の値を記録します。7.next は NULL なので、next == NULL です。
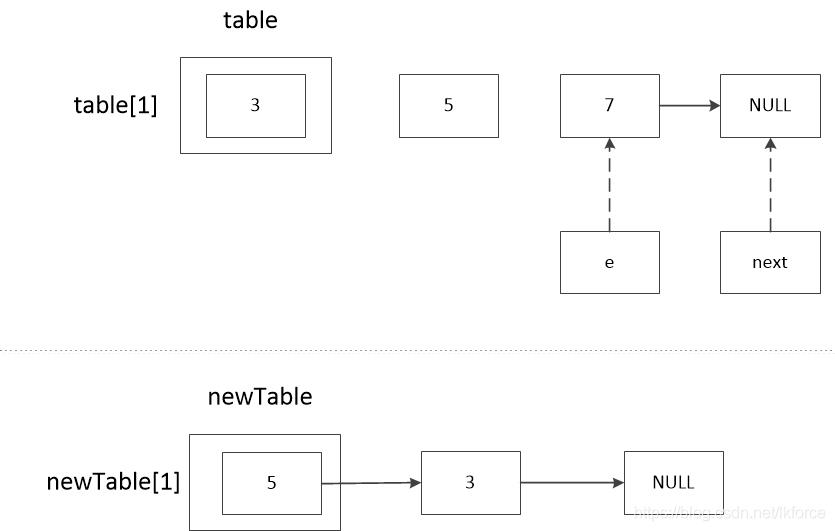
2のコメント2は、newTableのeのノードを計算する。ヘッダ補間の逆順結果を示すため、ここではeが再びnewTable[1]のチェーンにハッシュ化されることを仮定している。
3, コメント 3, e.next に newTable [1] を代入する。newTable [1]は5(前のループのコメント4参照)、eは7なので、7.next==5となります。
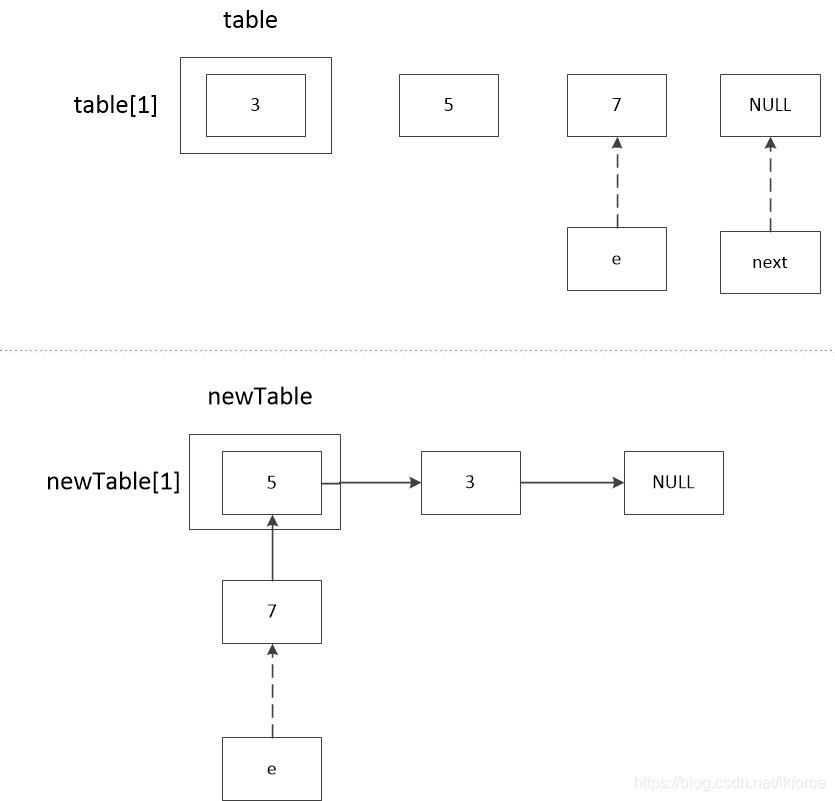
4, コメント 4, e が newTable[1] に代入されています。この時点でnewTable[1]==7です。
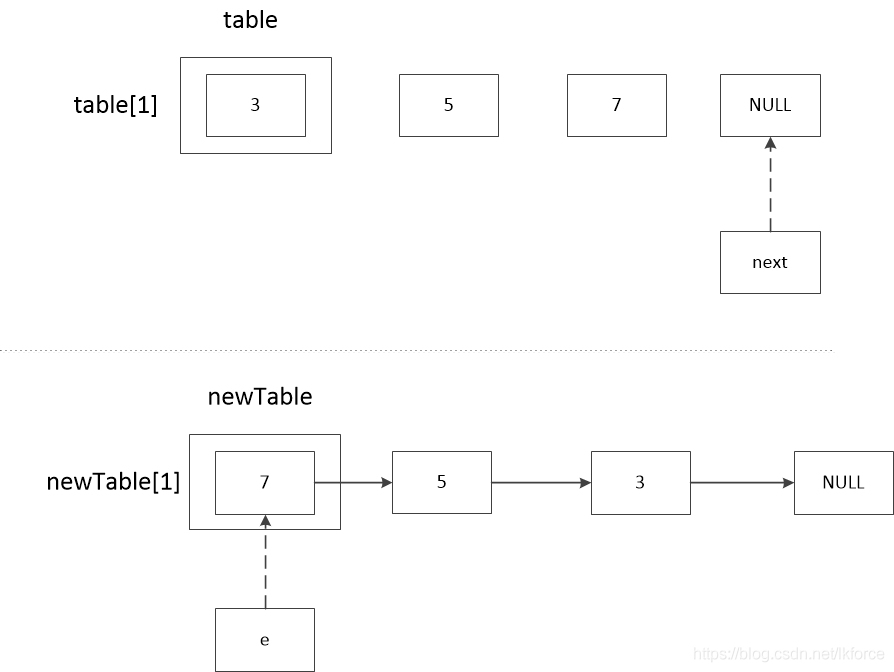
5, comment 5, next が e に代入されます。この時点では e==NULL です。
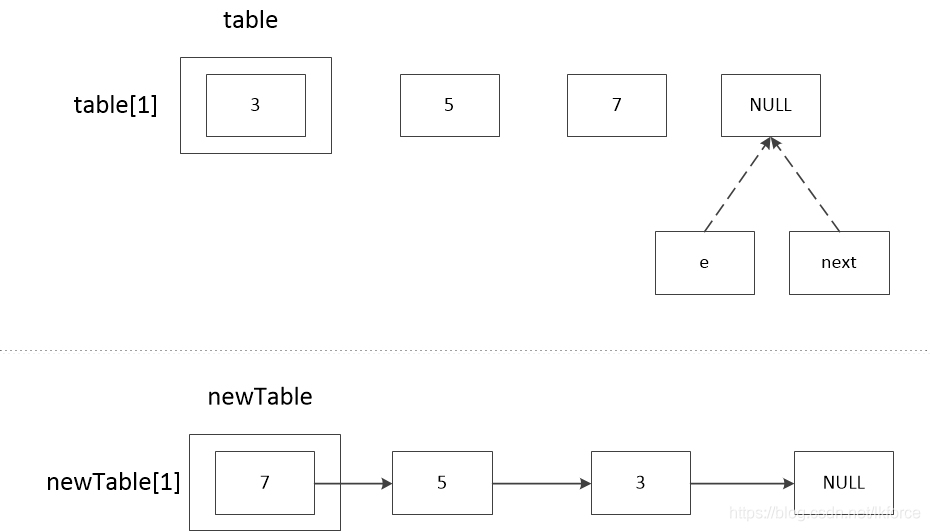
この時点でnewTable[1]は7となり、ループは終了し、鎖の順番は7 - >5 - >3 となり、元の鎖とは逆の順番になります。
注意:この逆順展開では、マルチスレッド時に円形チェーンテーブルとして表示される可能性があります。循環するチェーンテーブルが発生する理由はおそらくこうである。スレッド 1 がノードを処理する準備ができていて、スレッド 2 が HashMap の展開に成功し、チェーンテーブルが逆順になった。
また、別件で indexFor(e.hash, newCapacity)を使用します。 メソッドは、新しいテーブルにおけるノードの添え字を計算するために使用され、次のようなコードを持っています。
/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
}
添え字を計算するアルゴリズムは単純ですが、ハッシュ値と(長さ-1)とビットで、長さ-1を使用する意義は、長さが2の倍数であるということですので、長さ-1は、バイナリ内の各ビットに対して1であり、これはハッシュハッシュ値の最大度を確保できる、それ以外は、ビットがあるときにハッシュ値の対応ビットかかわらず1または0です、ビットでそれ以外は、ときに1ビットは0、結果は重複ハッシュになる0、されるでしょう。
JDK1.8でのスケーリングメカニズム
JDK 1.8ではresize()メソッドが大きく調整され、以下のようになりました。
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) { if (oldCap > 0)
if (oldCap > = MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY & &
oldCap >= DEFAULT_INITIAL_CAPACITY) //comment 1
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab ! = null) {
for (int j = 0; j < oldCap; ++j) { //Note 2
Node<K,V> e;
if ((e = oldTab[j]) ! = null) {
oldTab[j] = null;
if (e.next == null) //Note 3
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) { //Note 4
if (loTail == null) //Note 5
loHead = e;
else
lo
コード解析中。
1、resize()メソッドでは、元のテーブルの長さを記録するoldCapパラメータと、新しいテーブルの長さを記録するnewCapパラメータが定義されています。newCapはoldCapの2倍(コメント1)、拡張ポイントも2倍になっています。
2, コメント 2 は、元のテーブルをループして、元のテーブルの各鎖から各要素を新しいテーブルに入れる。
3、コメント3、e.next==nullは、チェーンテーブルに要素が1つしかないことを意味するので、eを直接新しいテーブルに入れます。e.hash & (newCap - 1) は新しいテーブルでのeの位置を計算していますが、これはJDK1.7の indexFor() と同じことです。
4、コメント//順序を維持し、このコメントは、ソースコードに付属しており、ここでは4変数を定義しています:loHead、loTail、hiHead、hiTail、少し目まいに見えるかもしれませんが、実際にはここでテーブル添字のアイデアのノードを計算するための新しいJDK1.8を反映しています:その。
通常、テーブルのノードの添え字を計算する方法は次のとおりです。hash&(oldTable.length-1)、拡張後、テーブル長が2倍になり、テーブルの添え字を計算する方法はhash&(newTable.length-1)、すなわち、hash&( oldTable.length*2-1) 、だから私たちには次の結論があるのです。 この新旧の添え字を計算した結果は、同じか、新しい添え字が古い添え字に古い配列の長さを加えたものになるかのどちらかです .
例えば、元のテーブル長が16で拡張長が32の場合、拡張前と拡張後のハッシュ値のテーブル添え字は以下のように計算されます。
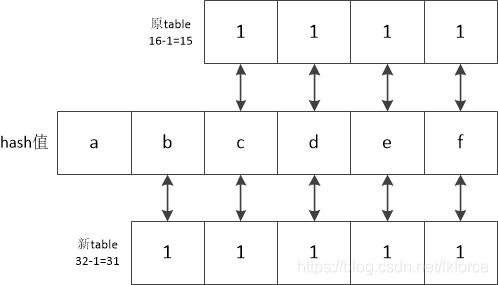
ハッシュ値の各バイナリビットはabcdeで表されるので、ハッシュの最後の4ビットと新旧テーブルのビット比較の結果は明らかに同じであり、唯一の違いは5ビット目、つまりハッシュ値のbがあるビットにある可能性があるだけです。bのビットが0の場合、新しいテーブルと古いテーブルのビット比較の結果は同じであり、逆の場合 bのビットが1の場合、新しいテーブルの結果は古いテーブルの結果より1万(2進数)多く、2進数の1万は古いテーブルの長さである16となります。
つまり、ハッシュ値の新しい添え字を旧テーブルの長さに加える必要があるかどうかは、ハッシュ値の5ビット目が1かどうかを見ればよい。 ビット演算はハッシュ値と10000(これは旧テーブルの長さ)のビット和であり、結果は10000か00000にしかならない。
つまり、コメント4のe.hashamp &oldCapは、位置bが0か1かを計算するために使用されます。結果が0であれば、新しいハッシュ添え字は元のハッシュ添え字と同じになり、そうでなければ、新しいハッシュ座標は元のハッシュ座標の上に元のテーブル長を追加します。
上記の原理を理解すると、ここでのコードは4つの変数が定義されており、理解しやすいと思います。
<ブロッククオートloHead, 定数の添え字を持つチェーンの先頭部分
loTail: 一定の添え字を持つチェーンの末端。
hiHead - 添え字が変更された場合のチェーンの先頭です。
hiTail、添え字が変更された場合のチェーンの終端
そして、コメント4の (e.hash & oldCap) == 0 は、ハッシュの添え字が変更されていない場合を表しており、この場合、コードはチェーンテーブルを構成する loHead と loTail 引数のみを使用し、それ以外の場合は hiHead と hiTail 引数を使用することになります。
実は、e.hash & oldCapが0になるのとならないのとでは、変数が違うだけで、ロジックは全く同じなのです。
例として、0に等しい場合を取り上げ、3 - >5 - >7 のチェーンテーブルを以下のように処理します。
最初の処理ノード 3, e == 3, e.next == 5
1、コメント5、最初はloTailがNULLなので、loHeadに3を代入する。
2, コメント 7, loTail に 3 を代入。
次にノード5をe==5、e.next==7で処理します。
1、コメント6、loTailに値がある、eをloTail.nextに代入すると、3.next==5となる。
2、コメント7、loTailに5を代入する。
新しいチェーンは3-->5となり、次にノード7が処理されます。処理後、チェーンの順番は3-->5-->7となり、loHeadが3、loTailが7となります。このように、チェーン内のノードの順番は元のチェーンと同じで、JDK1.7のような逆順ではなくなりました。
ここのコメント8までが、より理解しやすいコードです。
loTail が null でない限り、新しいテーブルの要素の添え字は変更されていないことを意味するので、新しいテーブルの対応する添え字は loHead であり、loTail の次には null が設定されます。
逆に、hiTail は NULL ではないので、新しいテーブルの要素の添え字は元の添え字に元のテーブルの長さを加えたものになり、新しいテーブルの対応する添え字は hiHead になり、hiTail の次が NULL になるはずです。
記事終了
関連
-
mvn' は、内部または外部のコマンド、操作可能なプログラムまたはバッチファイルとして認識されません。
-
Eclipseは、ポップアップA Java Exception has occurred.を実行し、エラーException in threadの解決策を報告します。
-
Eclipse の問題 アクセス制限。タイプ 'jfxrt' はAPI解決されていません。
-
Uncaught ReferenceError: は定義されていません。
-
が 'X-Frame-Options' を 'sameorigin' に設定したため、フレーム内に存在する。
-
java -jarコマンドでパッケージを実行すると、無効または破損したjarfile xxxx.jarが表示される。
-
Javaジェネリックを1つの記事で
-
XXX型を囲むインスタンスがJavaでアクセスできない
-
java send https request prompt java.security.cert.について。
-
JDK8 の Optional.of と Optional.ofNullable メソッドの違いと使い方を説明する。
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
メモ帳でJavaプログラムをコンパイルして実行すると、Could not find or load main class ...というエラーが表示される。解決方法
-
ApplicationContextの起動エラーです。条件レポートを表示するには、アプリケーションを'de'で再実行します。
-
配列定数は初期化子でのみ使用可能です。
-
FindBugの使用概要
-
Javaがリソースリークに遭遇した:'input'が閉じない 解決方法
-
Server Tomcat v9.0 Server at localhost の起動に失敗しました。
-
コンストラクタDate()が未定義である問題
-
git pull appears現在のブランチに対するトラッキング情報がありません。
-
ロンボク版問題による血の海を思い出せ
-
Prologでは、コンテンツは許可されていません。