パンダを使った高速な句読点除去
質問
これは自己回答の投稿です。以下では、NLPドメインにおける一般的な問題の概要を説明し、それを解決するためのいくつかの実行可能なメソッドを提案します。
しばしば、以下のような問題を解決する必要が生じます。
句読点
を削除する必要が生じることがあります。句読点とは
string.punctuation
:
>>> import string
string.punctuation
'!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~'
これは十分に一般的な問題で、以前から何度も質問されています。最も一般的な解決策は、パンダを使うことです。
str.replace
. しかし
ロット
のテキストを含む状況では、よりパフォーマンスの高い解決策を検討する必要があるかもしれません。
の代替となる、性能の良いものは何でしょうか?
str.replace
に代わるパフォーマンス的な方法は何でしょうか?
どのように解決するのですか?
設定方法
デモのために、このDataFrameを考えてみましょう。
df = pd.DataFrame({'text':['a..b?!??', '%hgh&12','abc123!!!', '$$$1234']})
df
text
0 a..b?!??
1 %hgh&12
2 abc123!!!
3 $$$1234
以下に、代替案を一つずつ、性能の高い順に列挙します。
str.replace
このオプションは、他のより性能の高いソリューションを比較するためのベンチマークとして、デフォルトのメソッドを確立するために含まれています。
これはpandasに内蔵されている
str.replace
という正規表現に基づく置換を行う関数を使用しています。
df['text'] = df['text'].str.replace(r'[^\w\s]+', '')
df
text
0 ab
1 hgh12
2 abc123
3 1234
これは非常に簡単にコーディングでき、かなり読みやすいですが、遅いです。
regex.sub
これには
sub
関数から
re
ライブラリから呼び出されます。パフォーマンスのために正規表現パターンをあらかじめコンパイルしておき、 その上で
regex.sub
をリスト内包の中で呼び出します。変換
df['text']
をあらかじめリストに変換しておくと、パフォーマンスが向上します。
import re
p = re.compile(r'[^\w\s]+')
df['text'] = [p.sub('', x) for x in df['text'].tolist()]
df
text
0 ab
1 hgh12
2 abc123
3 1234
注意 データにNaN値がある場合、この方法(以下の次の方法と同様)はそのままでは動作しません。詳細は「"」の項を参照してください。 その他の検討事項 "を参照してください。
str.translate
pythonの
str.translate
関数は C で実装されているため
非常に高速です。
.
この仕組みは
- まず、すべての文字列を結合して、1つの 巨大な 文字列を結合します。 セパレータ その あなた を選択します。あなたは は は、データ内に属さないことを保証できる文字/サブストリングを使用する必要があります。
-
実行する
str.translateを実行し、句読点を削除します (ステップ 1 のセパレータは除外)。 - ステップ1で結合に使われたセパレータで文字列を分割する。結果として得られるリスト は は最初の列と同じ長さでなければなりません。
ここで、この例では、パイプセパレータを考慮した
|
. もし、データにパイプが含まれている場合は、別のセパレータを選択する必要があります。
import string
punct = '!"#$%&\'()*+,-./:;<=>?@[\\]^_`{}~' # `|` is not present here
transtab = str.maketrans(dict.fromkeys(punct, ''))
df['text'] = '|'.join(df['text'].tolist()).translate(transtab).split('|')
df
text
0 ab
1 hgh12
2 abc123
3 1234
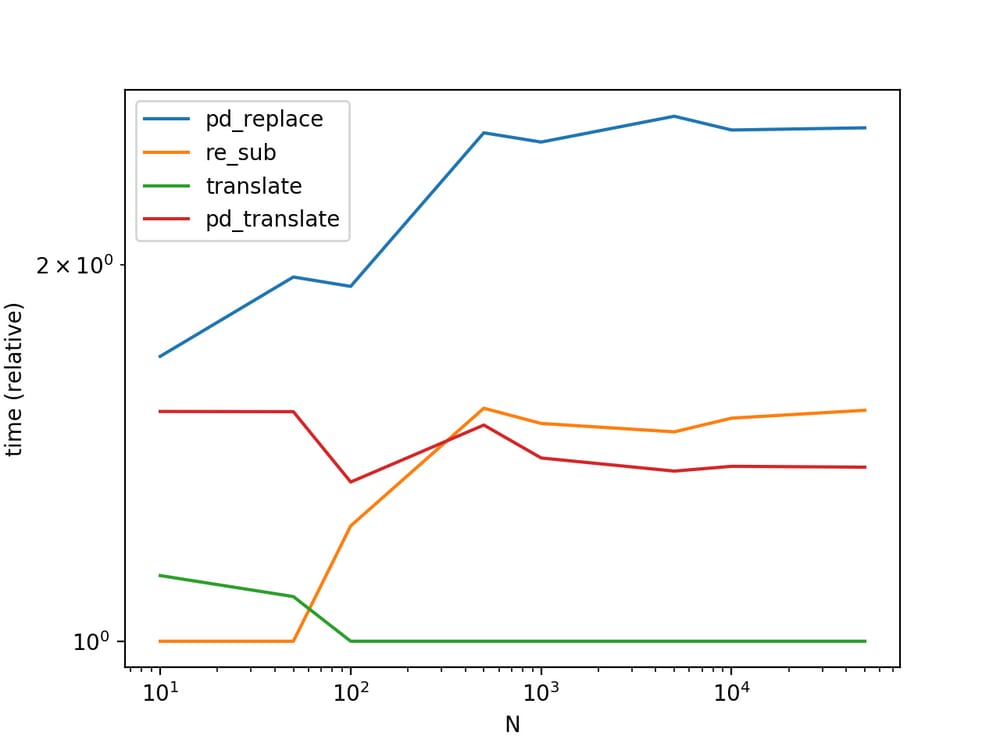
パフォーマンス
str.translate
は圧倒的に良いパフォーマンスを示します。下のグラフには、別のバリアント
Series.str.translate
から
MaxUの回答
.
(興味深いことに、これを2回目に再実行したところ、結果が以前と若干異なっています。2回目の実行の間、どうやら
re.sub
に勝っていたようです。
str.translate
に勝っていました)。
を使用することには、固有のリスクがあります。
translate
(の問題)。
を自動化する
の自動化の問題は自明ではありません)、しかし、トレードオフはリスクに見合うものです。
その他の考慮事項
リスト内包メソッドでNaNを処理する。 このメソッド(と次のメソッド)は、データにNaNがない限り動作することに注意してください。NaNを扱う場合、NULLでない値のインデックスを決定し、その値のみを置き換える必要があります。以下のような方法を試してみてください。
df = pd.DataFrame({'text': [
'a..b?!??', np.nan, '%hgh&12','abc123!!!', '$$$1234', np.nan]})
idx = np.flatnonzero(df['text'].notna())
col_idx = df.columns.get_loc('text')
df.iloc[idx,col_idx] = [
p.sub('', x) for x in df.iloc[idx,col_idx].tolist()]
df
text
0 ab
1 NaN
2 hgh12
3 abc123
4 1234
5 NaN
DataFrameを扱う。 DataFrameを扱う場合、どこで それぞれ カラムの交換が必要ですが、手順は簡単です。
v = pd.Series(df.values.ravel())
df[:] = translate(v).values.reshape(df.shape)
または
v = df.stack()
v[:] = translate(v)
df = v.unstack()
なお
translate
関数はベンチマークコードと一緒に以下で定義されていることに注意してください。
すべてのソリューションにはトレードオフがあり、どのソリューションが自分のニーズに最も合うかを決定することは、何を犠牲にしても構わないかどうかによります。2 つの非常に一般的な考慮事項は、パフォーマンス (これはすでに見てきました) とメモリ使用量です。
str.translate
はメモリを大量に消費するソリューションなので、注意して使用してください。
もう一つの考慮点は、正規表現の複雑さです。英数字や空白でないものをすべて削除したい場合もあります。また、ハイフン、コロン、文の終端記号など、特定の文字を残す必要がある場合もあります。
[.!?]
. これらを明示的に指定すると、正規表現が複雑になり、その結果、これらのソリューションのパフォーマンスに影響を与える可能性があります。これらの解決策は、必ず自分のデータでテストして
をテストしてから、使用するものを決定してください。
最後に、このソリューションではユニコード文字が削除されます。正規表現 (正規表現ベースのソリューションを使用している場合) を微調整するか、単に
str.translate
を使用することもできます。
についても より パフォーマンス (より大きな N の場合) は ポール・パンザー .
付録
機能紹介
def pd_replace(df):
return df.assign(text=df['text'].str.replace(r'[^\w\s]+', ''))
def re_sub(df):
p = re.compile(r'[^\w\s]+')
return df.assign(text=[p.sub('', x) for x in df['text'].tolist()])
def translate(df):
punct = string.punctuation.replace('|', '')
transtab = str.maketrans(dict.fromkeys(punct, ''))
return df.assign(
text='|'.join(df['text'].tolist()).translate(transtab).split('|')
)
# MaxU's version (https://stackoverflow.com/a/50444659/4909087)
def pd_translate(df):
punct = string.punctuation.replace('|', '')
transtab = str.maketrans(dict.fromkeys(punct, ''))
return df.assign(text=df['text'].str.translate(transtab))
パフォーマンス・ベンチマーク・コード
from timeit import timeit
import pandas as pd
import matplotlib.pyplot as plt
res = pd.DataFrame(
index=['pd_replace', 're_sub', 'translate', 'pd_translate'],
columns=[10, 50, 100, 500, 1000, 5000, 10000, 50000],
dtype=float
)
for f in res.index:
for c in res.columns:
l = ['a..b?!??', '%hgh&12','abc123!!!', '$$$1234'] * c
df = pd.DataFrame({'text' : l})
stmt = '{}(df)'.format(f)
setp = 'from __main__ import df, {}'.format(f)
res.at[f, c] = timeit(stmt, setp, number=30)
ax = res.div(res.min()).T.plot(loglog=True)
ax.set_xlabel("N");
ax.set_ylabel("time (relative)");
plt.show()
関連
-
[解決済み] PandasでDataFrameの行を反復処理する方法
-
[解決済み] Python 3で「1000000000000000 in range(1000000000000001)」はなぜ速いのですか?
-
[解決済み] Pandasのカラム名のリネーム
-
[解決済み] Pandas DataFrameからカラムを削除する
-
[解決済み] Pandasのデータフレームで複数の列を選択する
-
[解決済み] Pandas DataFrameの行数を取得する方法は?
-
[解決済み] 既存のDataFrameに新しい列を追加する方法は?
-
[解決済み】大文字と数字を含むランダムな文字列の生成
-
[解決済み】Pandas DataFrameのカラムヘッダからリストを取得する。
-
[解決済み】PandasでSettingWithCopyWarningに対処する方法
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み] SQLAlchemy: セッションの作成と再利用
-
[解決済み] PythonでファイルのMD5チェックサムを計算するには?重複
-
[解決済み] pandasのDataFrameから空のセルを含む行を削除する
-
[解決済み] Djangoで2つの日付の間を選択する
-
[解決済み] 辞書のキーと値を交換するにはどうすればよいですか?
-
[解決済み] タプルのリストを複数のリストに変換するには?
-
[解決済み] virtualenv の `--no-site-packages` オプションを元に戻す。
-
[解決済み] Pythonでランダムなファイル名を生成する最良の方法
-
[解決済み] Pythonの辞書にあるスレッドセーフについて
-
[解決済み] Pythonでリストが空かどうかをチェックする方法は?重複