[解決済み] Haskellプログラムのパフォーマンス解析ツール
質問
Haskellの勉強のためにProject Euler問題を解いているうちに(だから私は現在全くの初心者です)、次のようなことに出会いました。 問題12 . この(素朴な)解答を書きました。
--Get Number of Divisors of n
numDivs :: Integer -> Integer
numDivs n = toInteger $ length [ x | x<-[2.. ((n `quot` 2)+1)], n `rem` x == 0] + 2
--Generate a List of Triangular Values
triaList :: [Integer]
triaList = [foldr (+) 0 [1..n] | n <- [1..]]
--The same recursive
triaList2 = go 0 1
where go cs n = (cs+n):go (cs+n) (n+1)
--Finds the first triangular Value with more than n Divisors
sol :: Integer -> Integer
sol n = head $ filter (\x -> numDivs(x)>n) triaList2
このソリューションでは
n=500
(sol 500)
は非常に遅いので(もう2時間以上動いています)、この解決策がなぜそんなに遅いのかを調べるにはどうしたらいいかと思いました。私のhaskell-programのどの部分が遅いのかを知るために、計算時間のほとんどがどこに費やされているのかを教えてくれるコマンドはありますか?単純なプロファイラのようなものです。
明確にするために、私は を求めているのではありません。 より速い解決策ではなく 方法 が必要です。もし、あなたがhaskellの知識を持っていなかったら、どのように始めるのですか?
私は2つの
triaList
関数を書いてみましたが、どちらが速いかをテストする方法が見つかりませんでした。
ありがとうございます。
どのように解決するのですか?
<ブロッククオートこの解決方法が遅い理由を知るにはどうしたらよいでしょうか。計算時間の大部分はどこに費やされているのかを教えてくれるコマンドはありますか。
その通りです! GHCは以下のような多くの優れたツールを提供しています。
時間と空間のプロファイリングを使用するためのチュートリアルは Real World Haskellの一部です。 .
GC統計
まず、ghc -O2 でコンパイルしていることを確認してください。そして、最新のGHCであることを確認してください(例:GHC 6.12.x)。
最初にできることは、ガベージコレクションが問題でないことを確認することです。 あなたのプログラムを +RTS -s で実行してください。
$ time ./A +RTS -s
./A +RTS -s
749700
9,961,432,992 bytes allocated in the heap
2,463,072 bytes copied during GC
29,200 bytes maximum residency (1 sample(s))
187,336 bytes maximum slop
**2 MB** total memory in use (0 MB lost due to fragmentation)
Generation 0: 19002 collections, 0 parallel, 0.11s, 0.15s elapsed
Generation 1: 1 collections, 0 parallel, 0.00s, 0.00s elapsed
INIT time 0.00s ( 0.00s elapsed)
MUT time 13.15s ( 13.32s elapsed)
GC time 0.11s ( 0.15s elapsed)
RP time 0.00s ( 0.00s elapsed)
PROF time 0.00s ( 0.00s elapsed)
EXIT time 0.00s ( 0.00s elapsed)
Total time 13.26s ( 13.47s elapsed)
%GC time **0.8%** (1.1% elapsed)
Alloc rate 757,764,753 bytes per MUT second
Productivity 99.2% of total user, 97.6% of total elapsed
./A +RTS -s 13.26s user 0.05s system 98% cpu 13.479 total
これはすでに多くの情報を与えてくれます。2Mのヒープしかなく、GCは0.8%の時間を占有しています。ですから、割り当てが問題であることを心配する必要はありません。
時間プロファイル
プログラムのタイムプロファイルを取得するのは簡単です: -prof -auto-all でコンパイルします。
$ ghc -O2 --make A.hs -prof -auto-all
[1 of 1] Compiling Main ( A.hs, A.o )
Linking A ...
また、N=200の場合は
$ time ./A +RTS -p
749700
./A +RTS -p 13.23s user 0.06s system 98% cpu 13.547 total
を含むファイルA.profを作成します。
Sun Jul 18 10:08 2010 Time and Allocation Profiling Report (Final)
A +RTS -p -RTS
total time = 13.18 secs (659 ticks @ 20 ms)
total alloc = 4,904,116,696 bytes (excludes profiling overheads)
COST CENTRE MODULE %time %alloc
numDivs Main 100.0 100.0
ということを示す すべて を示すもので、すべての割り当てはこの numDivs で行われます。
ヒーププロファイル
RTS -p -hy で実行すると A.hp が作成され、これを PostScript ファイルに変換 (hp2ps -c A.hp) して表示することができ、また生成することによって、これらの割り当ての内訳を得ることができます。
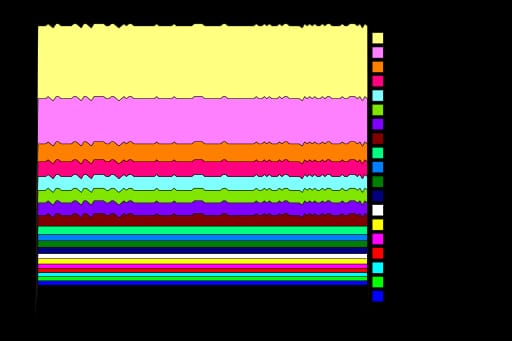
これは、メモリの使用には何も問題がないことを示すもので、一定のスペースで割り当てられています。
つまり、あなたの問題はnumDivsのアルゴリズム的な複雑さです。
toInteger $ length [ x | x<-[2.. ((n `quot` 2)+1)], n `rem` x == 0] + 2
実行時間の100%を占めるこの部分を修正すれば、他のことは簡単です。
最適化
この式は ストリームフュージョン の最適化に適しているので、この式を を使うように書き換えます。 データ.ベクター のようにします。
numDivs n = fromIntegral $
2 + (U.length $
U.filter (\x -> fromIntegral n `rem` x == 0) $
(U.enumFromN 2 ((fromIntegral n `div` 2) + 1) :: U.Vector Int))
これは、不必要なヒープ割り当てのない単一のループに融合されるはずです。つまり、リストバージョンよりも(定数倍)複雑さが改善されます。ghc-core ツール(上級者向け)を使って、最適化後の中間コードを検査することができます。
これをテストするために、ghc -O2 --make Z.hs
$ time ./Z
749700
./Z 3.73s user 0.01s system 99% cpu 3.753 total
つまり、アルゴリズムそのものを変更することなく、N=150の場合の実行時間を3.5倍に短縮したのです。
結論
あなたの問題はnumDivsです。これは実行時間の100%を占め、ひどい複雑さを持っています。
numDivsについて考えてみてください。例えば、各Nについて、[2 ... n]を生成している場合、どのようになるか。
div
2 + 1] を N 回生成しています。
値は変化しないので、それをメモしてみましょう。
どの機能がより速いかを測定するには、次のような方法を考えてみましょう。 基準 を使うことを検討してください。これは、実行時間におけるマイクロ秒以下の改善に関する統計的に堅牢な情報を提供します。
追加事項
numDivsは実行時間の100%を占めるので、他の部分を触ってもあまり変わりません。 しかし、教育的な目的から、ストリームフュージョンでそれらを書き換えることもできます。
trialListも書き換えて、trialList2で手書きしたループをfusionに頼ればいいのです。 これは "prefix scan" 関数 (aka scanl) です。
triaList = U.scanl (+) 0 (U.enumFrom 1 top)
where
top = 10^6
solについても同様です。
sol :: Int -> Int
sol n = U.head $ U.filter (\x -> numDivs x > n) triaList
全体の実行時間は同じですが、コードは少しきれいになっています。
関連
-
[解決済み] 機能における非網羅的なパターン【重複あり
-
[解決済み] Haskell Preludeの'const'は何のためにあるのか?
-
[解決済み] SQLiteのINSERT/per-secondのパフォーマンスを向上させる
-
[解決済み] 0.1fを0にすると、なぜ10倍もパフォーマンスが落ちるのですか?
-
[解決済み] Swift Betaのパフォーマンス:配列のソート
-
[解決済み] Project Eulerとの速度比較。CとPythonとErlangとHaskellの比較
-
[解決済み] Intel CPU の _mm_popcnt_u64 で、32 ビットのループカウンターを 64 ビットに置き換えると、パフォーマンスが著しく低下します。
-
[解決済み] GHCiの複数行コマンド
-
[解決済み】Haskellの入門編
-
[解決済み] Haskellの「何もしない」関数、idはなぜ大量のメモリを消費するのか?
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み] Haskellは実世界で何に使われているのか?[クローズド]
-
[解決済み] Haskellにはなぜ "data "と "newtype "があるのですか?重複] [重複] [重複
-
[解決済み] 制約条件付き特殊化
-
[解決済み] Haskellのリストを参照する際の「@」記号の意味は?
-
[解決済み] GHCはなぜこんなに大きいのか/大きいのか?
-
[解決済み] Haskellの初心者向けガイド?[終了しました]
-
[解決済み] Haskellのガードとif-then-elseとcaseの比較
-
[解決済み] リストからn番目の要素を得るには?
-
[解決済み] <*>は何と呼ばれ、何をするのですか?[クローズド]
-
[解決済み] Haskellのprintfはどのように動作するのですか?