[解決済み] HashPartitionerはどのように機能するのですか?
質問
のドキュメントを読みました。
HashPartitioner
. 残念ながら、APIコール以外はあまり説明がありませんでした。私が想定しているのは
HashPartitioner
はキーのハッシュに基づいて分散セットを分割すると仮定しています。例えば、私のデータが以下のようなものである場合
(1,1), (1,2), (1,3), (2,1), (2,2), (2,3)
つまり、partitionerはこれを同じキーが同じパーティションに該当する異なるパーティションに入れることになります。しかし、私はコンストラクタの引数の意味がわかりません。
new HashPartitoner(numPartitions) //What does numPartitions do?
上記のデータセットについて、以下のようにすると結果はどのように変わるでしょうか?
new HashPartitoner(1)
new HashPartitoner(2)
new HashPartitoner(10)
では、どのようにして
HashPartitioner
は実際にどのように機能するのでしょうか?
どのように解決するのですか?
さて、あなたのデータセットをもう少し面白くしましょう。
val rdd = sc.parallelize(for {
x <- 1 to 3
y <- 1 to 2
} yield (x, None), 8)
6つの要素を持っています。
rdd.count
Long = 6
パーティショナーなし。
rdd.partitioner
Option[org.apache.spark.Partitioner] = None
と8つのパーティションがあります。
rdd.partitions.length
Int = 8
では、パーティションごとの要素数を数えるための小さなヘルパーを定義しましょう。
import org.apache.spark.rdd.RDD
def countByPartition(rdd: RDD[(Int, None.type)]) = {
rdd.mapPartitions(iter => Iterator(iter.length))
}
パーティション分割を行わないので、データセットはパーティション間で一様に分散されます ( Sparkのデフォルトパーティショニングスキーム ):
countByPartition(rdd).collect()
Array[Int] = Array(0, 1, 1, 1, 0, 1, 1, 1)

では、データセットを再分割してみましょう。
import org.apache.spark.HashPartitioner
val rddOneP = rdd.partitionBy(new HashPartitioner(1))
に渡されるパラメータは
HashPartitioner
はパーティションの数を定義しているので、1つのパーティションを想定しています。
rddOneP.partitions.length
Int = 1
パーティションは1つだけなので、すべての要素を含んでいます。
countByPartition(rddOneP).collect
Array[Int] = Array(6)
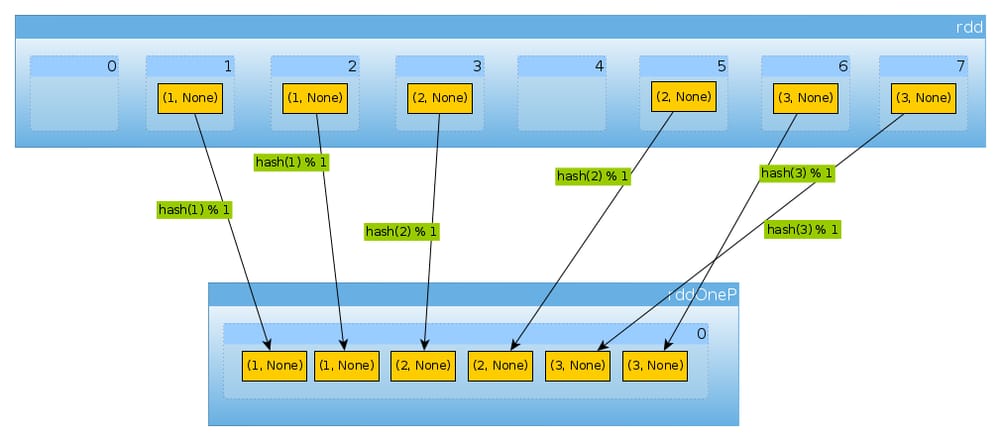
シャッフル後の値の順序は非決定的であることに注意してください。
同じように
HashPartitioner(2)
val rddTwoP = rdd.partitionBy(new HashPartitioner(2))
で、2つのパーティションができます。
rddTwoP.partitions.length
Int = 2
以降
rdd
はキーで分割されるため、データは一様に分散されなくなります。
countByPartition(rddTwoP).collect()
Array[Int] = Array(2, 4)
のキーは3つで、値は2つしかないので
hashCode
mod
numPartitions
は、何も予想外のことはありません。
(1 to 3).map((k: Int) => (k, k.hashCode, k.hashCode % 2))
scala.collection.immutable.IndexedSeq[(Int, Int, Int)] = Vector((1,1,1), (2,2,0), (3,3,1))
上記を確認するために
rddTwoP.mapPartitions(iter => Iterator(iter.map(_._1).toSet)).collect()
Array[scala.collection.immutable.Set[Int]] = Array(Set(2), Set(1, 3))
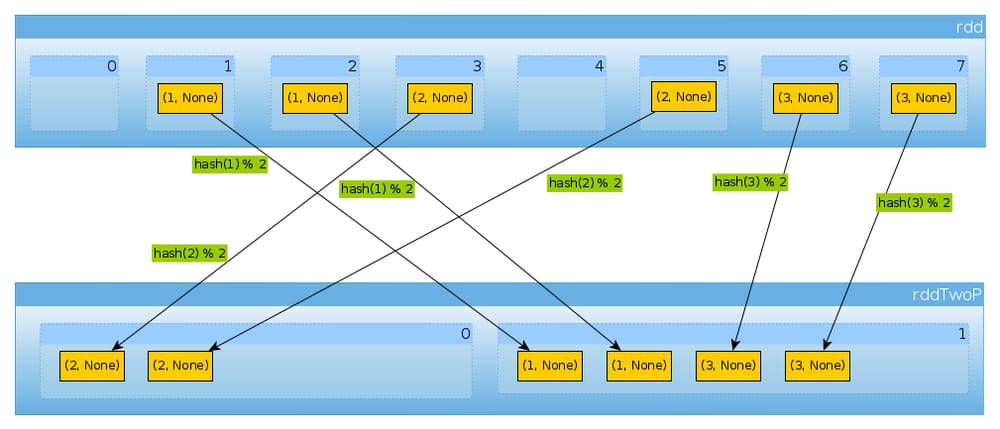
最後に
HashPartitioner(7)
を使うと、7つのパーティションが得られます。
val rddSevenP = rdd.partitionBy(new HashPartitioner(7))
rddSevenP.partitions.length
Int = 7
countByPartition(rddTenP).collect()
Array[Int] = Array(0, 2, 2, 2, 0, 0, 0)
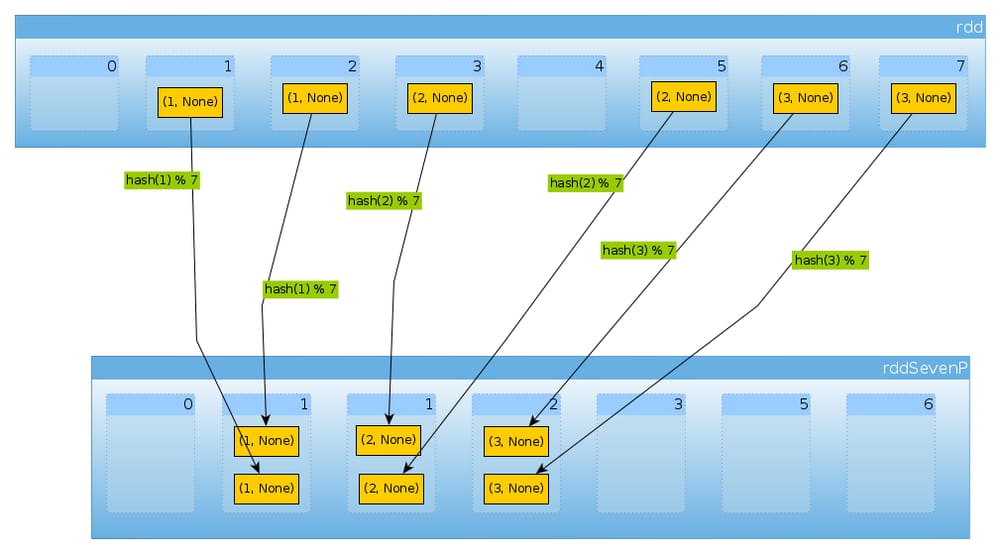
概要と注意事項
-
HashPartitionerは、パーティション数を定義する単一の引数を取ります。 -
の値がパーティションに割り当てられます。
hashのキーを使用します。hashの関数は言語によって異なる場合があります(Scala RDDではhashCode,DataSetsMurmurHash 3、PySparkを使用します。portable_hash).このような単純なケースで、キーが小さな整数である場合、次のように仮定することができます。
hashは同一性である (i = hash(i)).Scala APIでは
nonNegativeModを使って、計算されたハッシュに基づいてパーティションを決定します。 -
キーの分布が均一でない場合、クラスタの一部がアイドル状態になってしまうことがあります。
-
キーはハッシュ化可能でなければなりません。に対する私の回答を確認することができます。 PySparkのreduceByKeyのキーとしてのリスト に対する私の回答で、PySpark固有の問題について読むことができます。もう一つの可能性のある問題は HashPartitionerのドキュメント :
Java の配列は、その内容ではなく配列の ID に基づいた hashCode を持つため、RDD[Array[]を分割しようとすると ]]] または RDD[(Array[ ], _)] を分割しようとすると、予期しない、または不正確な結果を生成します。
-
Python 3 では、ハッシュが一貫していることを確認する必要があります。参照 Exceptionとは何ですか?Randomness of hash of string should be disabled via PYTHONHASHSEED は pyspark でどういう意味ですか?
-
ハッシュパーティショナーは帰納的でも帰納的でもない。複数のキーを1つのパーティションに割り当てることができ、いくつかのパーティションは空のままであることができます。
-
現在、ハッシュベースのメソッドは、REPLで定義されたケースクラスと組み合わせた場合、Scalaでは動作しないことに注意してください ( Apache Sparkにおけるcaseクラスの等価性 ).
-
HashPartitioner(または他のPartitioner) はデータをシャッフルします。パーティショニングが複数のオペレーションで再利用されない限り、シャッフルされるデータ量を減らすことはできません。
関連
-
[解決済み] IntelliJ IDEAで依存関係が変更された後、build.sbtから強制的に再ロードするには?
-
[解決済み] Scalaのリストを作成するための好ましい方法
-
[解決済み] HDFSではなく、ローカルファイルをsc.textFileで読み込む方法
-
[解決済み] Scalaのcaseクラスを宣言することのデメリットは何ですか?
-
[解決済み] scala で複数の case class をマッチングさせる
-
[解決済み] Scalaで2つ以上のリストをまとめてzipで圧縮することはできますか?
-
[解決済み] sbtのヒープサイズを設定するには?
-
[解決済み] Scala Mapのキーと値の両方をマッピングする
-
[解決済み] Scalaで関数を定義する3つの方法の違い
-
[解決済み] Scalaで複数の値をパターンマッチさせるには?
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み] ネストした構造体をよりきれいに更新する方法
-
[解決済み] Scalaのリストを作成するための好ましい方法
-
[解決済み] sbtとGradleの比較 [終了しました]。
-
[解決済み] Scalaでリストを2つのフィールドでソートするには?
-
[解決済み] Scalaでimmutable.Mapをmutable.Mapに変換するにはどうしたらいいですか?
-
[解決済み] タイプダイナミックの仕組みと使い方を教えてください。
-
[解決済み] 同じ要素をn回含むリストを作るには?
-
[解決済み] scalaでサブディレクトリ内の全ファイルをリストアップするには?
-
[解決済み] Scalaで関数を定義する3つの方法の違い
-
[解決済み] 複数の先物を待つには?