Groovyの使い方を完全解説
http://blog.csdn.net/zhaoyanjun6/article/details/70313790
この記事は
[趙燕軍ブログ】をご覧ください。]
記事の目次
コンセプト
GroovyはJavaに似た動的言語(Javaからのステップアップのようなもので、スクリプト言語の特徴を持つ)であり、Java仮想マシン上で動作する。Groovyスクリプトを実行すると、まずJavaクラスのバイトコードにコンパイルされ、次にJavaバイトコードクラスがJVM仮想マシンを通して実行されます。
Groovyの設定環境変数
-
Groovyのウェブサイトからアーカイブをダウンロードする http://www.groovy-lang.org/download.html
-
その後、このようにローカルで解凍してください。
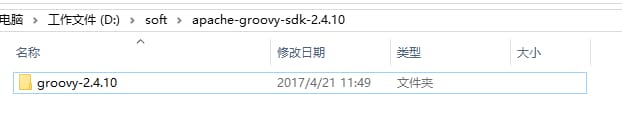
-
で
Path環境変数にGroovyのbinディレクトリへのパスを指定します。
D:\soft\apache-groovy-sdk-2.4.10\groovy-2.4.10bin
図に示すように
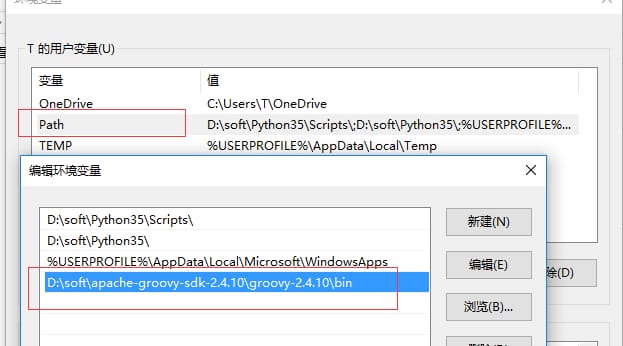
-
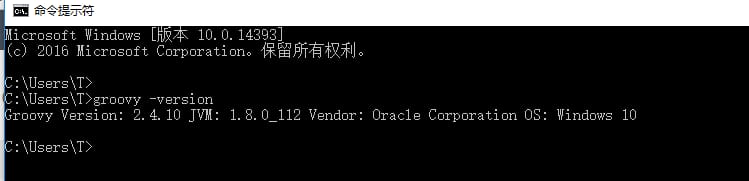
CMDでコマンドラインを開き、実行します。
groovy -versionというプロンプトが表示されれば、設定は成功です。
Groovy Version: 2.4.10 JVM: 1.8.0_112 Vendor: Oracle Corporation OS: Windows 10
画像の通りです。
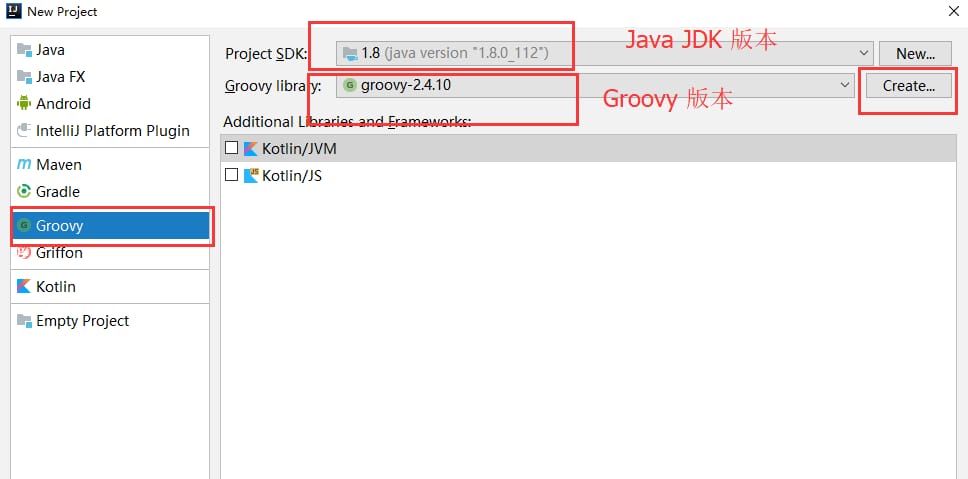
開発ツール IntelliJ IDEA
groovyの開発ツールはIntelliJ IDEAです。
https://www.jetbrains.com/idea/ からダウンロードしてください。
インストール後、新しいプロジェクトを作成し、プロジェクトの種類としてGroovyを選択し、JDK、Groovyのインストールディレクトリを記入します。
新しく作成されたプロジェクトGroovyは以下の通りです。
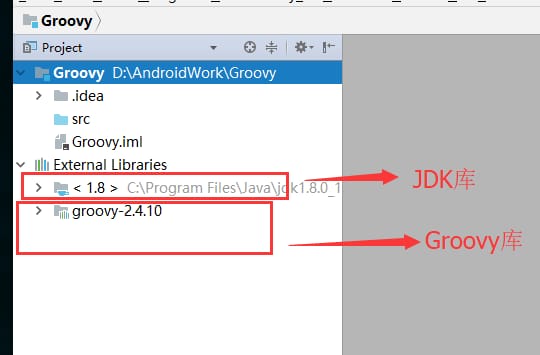
src ディレクトリに、新しいパッケージ名 groovy を作成し、以下のように groovy ソースファイル Test.groovy を作成します。
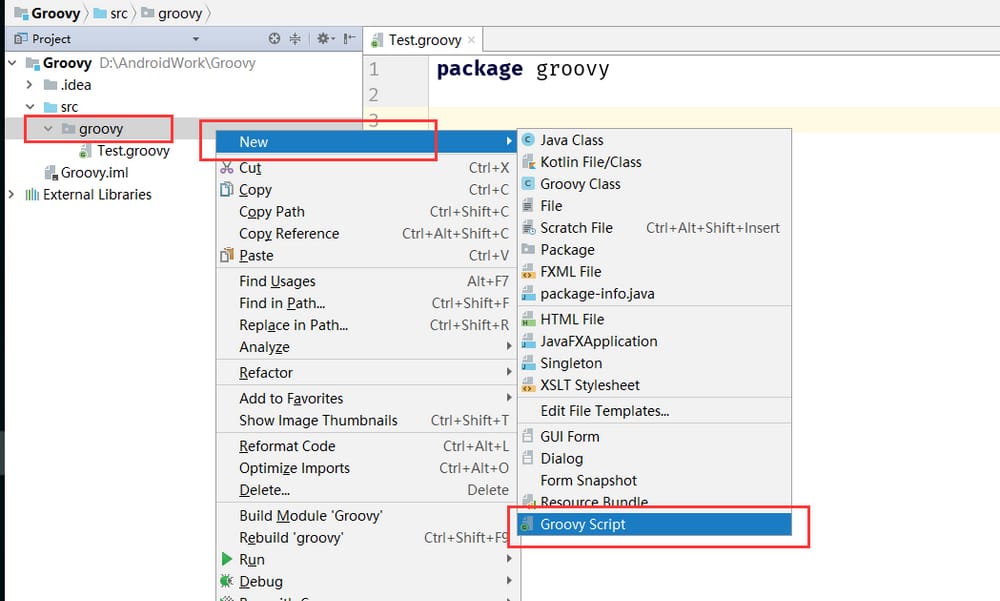
では、Test.groovyに以下のコードでhellowordを出力してみましょう。
package groovy
println( "hello world")
以下のようにTest.groovyファイルを実行します。
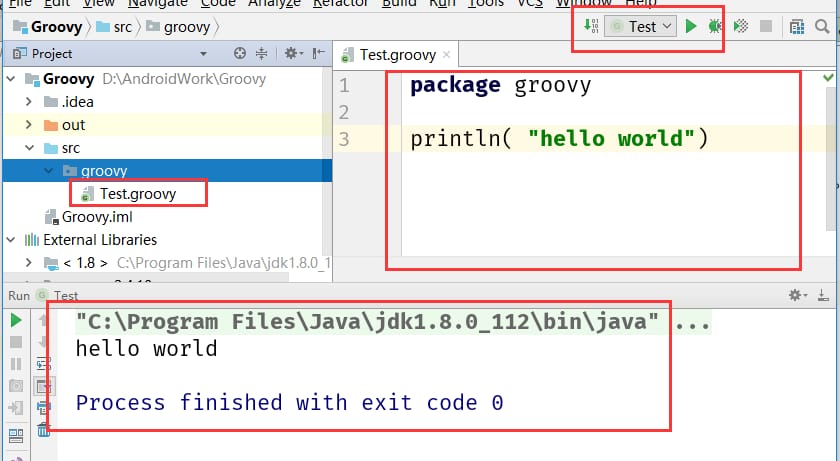
Groovyの構文
基本構文
1. Groovyのアノテーションマークアップは、Javaと同様に、//または/*/をサポートしています。
2. 2. Groovyの文はセミコロンで終わらずに使用でき、Groovyはコード入力を最小限にするために多大な努力を払っています。
3. シングルクォート
シングルクォート '' 内の内容は、Java の String に厳密に対応し、$ 記号をエスケープしない。
def s1 = 'i am 100 $ dolloar'
println( s1 )
結果を実行します。
i am 100 $ dolloar
4. ダブルクォート
二重引用符 ""の内容は、スクリプト言語のような扱いで、もし文字に 記号 の中に 言葉 その では それ 意志 そうすれば <スパン <スパン <スパン <スパン いいえ <スパン の <スパン 単語 <スパン <スパン では それ 意志 式が最初に評価されます。
def x = 100
def s1 = "i am $x dolloar"
println( s1 )
結果を実行します。
i am 100 dolloar
5. トリプルクォート
スリークォートの中の文字列 '''xxx''' はランダムな改行をサポートします。
def s1 = ''' x
y
z
f
'''
println(s1)
実行結果。
x
y
z
f
変数の定義
Groovy は動的型付けをサポートしています。つまり、変数は型を指定せずに定義でき、Groovy では def キーワードを使って変数を定義できます。 def は必須ではありませんが、コードを明確にするために推奨されることに注意してください。
- 変数の定義
def a = 1 //define a shape
def b = "string" //define a string
def double c = 1.0 //define a double type, you can also specify the variable type
関数を定義する
戻り値の型を持たない関数定義にはdefキーワードを使用する必要があり、最後の行の結果はこの関数の戻り値です
// function without reference
def fun1(){
}
//reference function , no need to specify parameter type
def fun2( def1 , def2 ){
}
関数の戻り値の型が指定されている場合、def キーワードを使わずに関数を定義することができます。
String fun3(){
return "return value"
}
実は、いわゆる戻り値のない関数は、内部的にはObject型を返すものとして扱われているのだと思います。結局のところ、GroovyはJavaをベースにしているので、最終的にはJavaコードに変換されてJVM上で実行されることになる .
Groovy の関数は、return xxx を使用せずに、xxx を関数の戻り値として設定することができます。return 文を使用しない場合、関数内の最後の行のコードの結果が戻り値に設定されます。
def getSomething(){
"getSomething return value" //if this is the last line of code, then return type is String
1000 //If this is the last line of code, the return type is Integer
}
コードの各行にセミコロンを追加しないことに加えて、Groovy の関数呼び出しは括弧なしで行うことができます
例1.
def s1 = "123"
println(s1)
//or
println s1
例2.
println(fun1())
println fun1()
def fun1(){
"Hello"
}
効果
Hello
Hello
アサーション Assert
- アサート変数が空である
def s1 = null
assert s1
その効果は次の通りです。
[外部リンクの画像ダンプに失敗しました、ソースサイトは盗難防止チェーン機構を持っているかもしれません、それは直接アップロード(img-YixwoPo6-1609157395410)画像を保存することをお勧めします( https://img-blog.csdn.net/20170915162248368?watermark/2/text/ aHR0cDovL2Jsb2cuY3Nkbi5uZXQvemhhb3lhbmp1bjY=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast)] をご覧ください。
- アサーション変数の長さ
def s2 = "abc"
assert s2.size()>3
その効果は次の通りです。

アサーションが発生した場合、アサーションに続くコードは実行できない
のループ
- 方法I
for (i = 0; i < 5 ; i++) {
println("test")
}
1. 結果を実行します。5つのテストを出力する
2. groovyの構文では、iの前にint型を指定する必要がないことに注意してください。
- 方法2
for (i in 0..5){
println("hello world")
}
これもループですが、出力は6個です。
hello world
5を出力したい場合は、3つの方法があります。
第一の方法
for (i in 0.. <5){
println("hello world")
}
第二の方法
for (i in 0..4){
println("hello world")
}
第3の方法
for (i in 1..5){
println("hello world")
}
ループ時間
timesは、ループが0から始まり、4で終わることを意味します。
4.times {
println it
}
結果
0
1
2
3
三項演算子
Java の構文
def name
def result = name ! = null ? name : "abc"
println(result)
groovy 構文
def name = 'd'
def result = name?: "abc"
例外をキャッチする
すべての例外をキャッチする、2つの方法で書かれています。
// first way to write, Java write
try {
println 5 / 0
} catch (Exception e) {
}
//second way, Groovy writing
try {
println 5 / 0
} catch (anything) {
}
ここでいうAnyにはThrowableは含まれないので、本当にすべてをキャッチしたい場合は、Throwableをキャッチすることを明示的にマークする必要があります。
スイッチ
age = 36
def rate
switch (age) {
case 10..26:
rate = 0.05
break
case 27..36:
rate = 0.06
break
case 37..46:
rate = 0.07
break
default:
throw new IllegalArgumentException()
}
println( rate)
真偽を判定する
Person person
//Java write
if (person!= null){
if (person.Data!=null){
println person.Data.name
}
}
//Groovy
println person?.Data?.name
asType
asTypeはデータ型変換
//String to int
def s2 = s1 as int
//String to int
def s3 = s1.asType(Integer)
Groovyのデータ型
Groovyのデータ型は主に2種類あります。
-
1つは、Javaの基本的なデータ型です。
-
もうひとつは、Groovyにおけるコンテナクラスです。
-
最後にとても重要なのがクロージャです。
Java基本型
def boolean s1 = true
def int s2 = 100
def String s3 = "hello world"
if (s1) {
println("hello world")
}
Groovyコンテナ
リスト。リンクされたリストで、その基本的な対応物はJavaのListインターフェースであり、一般的にはArrayListを実際の実装クラスとして使用する。
マップ。Key-Value型のテーブルで、JavaのLinkedHashMapに相当する部分を基盤としている。
レンジ。Rangeは、実はListの拡張版です。
- リスト
//variable definition: List variables are defined by [] and their elements can be any object
def aList = [5,'string',false]
println(aList)
println aList[0] // get the 1st data
println aList[1] //Get the 2nd data
println aList[2] //Get the 3rd data
println aList[3] //Get the 4th data
println( "set length: " + aList.size())
//assign a value
aList[10] = 100 //assign a value to the 10th value
aList<<10 //add data to the aList
println aList
println "Set length:" + aList.size()
その効果は次の通りです。
[5, string, false]
5
string
false
null
Set length: 3
[5, string, false, null, null, null, null, null, null, null, null, 100]
Set length: 11
- 地図
def map = [key1: "value1", key2: "value2", key3: "value3"]
println map
//[key1:value1, key2:value2, key3:value3]
println("data length: " + map.size())
//data length: 3
println(map.keySet())
//[key1, key2, key3]
println(map.values())
//[value1, value2, value3]
println("value of key1: " + map.key1)
//value of key1: value1
println("value of key1: " + map.get("key1"))
//value of key1: value1
//assign a value
map.put("key4", "value4")
Iterator it = map.iterator()
while (it.hasNext()) {
println "traversing map: " + it.next()
}
//traversing map: key1=value1
//traversing map: key2=value2
//traversing map: key3=value3
//traversing map: key4=value4
map.containsKey("key1") // determine if the map contains a key
map.containsValue("values1") // determine if the map contains a values
map.clear() //clear the contents of the map
Set set = map.keySet(); //convert the key value of map to set
- 範囲
RangeはGroovyをListに拡張したものです。
def range = 1..5
println(range)
//[1, 2, 3, 4, 5]
range.size() // length
range.iterator() // iterator
def s1 = range.get(1) //Get the element labeled 1
range.contains( 5) // whether it contains element 5
range.last() //last element
range.remove(1) // remove the element marked with 1
range.clear() //clear the list
例2.
def range = 1..5
println(range)
//[1, 2, 3, 4, 5]
println("First data: "+range.from) //first data
//first data: 1
println("Last data: "+range.to) //last data
//last data: 5
クロージャ
クロージャ(Closure)は、Groovyでは非常に重要なデータ型、概念である。クロージャは実行可能なコードの断片を表すデータ型です。
def aClosure = {// A closure is a piece of code, so it needs to be enclosed in parentheses...
String param1, int param2 -> //This arrow is critical. In front of the arrow is the parameter definition, and after the arrow is the code
println"this is code" //This is the code, and the last sentence is the return value.
//You can also use return, the same as the normal function in Groovy
}
つまり、Closureは次のような形式で定義される。
def xxx = {paramters -> code}
//or
def xxx = {no parameters, pure code}
正直なところ、C/C++言語の観点からすると、クロージャは関数ポインタとよく似ている。クロージャが定義されると、それを呼び出すためのメソッドは
クロージャ object.call(引数)
というか、関数ポインタ呼び出しのようなものです。
クロージャオブジェクト(パラメータ)
例えば
aClosure.call("this is string",100)
//or
aClosure("this is string", 100)
次のソースコードによるチュートリアルの例
def fun1 = {
p1 ->
def s = "I am a closure," + p1
}
println(fun1.call()) //closure call method 1
println(fun1.call("I am a parameter")) //closure Calling method 2
println(fun1("I am a parameter2"))
実行結果は次のようになります。
I am a closure,null
I am a closure, I am a parameter
I am a closure, I am a parameter2
クロージャが引数を定義しない場合、暗黙のうちにitという名前の引数を持ちます。これはthisの役割と似ています。
def fun2 = {
it-> "dsdsd"
}
println( fun2.call())
もしクロージャがこのような書き方で定義されていたら、それはクロージャに引数がないことを意味します!
def fun3 = {
-> "dsdsd"
}
println( fun3.call())
fun3 を呼び出すときに引数を渡すと、次のようなエラーが発生します。
fun3.call("d") // Error will be reported when executing this method
括弧を省く
def list = [1,2,3] //define a list
// call it each, the format of this code is confusing, isn't it, each is a function, where did the parentheses go?
list.each {
println(it)
}
//result
/**
* 1
* 2
* 3
*/
各関数呼び出しから括弧が消えています! Groovyでは、関数の最後の引数がクロージャである場合、括弧を省略できることがわかりました。例えば
def fun(int a1,String b1, Closure closure){
//dosomething
closure() //call the closure
}
すると、呼び出しは括弧のないものになります
fun (4, "test", {
println"i am in closure"
})
この機能は非常に重要であることに注意してください。
task hello{
doLast{
println("hello world")
}
}
しかし、括弧を省略すると、コードがきれいになり、よりスクリプト言語のように見えます。
Java の属性
Groovyでは、Javaのようにパッケージを記述して、クラスを記述することが可能です。例えば、Person.groovyファイルに以下のようにJavaのコードを記述します。
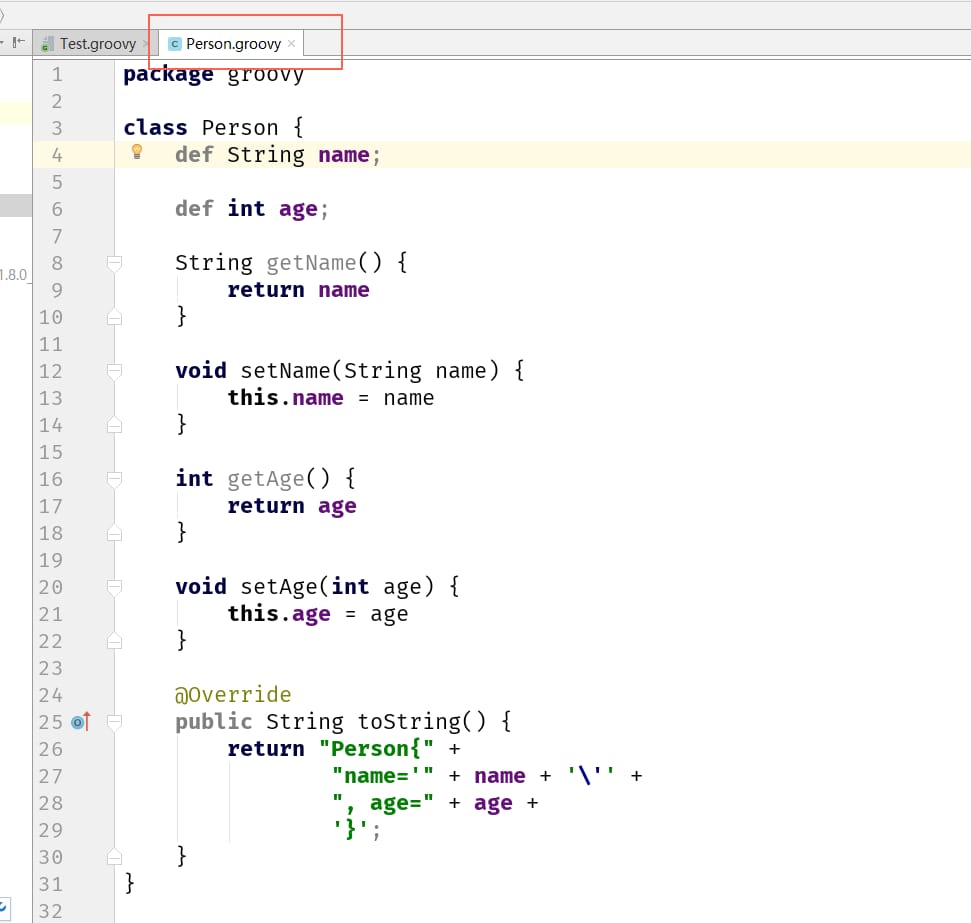
次に、Test.groovyクラスを新規に作成し、以下のようにテストプロジェクトを記述します。
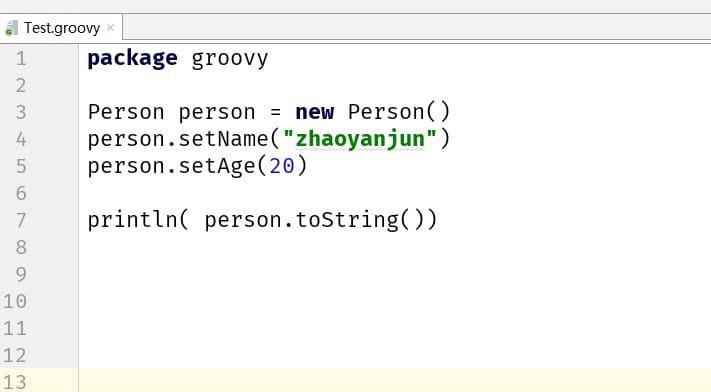
実行結果は以下の通りです。
Person{name='zhaoyanjun', age=20}
もちろん、Groovyではクラスとその変数は、public/privateアクセスを宣言しなければ、デフォルトでpublicです。
再びGroovyを知る
Javaでは、クラスが最も身近な存在です。しかし、Javaではクラス(インターフェースとか...)を書かずにソースファイルを書くことはできません。Groovyでは、xxx.groovyにやることをすべてスクリプトのように書いて、groovy xxx.groovy から直接このスクリプトを実行することが可能です。これは一体どうなっているのでしょうか?
Javaベースなので、Groovyはまずxxx.groovyに書かれていることをJavaのクラスに変換します。
Test.groovyを実行すると、次の画像のように、Person.groovyとTest.groovyが.classファイルに変換されたことが確認できるoutディレクトリが見つかります。
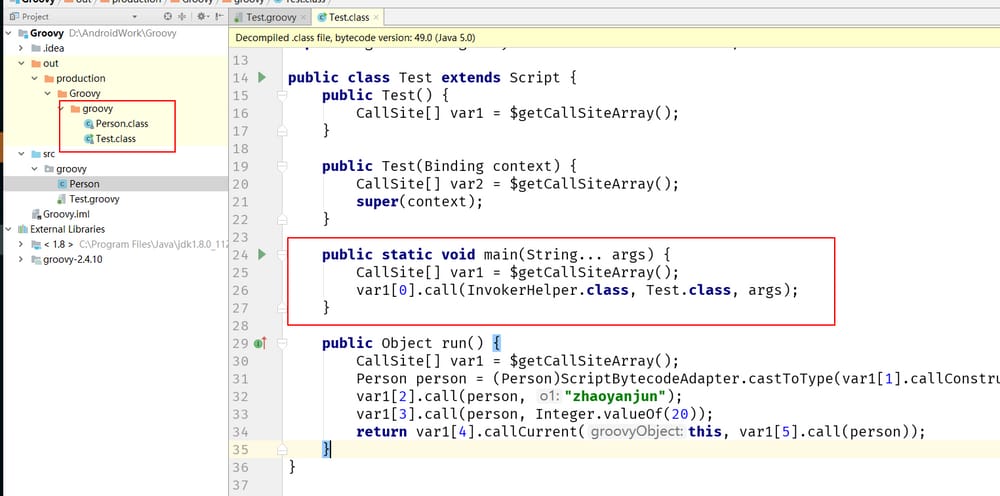
-
コンパイルの後、.groovy ファイルはすべて .class ファイルに変換され、各 .class ファイルはデフォルトで静的なメインメソッドを持ちます。各スクリプトは静的なmain関数を生成します。ですから、 groovytest.groovy を実行するとき、実際にはこの main 関数を実行するために java を使っているのです。
-
スクリプトのコードはすべてrun関数に入れられる。例えば、println 'Groovy world'のコードは、実はrun関数の中に含まれている。
-
Test は Script クラスを継承しています。
スクリプトクラス
groovy library ファイルを見ると、Script クラスが GroovyObjectSupport クラスを継承した抽象クラスであることが、以下のように確認できます。
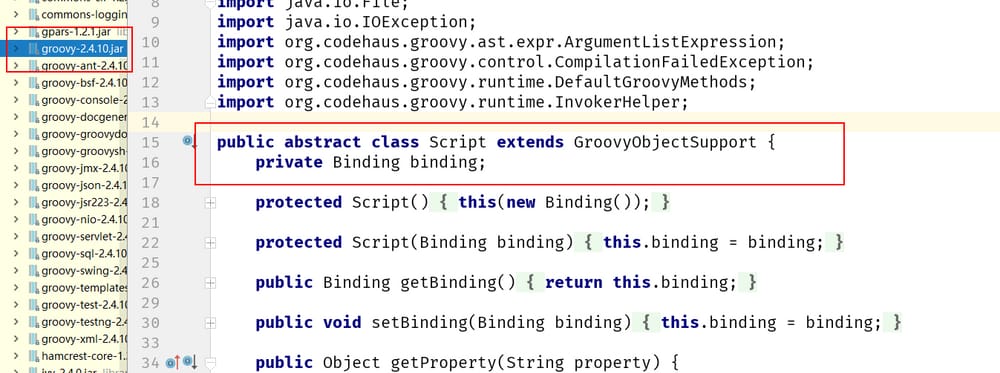
スクリプト変数のスコープ
Test.groovyの内部で変数s1、メソッドfun1を定義し、さらに以下のコードでfun1メソッドにs1を出力します。
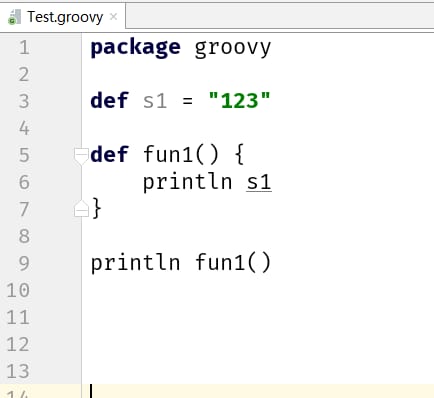
実行するとすぐに、次のようなエラーが報告されます。

outディレクトリで、以下のようにTest.classクラスを見てください。
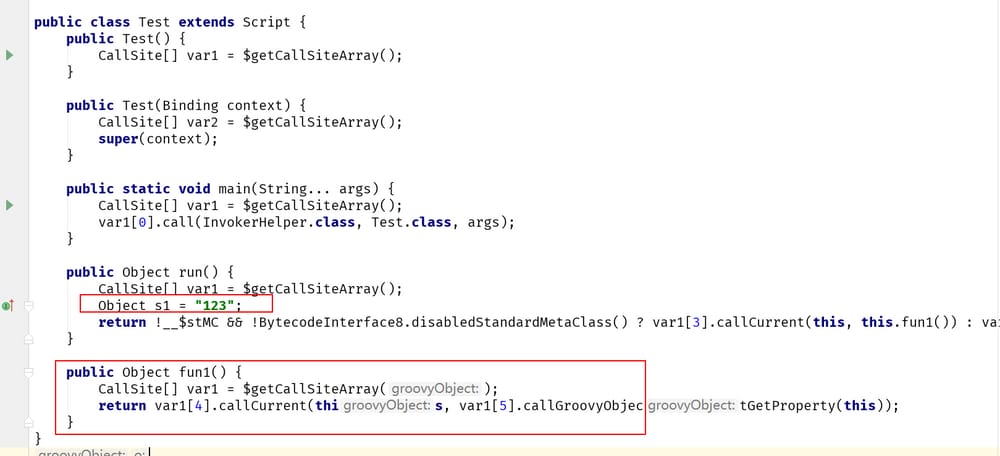
変数 s1 は run メソッドで定義されており、これはローカル変数に相当するので、当然 fun1 メソッドは s1 にアクセスできないことがわかります。
解決方法は簡単で、s1からdefを取り除くと、以下のようなコードになります。
outディレクトリで、以下のようにTest.classクラスを見てください。
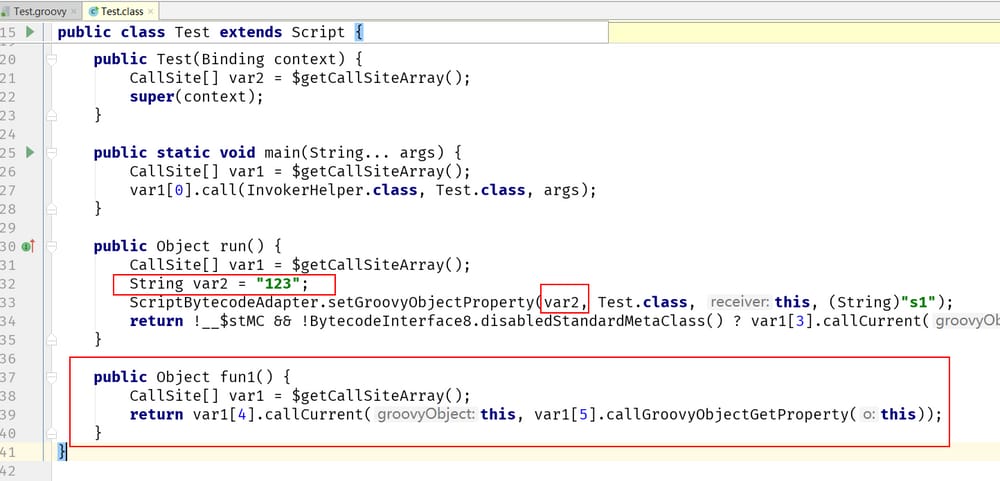
上図では、s1もTestのメンバ関数として定義されているのではなく、runの実行時にTestインスタンスオブジェクトにプロパティとして追加されています。そして、print s1では、このプロパティが最初に取得されます。しかし、デコンパイルしたところ、s1 は Test.class のメンバ変数にはならず、他のスクリプトは s1 変数にアクセスすることができません。
どうすればs1をきっぱりとTestのメンバ変数にできるのでしょうか?
答えも簡単で、s1 に @Field フィールドをプレフィックスとして付けるだけです。
@Field s1 = "123" //s1 becomes a member variable of Test completely
デコンパイルは次のように動作します。

JSON操作
JsonOutputクラスは、オブジェクトをjson文字列に変換するクラスです。
JsonSlurperクラスは、json文字列をオブジェクトに変換するクラスです。
Personエンティティクラスの定義
public class Person {
String name;
int age;
}
オブジェクトをjsonに、jsonをオブジェクトに
Person person = new Person();
person.name = "zhaoyanjun"
person.age = 27
// Convert the object to a json string
def json =JsonOutput.toJson(person)
println(json)
JsonSlurper jsonSlurper = new JsonSlurper()
//convert a string to an object
Person person1 = jsonSlurper.parseText(json)
println( person1.name )
以下のように実行されます。
{"age":27,"name":"zhaoyanjun"}
zhaoyanjun
コレクションオブジェクトからjsonへ、jsonからコレクションオブジェクトへ
Person person = new Person();
person.name = "zhaoyanjun"
person.age = 27
Person person1 = new Person();
person1.name = "zhaoyanjun2"
person1.age = 28
def list = [person,person1]
//convert collection objects to json strings
def jsonArray = JsonOutput.toJson(list)
println(jsonArray)
JsonSlurper jsonSlurper = new JsonSlurper()
// Convert a string to a collection object
List
実行した結果は
[{"age":27,"name":"zhaoyanjun"},{"age":28,"name":"zhaoyanjun2"}]
zhaoyanjun2
I/O操作
GroovyのI/O操作は、オリジナルのJavaのI/O操作をよりシンプルで便利にしたラッパーで、クロージャを使ってコードの記述を簡素化しています。Javaよりもシンプルに見えますが、実は理解するのが難しいのです。
テキストファイルの読み込み
以下の内容のテキストファイル、test.txtをコンピュータに新規作成します。
Today is Friday
The weather is beautiful.
Tomorrow will be a holiday
groovyで中のテキストを読み取る方法は以下の通りです。
def filePath = "C:/Users/T/Desktop/test.txt"
def file = new File(filePath) ;
file.eachLine {
println it
}
その通りです。groovyのファイル読み込み操作は、とんでもなくシンプルです。しかし、それだけでは不十分で、もっととんでもない操作があります。
def filePath = "C:/Users/T/Desktop/test.txt"
def file = new File(filePath) ;
println file.text //output text
ここを見てください!GroovyはJavaの100倍もファイル操作が簡単なんです!!!!!!!!!!!!!!!!!!!!!!!!!!!!!(笑
その他の用途
- エンコード形式を指定する
def filePath = "C:/Users/T/Desktop/test.txt"
def file = new File(filePath);
//specify the encoding format as utf-8
file.eachLine("utf-8") {
println it //read the text
}
- 小文字を大文字に変換する
def filePath = "C:/Users/T/Desktop/test.txt"
def file = new File(filePath);
file.eachLine {
println( it.toUpperCase() )
}
テキストファイルの書き込み
- ウェイ1
def filePath = "C:/Users/T/Desktop/test.txt"
def file = new File(filePath);
file.withPrintWriter {
it.println("test")
it.println("hello world")
}
- モード2
def filePath = "C:/Users/T/Desktop/test.txt"
def file = new File(filePath);
def out = file.newPrintWriter();
out.println("test")
out.println("hello world")
out.flush()
out.close()
その効果は次の通りです。

フォルダ操作
- フォルダ内のファイル、ドキュメントを繰り返し処理する。
def filePath = "C:/Users/T/Desktop/123"
def file = new File(filePath);
// iterate through the folders in the 123 folder
file.eachDir {
println "Folder:"+it.name
}
//Iterate through the files in folder 123
file.eachFile {
println "file:"+ it.name
}
その効果は次の通りです。
Folder: 1
Folder: 2
Folder: 3
File: 1
File: 2
File: 3
File: 4.txt
ドキュメントのディープトラバーサル
def filePath = "e:/"
def file = new File(filePath);
//deep traversal of the directory, i.e. traversal of the directories in the directory
file.eachDirRecurse {
println it.name
}
//deep traversal of files, including directories and files
file.eachFileRecurse {
println it.path
}
入力ストリーム
def filePath = "C:/Users/T/Desktop/test.txt"
def file = new File(filePath) ;
def ism = file.newInputStream()
//Operate ism, remember to close it at the end
ism.close
クロージャを使ってinputStreamを操作する、これは今後Gradleでよく見ることになる
def filePath = "C:/Users/T/Desktop/test.txt"
def file = new File(filePath) ;
file.withInputStream {ism->
// Groovy will automatically close it for you
ism.eachLine {
println it // read the text
}
}
とんでもなくシンプルなんです。昔はwithInputStreamの意味がわからなかったんだけどね。というわけで、開発者の皆さん、GroovyのI/O操作関連クラスのSDKアドレスは覚えておいてくださいね。
- java.io.File:http://docs.groovy-lang.org/latest/html/groovy-jdk/java/io/File.html。
- java.io.InputStream: http://docs.groovy-lang.org/latest/html/groovy-jdk/java/io/InputStream.html
- java.io.OutputStream: http://docs.groovy-lang.org/latest/html/groovy-jdk/java/io/OutputStream.html
- java.io. リーダー: http://docs.groovy-lang.org/latest/html/groovy-jdk/java/io/Reader.html
- java.io.Writer: http://docs.groovy-lang.org/latest/html/groovy-jdk/java/io/Writer.html
- java.nio.file.Path: http://docs.groovy-lang.org/latest/html/groovy-jdk/java/nio/file/Path.html
xmlパース
javaでxmlを解析するのは非常に面倒で、通常5行のxmlファイルを解析するのに10行のコードが必要であり、非常に不経済である。groovyでxmlを解析するのはとても便利です。
例1 簡単なxmlのパース
例えば、次のようなxml
<?xml version="1.0"? >
<langs type="current">
//Get the langs node of the xml file
def langs = new XmlParser().parse("C:/Users/T/Desktop/test.xml")
//Get the value of the type field
def type = langs.attribute("type")
println type
langs.language.each{
println it.text()
}
関連
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
ハートビート・エフェクトのためのHTML+CSS
-
HTML ホテル フォームによるフィルタリング
-
HTML+cssのボックスモデル例(円、半円など)「border-radius」使いやすい
-
HTMLテーブルのテーブル分割とマージ(colspan, rowspan)
-
ランダム・ネームドロッパーを実装するためのhtmlサンプルコード
-
Html階層型ボックスシャドウ効果サンプルコード
-
QQの一時的なダイアログボックスをポップアップし、友人を追加せずにオンラインで話す効果を達成する方法
-
sublime / vscodeショートカットHTMLコード生成の実装
-
HTMLページを縮小した後にスクロールバーを表示するサンプルコード
-
html のリストボックス、テキストフィールド、ファイルフィールドのコード例