[解決済み] なぜfactor()ではなく、as.factor()なのか?
質問
最近、Matt Dowleが、あるコードを
as.factor()
具体的には
for (col in names_factors) set(dt, j=col, value=as.factor(dt[[col]]))
で この回答に対するコメント .
このスニペットを使用しましたが、レベルが希望する順序で表示されるようにするために、要因レベルを明示的に設定する必要があったため、以下のように変更する必要がありました。
as.factor(dt[[col]])
になります。
factor(dt[[col]], levels = my_levels)
このことから、私は次のように考えました。
as.factor()
と、単に
factor()
?
解決方法は?
as.factor
のラッパーです。
factor
しかし、入力ベクトルがすでに因子である場合、素早く返すことができる。
function (x)
{
if (is.factor(x))
x
else if (!is.object(x) && is.integer(x)) {
levels <- sort(unique.default(x))
f <- match(x, levels)
levels(f) <- as.character(levels)
if (!is.null(nx <- names(x)))
names(f) <- nx
class(f) <- "factor"
f
}
else factor(x)
}
コメント
フランク
この「クイックリターン」では、ファクターレベルをそのままにしておくことができますので、単なるラッパーではありません。
factor()
ということです。
f = factor("a", levels = c("a", "b"))
#[1] a
#Levels: a b
factor(f)
#[1] a
#Levels: a
as.factor(f)
#[1] a
#Levels: a b
2年後に以下のように回答を拡大。
- マニュアルにはどう書いてある?
-
パフォーマンス
as.factor>factor入力が要因の場合 -
パフォーマンス
as.factor>factor入力が整数の場合 - 未使用レベルまたはNAレベル
- Rのgroup-by関数使用時の注意点:未使用またはNAのレベルに注意
マニュアルに書いてあることは?
のドキュメントは
?factor
は、以下のように言及しています。
‘factor(x, exclude = NULL)’ applied to a factor without ‘NA’s is a
no-operation unless there are unused levels: in that case, a
factor with the reduced level set is returned.
‘as.factor’ coerces its argument to a factor. It is an
abbreviated (sometimes faster) form of ‘factor’.
パフォーマンス
as.factor
>
factor
入力が要因の場合
無操作という言葉は、少し曖昧です。実際には、「多くのことを行うが、本質的には何も変えない」という意味です。以下はその例です。
set.seed(0)
## a randomized long factor with 1e+6 levels, each repeated 10 times
f <- sample(gl(1e+6, 10))
system.time(f1 <- factor(f)) ## default: exclude = NA
# user system elapsed
# 7.640 0.216 7.887
system.time(f2 <- factor(f, exclude = NULL))
# user system elapsed
# 7.764 0.028 7.791
system.time(f3 <- as.factor(f))
# user system elapsed
# 0 0 0
identical(f, f1)
#[1] TRUE
identical(f, f2)
#[1] TRUE
identical(f, f3)
#[1] TRUE
as.factor
はすぐに戻ってきますが
factor
は、本当の意味での"no-op"ではありません。プロファイリングしてみましょう
factor
が何をしたのかを見てみましょう。
Rprof("factor.out")
f1 <- factor(f)
Rprof(NULL)
summaryRprof("factor.out")[c(1, 4)]
#$by.self
# self.time self.pct total.time total.pct
#"factor" 4.70 58.90 7.98 100.00
#"unique.default" 1.30 16.29 4.42 55.39
#"as.character" 1.18 14.79 1.84 23.06
#"as.character.factor" 0.66 8.27 0.66 8.27
#"order" 0.08 1.00 0.08 1.00
#"unique" 0.06 0.75 4.54 56.89
#
#$sampling.time
#[1] 7.98
それはまず
sort
その
unique
の値は、入力ベクトル
f
に変換し、その後に
f
を文字ベクトルに変換し、最後に
factor
を使用して、文字ベクトルを因数に戻すことができます。以下は、そのソースコードです。
factor
を確認します。
function (x = character(), levels, labels = levels, exclude = NA,
ordered = is.ordered(x), nmax = NA)
{
if (is.null(x))
x <- character()
nx <- names(x)
if (missing(levels)) {
y <- unique(x, nmax = nmax)
ind <- sort.list(y)
levels <- unique(as.character(y)[ind])
}
force(ordered)
if (!is.character(x))
x <- as.character(x)
levels <- levels[is.na(match(levels, exclude))]
f <- match(x, levels)
if (!is.null(nx))
names(f) <- nx
nl <- length(labels)
nL <- length(levels)
if (!any(nl == c(1L, nL)))
stop(gettextf("invalid 'labels'; length %d should be 1 or %d",
nl, nL), domain = NA)
levels(f) <- if (nl == nL)
as.character(labels)
else paste0(labels, seq_along(levels))
class(f) <- c(if (ordered) "ordered", "factor")
f
}
そのため、機能
factor
は本当に文字ベクトルを扱うために設計されたものであり、この文字ベクトルに対して
as.character
を入力に加えることで、それを保証しています。以上から、少なくとも2つのパフォーマンスに関する問題を学ぶことができます。
-
データフレームの場合
DF,lapply(DF, as.factor)よりもはるかに高速です。lapply(DF, factor)は、多くのカラムが容易に因子となる場合、型変換に使用されます。 -
その関数
factorが遅いということは、R の重要な関数が遅い理由を説明することができる、例えばtable: R:テーブル関数が意外と遅い
パフォーマンス
as.factor
>
factor
入力が整数の場合
因子変数は、整数変数の近親者である。
unclass(gl(2, 2, labels = letters[1:2]))
#[1] 1 1 2 2
#attr(,"levels")
#[1] "a" "b"
storage.mode(gl(2, 2, labels = letters[1:2]))
#[1] "integer"
これは、整数を係数に変換する方が、数値/文字を係数に変換するよりも簡単であることを意味します。
as.factor
は、ちょうどこの世話をする。
x <- sample.int(1e+6, 1e+7, TRUE)
system.time(as.factor(x))
# user system elapsed
# 4.592 0.252 4.845
system.time(factor(x))
# user system elapsed
# 22.236 0.264 22.659
未使用のレベルまたはNAレベル
では、次の例を見てみましょう。
factor
と
as.factor
の要因レベルへの影響(入力がすでに要因である場合)。
フランク
が未使用の因子レベルを持つものを提供しているので、私が提供するのは
NA
レベルである。
f <- factor(c(1, NA), exclude = NULL)
#[1] 1 <NA>
#Levels: 1 <NA>
as.factor(f)
#[1] 1 <NA>
#Levels: 1 <NA>
factor(f, exclude = NULL)
#[1] 1 <NA>
#Levels: 1 <NA>
factor(f)
#[1] 1 <NA>
#Levels: 1
汎用)関数があります。
droplevels
これは、ある因子の未使用レベルを削除するために使用することができます。しかし
NA
のレベルはデフォルトでは落とせません。
## "factor" method of `droplevels`
droplevels.factor
#function (x, exclude = if (anyNA(levels(x))) NULL else NA, ...)
#factor(x, exclude = exclude)
droplevels(f)
#[1] 1 <NA>
#Levels: 1 <NA>
droplevels(f, exclude = NA)
#[1] 1 <NA>
#Levels: 1
Rのgroup-by関数を使用する際の注意:未使用またはNAのレベルに注意
グループバイ操作を行うR関数、例えば
split
,
tapply
は、因子変数をquot;by"変数として提供することを想定しています。しかし、多くの場合、文字や数値の変数を提供するだけです。そのため、これらの関数は内部でこれらを係数に変換する必要がありますし、おそらくほとんどの関数では、係数に変換するために
as.factor
は、そもそも(少なくとも
split.default
と
tapply
). また
table
関数は例外のように見え、私は
factor
ではなく
as.factor
の中に入っています。何か特別な配慮があるのかもしれませんが、残念ながらそのソースコードを調べても明らかではありません。
ほとんどのグループバイR関数では
as.factor
である場合、未使用の因子または
NA
のレベルでは、そのようなグループが結果に表示されます。
x <- c(1, 2)
f <- factor(letters[1:2], levels = letters[1:3])
split(x, f)
#$a
#[1] 1
#
#$b
#[1] 2
#
#$c
#numeric(0)
tapply(x, f, FUN = mean)
# a b c
# 1 2 NA
興味深いことに
table
には依存しません。
as.factor
そのため、これらの未使用レベルも保存されます。
table(f)
#a b c
#1 1 0
このような動作が好ましくない場合もあります。典型的な例としては
barplot(table(f))
:
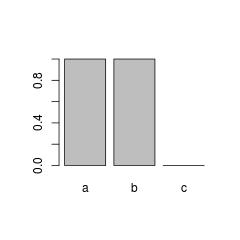
これが本当に望ましくない場合、手動で未使用のまたは
NA
を使用して、因子変数からレベルを削除します。
droplevels
または
factor
.
ヒント
-
splitは、引数dropであり、デフォルトはFALSEしたがってas.factorが使用されます。drop = TRUE機能factorが代わりに使われます。 -
aggregateに依存しています。splitということで、これもまたdropを引数にとり、デフォルトはTRUE. -
tapplyを持ちません。dropにも依存していますがsplit. 特に、ドキュメント?tapplyには次のように書かれています。as.factorが(常に)使用されます。
関連
-
[解決済み】Rでの関数の最適化(L-BFGS-Bでは'fn'に有限の値が必要)。
-
[解決済み】RでKNN。trainとclassは長さが違う」?
-
[解決済み】ロジスティック回帰 - eval(family$initialize) : y 値は 0 <= y <= 1 である必要があります。
-
[解決済み】Rで結果の行数がベクトル長(arg 2)の倍数でない件
-
[解決済み] na.fail.defaultのエラー:オブジェクトの値が見つからない - しかし、値が見つからないことはありません。
-
[解決済み】Rで「中断されたプロミスの評価を再開する」という警告を回避する
-
[解決済み] 情報を損なわずに因数を整数値に変換するには?
-
[解決済み】サブセットされたデータフレーム内の未使用の因子レベルを削除する
-
[解決済み】なぜlapplyの代わりにpurrr::mapを使うのですか?
-
[解決済み] 因子水準と因子ラベルの混同
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み】xtsオブジェクトでエラー: "antempt to set 'colnames' on the object with less than two dimension "を克服する方法
-
[解決済み】数学関数への非数値引数
-
[解決済み】エラー:ベクターメモリの枯渇(制限に達したか) R 3.5.0 macOS
-
[解決済み】ggplotの線幅を変更するには?
-
[解決済み] テスト
-
[解決済み】RでのMLEエラー:'vmmin'の初期値が有限でない
-
[解決済み】ggplot boxplotでPosition-dodge警告?
-
[解決済み】R ggplot2 で scale_x_discrete を使用する。
-
[解決済み】rbind(deparse.level, ...)でエラー:引数の列の数がRにマッチしていない
-
[解決済み】seq_alongはうまくいくが、seqが意図しない結果を生む例とは?