coursera-Capstone Pythonによるデータの取得、処理、可視化(ページランクのための宿題)
2022-02-26 05:13:47
以下は、課題のタイトルです。
ページランク
まず、http://python-data.dr-chuck.net/ から100ページをスパイダーし、ページランキングアルゴリズムを実行し、いくつかのスクリーンショットを撮ります。次に、スパイダー処理をリセットし、インターネット上の他のサイトから100ページをスパイダーし、ページランクアルゴリズムを実行し、いくつかのスクリーンショットを撮ります。
ちょっとしたミスで減点しないこと。課題をこなしたようであれば、全評価を与えてください。ポジティブで有益なコメントを心がけてください。
ソリューションの例
http://www.py4e.com/code3/pagerank.zip
完成が必要です。
1) python-data.dr-chuck.net から100ページクロールした後の spdump.py の実行画面です。
2) python-data.dr-chuck.netからクロールした上位25ページのページランクをforce.htmlで可視化したスクリーンショットです。
3) 他のWebサイトから100ページをクロールした後に実行されるspdump.pyのスクリーンショット
4) 相手Webサイトからクロールしたページランク上位25ページをforce.htmlで可視化したスクリーンショットです。
課題は以下の通りです。
1)
import sqlite3
import urllib.error
import ssl
from urllib.parse import urljoin
from urllib.parse import urlparse
from urllib.request import urlopen
from bs4 import BeautifulSoup
# Ignore SSL certificate errors
ctx = ssl.create_default_context()
ctx.check_hostname = False
ctx.verify_mode = ssl.CERT_NONE
conn = sqlite3.connect('spider.sqlite')
cur = conn.cursor()
cur.execute('''CREATE TABLE IF NOT EXISTS Pages
(id INTEGER PRIMARY KEY, url TEXT UNIQUE, html TEXT,
error INTEGER, old_rank REAL, new_rank REAL)''')
cur.execute('''CREATE TABLE IF NOT EXISTS Links
(from_id INTEGER, to_id INTEGER)''')
cur.execute('''CREATE TABLE IF NOT EXISTS Webs (url TEXT UNIQUE)''')
# Check to see if we are already in progress...
cur.execute('SELECT id,url FROM Pages WHERE html is NULL and error is NULL ORDER BY RANDOM() LIMIT 1')
row = cur.fetchone()
if row is not None:
print("Restarting existing crawl. Remove spider.sqlite to start a fresh crawl.")
else :
starturl = input('Enter web url or enter: ')
if ( len(starturl) < 1 ) : starturl = 'http://www.dr-chuck.com/'
if ( starturl.endswith('/') ) : starturl = starturl[:-1]
web = starturl
if ( starturl.endswith('.htm') or starturl.endswith('.html') ) :
pos = starturl.rfind('/')
web = starturl[:pos]
if ( len(web) > 1 ) :
cur.execute('INSERT OR IGNORE INTO Webs (url) VALUES ( ? )', ( web, ) )
cur.execute('INSERT OR IGNORE INTO Pages (url, html, new_rank) VALUES ( ? , NULL, 1.0 )', ( starturl, ) )
conn.commit()
# Get the current webs
cur.execute('''SELECT url FROM Webs''')
webs = list()
for row in cur:
webs.append(str(row[0]))
print(webs)
many = 0
while True:
if ( many < 1 ) :
sval = input('How many pages:')
if ( len(sval) < 1 ) : break
many = int(sval)
many = many - 1
cur.execute('SELECT id,url FROM Pages WHERE html is NULL and error is NULL ORDER BY RANDOM() LIMIT 1')
try:
row = cur.fetchone()
# print row
fromid = row[0]
url = row[1]
except:
print('No unretrieved HTML pages found')
many = 0
break
print(fromid, url, end=' ')
# If we are retrieving this page, there should be no links from it
cur.execute('DELETE from Links WHERE from_id=?' , (fromid, ) )
try:
document = urlopen(url, context=ctx)
html = document.read()
if document.getcode() ! = 200 :
print("Error on page: ",document.getcode())
cur.execute('UPDATE Pages SET error=? WHERE url=?' , (document.getcode(), url) )
if 'text/html' ! = document.info().get_content_type() :
print("Ignore non text/html page")
cur.execute('DELETE FROM Pages WHERE url=?' , ( url, ) )
cur.execute('UPDATE Pages SET error=0 WHERE url=?' , (url, ) )
conn.commit()
continue
print('('+str(len(html))+')', end=' ')
soup = BeautifulSoup(html, "html.parser")
except KeyboardInterrupt:
print('')
print('Program interrupted by user...')
break
except:
print("Unable to retrieve or parse page")
cur.execute('UPDATE Pages SET error=-1 WHERE url=?' , (url, ) )
conn.commit()
continue
cur.execute('INSERT OR IGNORE INTO Pages (url, html, new_rank) VALUES ( ? , NULL, 1.0 )', ( url, ) )
cur.execute('UPDATE Pages SET html=? WHERE url=?' , (memoryview(html), url ) )
conn.commit()
# Retrieve all of the anchor tags
tags = soup('a')
count = 0
for tag in tags:
href = tag.get('href', None)
if ( href is None ) : continue
# Resolve relative references like href="/contact"
up = urlparse(href)
if ( len(up.scheme) < 1 ) :
href = urljoin(url, href)
ipos = href.find('#')
if ( ipos > 1 ) : href = href[:ipos]
if ( href=.endswith('.png') or href=.endswith('.jpg') or href=.endswith('.gif') ) : continue
if ( href.endswith('/') ) : href = href[:-1]
# print href
if ( len(href) < 1 ) : continue
# Check if the URL is in any of the webs
found = False
for web in webs:
if ( href.startswith(web) ) :
found = True
break
if not found : continue
cur.execute('INSERT OR IGNORE INTO Pages (url, html, new_rank) VALUES ( ? , NULL, 1.0 )', ( href, ) )
count = count + 1
conn.commit()
cur.execute('SELECT id FROM Pages WHERE url=? LIMIT 1', ( href, ))
try:
row = cur.fetchone()
toid = row[0]
except:
print('Could not retrieve id')
continue
# print fromid, toid
cur.execute('INSERT OR IGNORE INTO Links (from_id, to_id) VALUES ( ? , ? )', ( fromid,
import sqlite3
conn = sqlite3.connect('spider.sqlite')
cur = conn.cursor()
cur.execute('''SELECT COUNT(from_id) AS inbound, old_rank, new_rank, id, url
FROM Pages JOIN Links ON Pages.id = Links.to_id
WHERE html IS NOT NULL
GROUP BY id ORDER BY inbound DESC''')
count = 0
for row in cur :
if count < 50 : print(row)
count = count + 1
print(count, 'rows.')
cur.close()
import sqlite3
conn = sqlite3.connect('spider.sqlite')
cur = conn.cursor()
# Find the ids that send out page rank - we only are interested
# in pages in the SCC that have in and out links
cur.execute('''SELECT DISTINCT from_id FROM Links''')
from_ids = list()
for row in cur:
from_ids.append(row[0])
# Find the ids that receive page rank
to_ids = list()
links = list()
cur.execute('''SELECT DISTINCT from_id, to_id FROM Links''')
for row in cur:
from_id = row[0]
to_id = row[1]
if from_id == to_id : continue
if from_id not in from_ids : continue
if to_id not in from_ids : continue
links.append(row)
if to_id not in to_ids : to_ids.append(to_id)
# Get latest page ranks for strongly connected component
prev_ranks = dict()
for node in from_ids:
cur.execute('''SELECT new_rank FROM Pages WHERE id = ?''' , (node, ))
row = cur.fetchone()
prev_ranks[node] = row[0]
sval = input('How many iterations:')
many = 1
if ( len(sval) > 0 ) : many = int(sval)
# Sanity check
if len(prev_ranks) < 1 :
print("Nothing to page rank. Check data.")
quit()
# Lets do Page Rank in memory so it is really fast
for i in range(many):
# print prev_ranks.items()[:5]
next_ranks = dict();
total = 0.0
for (node, old_rank) in list(prev_ranks.items()):
total = total + old_rank
next_ranks[node] = 0.0
# print total
# Find the number of outbound links and sent the page rank down each
for (node, old_rank) in list(prev_ranks.items()):
# print node, old_rank
give_ids = list()
for (from_id, to_id) in links:
if from_id ! = node : continue
# print ' ',from_id,to_id
if to_id not in to_ids: continue
give_ids.append(to_id)
if ( len(give_ids) < 1 ) : continue
amount = old_rank / len(give_ids)
# print node, old_rank,amount, give_ids
for id in give_ids:
next_ranks[id] = next_ranks[id] + amount
newtot = 0
for (node, next_rank) in list(next_ranks.items()):
newtot = newtot + next_rank
evap = (total - newtot) / len(next_ranks)
# print newtot, evap
for node in next_ranks:
next_ranks[node] = next_ranks[node] + evap
newtot = 0
for (node, next_rank) in list(next_ranks.items()):
newtot = newtot + next_rank
# Compute the per-page average change from old rank to new rank
# As indication of convergence of the algorithm
totdiff = 0
for (node, old_rank) in list(prev_ranks.items()):
new_rank = next_ranks[node]
diff = abs(old_rank-new_rank)
totdiff = totdiff + diff
avediff = totdiff / len(prev_ranks)
print(i+1, avediff)
# rotate
prev_ranks = next_ranks
# Put the final ranks back into the database
print(list(next_ranks.items())[:5])
cur.execute('''UPDATE Pages SET old_rank=new_rank''')
for (id, new_rank) in list(next_ranks.items()) :
cur.execute('''UPDATE Pages SET new_rank=? WHERE id=?''' , (new_rank, id))
conn.commit()
cur.close()
import sqlite3
conn = sqlite3.connect('spider.sqlite')
cur = conn.cursor()
print("Creating JSON output on spider.js... ")
howmany = int(input("How many nodes? "))
cur.execute('''SELECT COUNT(from_id) AS inbound, old_rank, new_rank, id, url
FROM Pages JOIN Links ON Pages.id = Links.to_id
WHERE html IS NOT NULL AND ERROR IS NULL
GROUP BY id ORDER BY id,inbound''')
fhand = open('spider.js','w')
nodes = list()
maxrank = None
minrank = None
for row in cur :
nodes.append(row)
rank = row[2]
if maxrank is None or maxrank < rank: maxrank = rank
if minrank is None or minrank > rank : minrank = rank
if len(nodes) > howmany : break
if maxrank == minrank or maxrank is None or minrank is None:
print("Error - please run sprank.py to compute page rank")
quit()
fhand.write('spiderJson = {"nodes":[\n')
count = 0
map = dict()
ranks = dict()
for row in nodes :
if count > 0 : fhand.write(',\n')
# print row
rank = row[2]
rank = 19 * ( (rank - minrank) / (maxrank - minrank) )
fhand.write('{'+'"weight":'+str(row[0])+',"rank":'+str(rank)+',')
fhand.write(' "id":'+str(row[3])+', "url"::"'+row[4]+'"}')
map[row[3]] = count
ranks[row[3]] = rank
count = count + 1
fhand.write('],\n')
cur.execute('''SELECT DISTINCT from_id, to_id FROM Links''')
fhand.write('"links":[\n')
count = 0
for row in cur :
# print row
if row[0] not in map or row[1] not in map : continue
if count > 0 : fhand.write(',\n')
rank = ranks[row[0]]
srank = 19 * ( (rank - minrank) / (maxrank - minrank) )
fhand.write('{"source":'+str(map[row[0]])+',"target":'+str(map[row[1]])+',"value":3}')
count = count + 1
fhand.write(']};')
fhand.close()
cur.close()
print("Open force.html in a browser to view the visualization")
<イグ
2.
import sqlite3
conn = sqlite3.connect('spider.sqlite')
cur = conn.cursor()
# Find the ids that send out page rank - we only are interested
# in pages in the SCC that have in and out links
cur.execute('''SELECT DISTINCT from_id FROM Links''')
from_ids = list()
for row in cur:
from_ids.append(row[0])
# Find the ids that receive page rank
to_ids = list()
links = list()
cur.execute('''SELECT DISTINCT from_id, to_id FROM Links''')
for row in cur:
from_id = row[0]
to_id = row[1]
if from_id == to_id : continue
if from_id not in from_ids : continue
if to_id not in from_ids : continue
links.append(row)
if to_id not in to_ids : to_ids.append(to_id)
# Get latest page ranks for strongly connected component
prev_ranks = dict()
for node in from_ids:
cur.execute('''SELECT new_rank FROM Pages WHERE id = ?''' , (node, ))
row = cur.fetchone()
prev_ranks[node] = row[0]
sval = input('How many iterations:')
many = 1
if ( len(sval) > 0 ) : many = int(sval)
# Sanity check
if len(prev_ranks) < 1 :
print("Nothing to page rank. Check data.")
quit()
# Lets do Page Rank in memory so it is really fast
for i in range(many):
# print prev_ranks.items()[:5]
next_ranks = dict();
total = 0.0
for (node, old_rank) in list(prev_ranks.items()):
total = total + old_rank
next_ranks[node] = 0.0
# print total
# Find the number of outbound links and sent the page rank down each
for (node, old_rank) in list(prev_ranks.items()):
# print node, old_rank
give_ids = list()
for (from_id, to_id) in links:
if from_id ! = node : continue
# print ' ',from_id,to_id
if to_id not in to_ids: continue
give_ids.append(to_id)
if ( len(give_ids) < 1 ) : continue
amount = old_rank / len(give_ids)
# print node, old_rank,amount, give_ids
for id in give_ids:
next_ranks[id] = next_ranks[id] + amount
newtot = 0
for (node, next_rank) in list(next_ranks.items()):
newtot = newtot + next_rank
evap = (total - newtot) / len(next_ranks)
# print newtot, evap
for node in next_ranks:
next_ranks[node] = next_ranks[node] + evap
newtot = 0
for (node, next_rank) in list(next_ranks.items()):
newtot = newtot + next_rank
# Compute the per-page average change from old rank to new rank
# As indication of convergence of the algorithm
totdiff = 0
for (node, old_rank) in list(prev_ranks.items()):
new_rank = next_ranks[node]
diff = abs(old_rank-new_rank)
totdiff = totdiff + diff
avediff = totdiff / len(prev_ranks)
print(i+1, avediff)
# rotate
prev_ranks = next_ranks
# Put the final ranks back into the database
print(list(next_ranks.items())[:5])
cur.execute('''UPDATE Pages SET old_rank=new_rank''')
for (id, new_rank) in list(next_ranks.items()) :
cur.execute('''UPDATE Pages SET new_rank=? WHERE id=?''' , (new_rank, id))
conn.commit()
cur.close()
<イグ
import sqlite3
conn = sqlite3.connect('spider.sqlite')
cur = conn.cursor()
print("Creating JSON output on spider.js... ")
howmany = int(input("How many nodes? "))
cur.execute('''SELECT COUNT(from_id) AS inbound, old_rank, new_rank, id, url
FROM Pages JOIN Links ON Pages.id = Links.to_id
WHERE html IS NOT NULL AND ERROR IS NULL
GROUP BY id ORDER BY id,inbound''')
fhand = open('spider.js','w')
nodes = list()
maxrank = None
minrank = None
for row in cur :
nodes.append(row)
rank = row[2]
if maxrank is None or maxrank < rank: maxrank = rank
if minrank is None or minrank > rank : minrank = rank
if len(nodes) > howmany : break
if maxrank == minrank or maxrank is None or minrank is None:
print("Error - please run sprank.py to compute page rank")
quit()
fhand.write('spiderJson = {"nodes":[\n')
count = 0
map = dict()
ranks = dict()
for row in nodes :
if count > 0 : fhand.write(',\n')
# print row
rank = row[2]
rank = 19 * ( (rank - minrank) / (maxrank - minrank) )
fhand.write('{'+'"weight":'+str(row[0])+',"rank":'+str(rank)+',')
fhand.write(' "id":'+str(row[3])+', "url"::"'+row[4]+'"}')
map[row[3]] = count
ranks[row[3]] = rank
count = count + 1
fhand.write('],\n')
cur.execute('''SELECT DISTINCT from_id, to_id FROM Links''')
fhand.write('"links":[\n')
count = 0
for row in cur :
# print row
if row[0] not in map or row[1] not in map : continue
if count > 0 : fhand.write(',\n')
rank = ranks[row[0]]
srank = 19 * ( (rank - minrank) / (maxrank - minrank) )
fhand.write('{"source":'+str(map[row[0]])+',"target":'+str(map[row[1]])+',"value":3}')
count = count + 1
fhand.write(']};')
fhand.close()
cur.close()
print("Open force.html in a browser to view the visualization")
<イグ
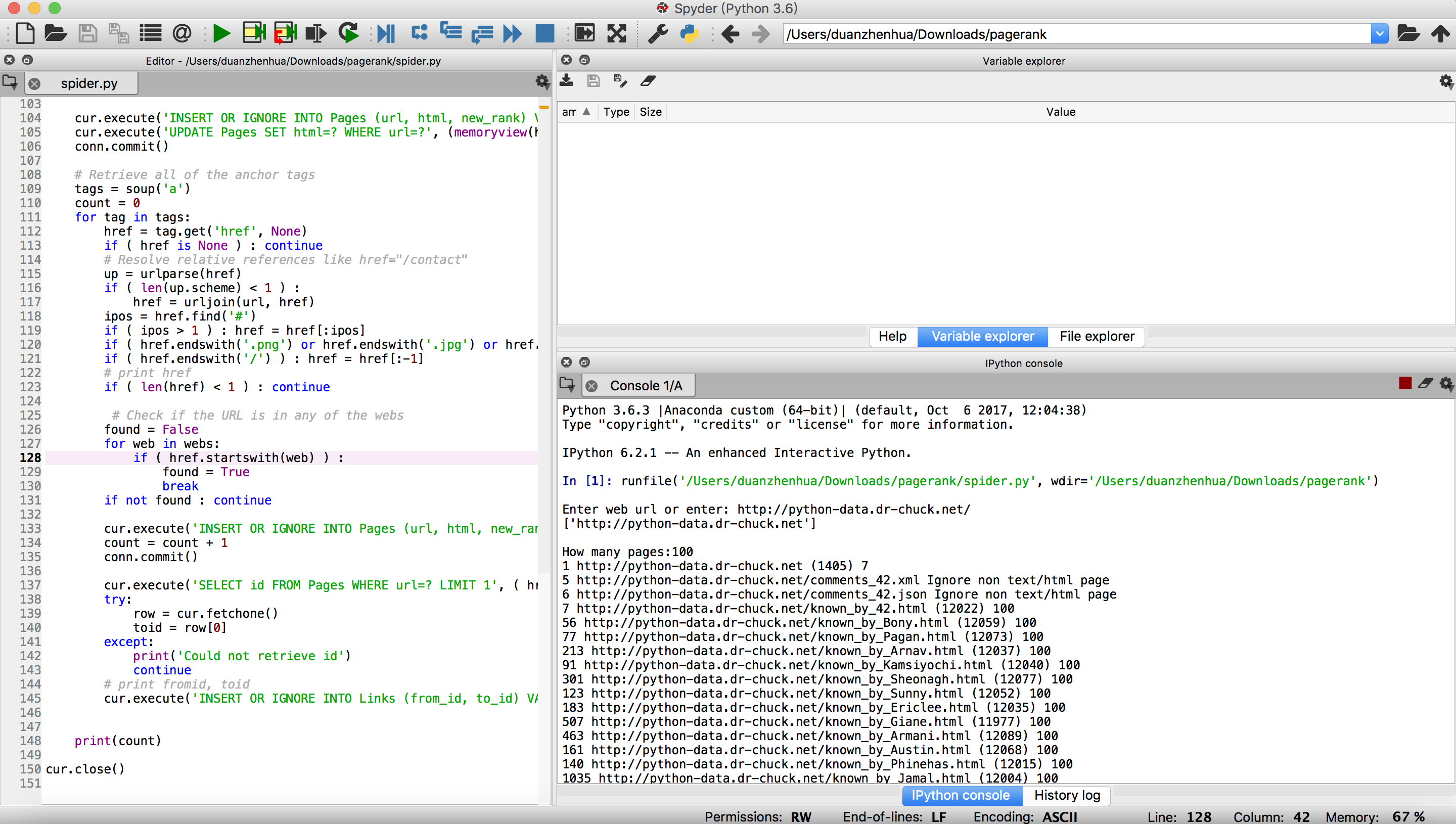
3、4 上記の手順を繰り返し、Zhihuや他のサイトを少しクロールします。
関連
-
Python jiabaライブラリの使用方法について説明
-
[解決済み】終了コード139でプロセスが終了(シグナル11:SIGSEGVで中断された)。
-
[解決済み] Spyderが起動しない
-
[解決済み] matplotlib.pyplotで凡例の大きさを変更する方法
-
[解決済み] 'tuple' オブジェクトはアイテムの割り当てをサポートしていません。
-
[解決済み] pyathenaを使ったaws athenaクエリの実行
-
[解決済み] 辞書で「TypeError: 'unicode' object does not support item assignment」が発生する。
-
[解決済み] TypeError: 文字バッファオブジェクトを期待した - 整数をテキストファイルに保存しようとしている時
-
Python2 error connecting to mysql to get value TypeError: unsupported operand type(s) for /: 'float' および 'NoneType'
-
python3 プログラミングエラー [1]: ValueError: 解凍する値が足りない (期待値 2、取得値 1)
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
Python Decorator 練習問題
-
Python 人工知能 人間学習 描画 機械学習モデル作成
-
Pythonによるjieba分割ライブラリ
-
[解決済み] Windows での Python ライブラリのインストールに関する問題点 : CondaHTTPErrorです。HTTP 000 CONNECTION FAILED for url <https://conda.anaconda.org/anaconda/win-64
-
[解決済み] Python scipy: ** や pow() でサポートされていないオペランドタイプ: 'list' や 'list' です。
-
[解決済み] urls という名前のモジュールがない
-
[解決済み] Project Euler #3 with python - MOST EFFICIENT METHOD [クローズド].
-
[解決済み] pyhiveを使用してリモートハイブにアクセスする方法
-
[解決済み] Pythonは関数を実行せずに存在するかどうかをチェックする
-
EnvironmentErrorのため、パッケージをインストールできませんでした。