[解決済み] ベンチマーク(BLASによるpythonとc++)と(numpy)
質問
BLASとLAPACKの線形代数機能を多用するプログラムを書きたいと思っています。パフォーマンスが問題なので、私はいくつかのベンチマークを行い、私が取ったアプローチが正当であるかどうかを知りたいと思います。
私は、いわば 3 人の競争相手を持っており、単純な行列-行列の乗算で彼らのパフォーマンスをテストしたいと思います。参加者は次のとおりです。
-
の機能だけを利用したNumpy。
dot. - Python、共有オブジェクトを通してBLASの機能性を呼び出します。
- C++、共有オブジェクトを通してBLASの機能性を呼び出します。
シナリオ
異次元の行列-行列の掛け算を実装してみた
i
.
i
は 5 から 500 まで 5 ずつ増加し、マトリック
m1
と
m2
はこのように設定されています。
m1 = numpy.random.rand(i,i).astype(numpy.float32)
m2 = numpy.random.rand(i,i).astype(numpy.float32)
1. Numpy
使用したコードは以下のような感じです。
tNumpy = timeit.Timer("numpy.dot(m1, m2)", "import numpy; from __main__ import m1, m2")
rNumpy.append((i, tNumpy.repeat(20, 1)))
2. Python、共有オブジェクトを経由してBLASを呼び出す
関数を用いて
_blaslib = ctypes.cdll.LoadLibrary("libblas.so")
def Mul(m1, m2, i, r):
no_trans = c_char("n")
n = c_int(i)
one = c_float(1.0)
zero = c_float(0.0)
_blaslib.sgemm_(byref(no_trans), byref(no_trans), byref(n), byref(n), byref(n),
byref(one), m1.ctypes.data_as(ctypes.c_void_p), byref(n),
m2.ctypes.data_as(ctypes.c_void_p), byref(n), byref(zero),
r.ctypes.data_as(ctypes.c_void_p), byref(n))
を実行すると、テストコードはこのようになります。
r = numpy.zeros((i,i), numpy.float32)
tBlas = timeit.Timer("Mul(m1, m2, i, r)", "import numpy; from __main__ import i, m1, m2, r, Mul")
rBlas.append((i, tBlas.repeat(20, 1)))
3. c++で、共有オブジェクトを通してBLASを呼び出す。
さて、c++のコードは当然ながら少し長くなるので、情報を最小限にしています。
で関数を読み込んでいます。
void* handle = dlopen("libblas.so", RTLD_LAZY);
void* Func = dlsym(handle, "sgemm_");
で時間を計測しています。
gettimeofday
のようにします。
gettimeofday(&start, NULL);
f(&no_trans, &no_trans, &dim, &dim, &dim, &one, A, &dim, B, &dim, &zero, Return, &dim);
gettimeofday(&end, NULL);
dTimes[j] = CalcTime(start, end);
ここで
j
は20回実行されるループです。で経過時間を計算しています。
double CalcTime(timeval start, timeval end)
{
double factor = 1000000;
return (((double)end.tv_sec) * factor + ((double)end.tv_usec) - (((double)start.tv_sec) * factor + ((double)start.tv_usec))) / factor;
}
結果
結果は以下のプロットで示されます。
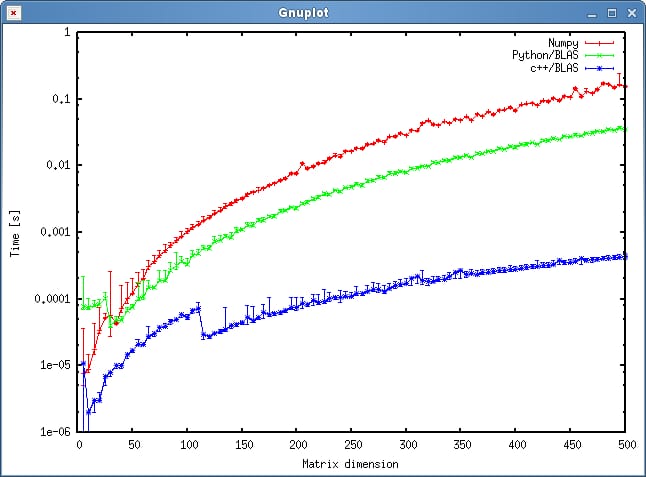
質問
- 私のアプローチは公平だと思いますか、それとも私が避けることのできる不必要なオーバーヘッドがありますか?
- c++ と python のアプローチで、結果がこれほど大きな食い違いを示すと予想されますか? 両方とも、計算に共有オブジェクトを使用しています。
- 私のプログラムには python を使用したいので、BLAS または LAPACK ルーチンを呼び出す際のパフォーマンスを向上させるにはどうしたらよいでしょうか?
ダウンロード
完全なベンチマークをダウンロードすることができます はこちら . (J.F.セバスチャンのおかげでこのリンクが実現しました^^)
どのように解決するのですか?
私は ベンチマーク . 私のマシンでは、C++とnumpyの間に違いはありません。
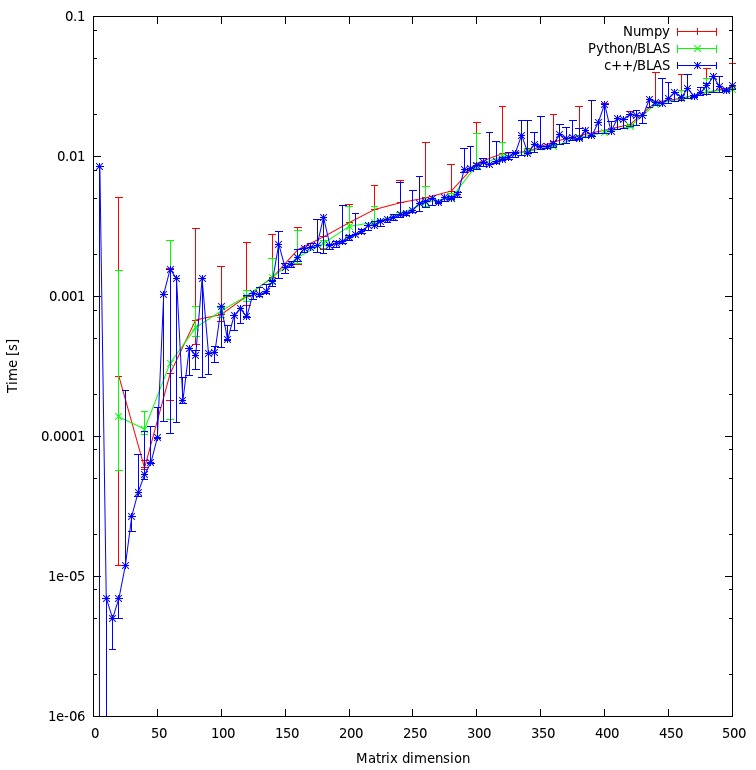
私のアプローチは公平だと思いますか?それとも、私が避けることのできる不必要なオーバーヘッドがありますか?
結果に差がないため、公正であると思われます。
<ブロッククオートc++とpythonのアプローチで、結果がこれほど大きな不一致を示すと予想されますか?両方とも、計算に共有オブジェクトを使用しています。
いいえ。
<ブロッククオート私のプログラムには python を使いたいので、BLAS または LAPACK ルーチンを呼び出す際のパフォーマンスを上げるにはどうしたらよいでしょうか。
numpyがシステム上でBLAS/LAPACKライブラリの最適化されたバージョンを使用していることを確認してください。
関連
-
[解決済み】エラー。switchステートメントでcaseラベルにジャンプする
-
[解決済み] スタックアロケーションにより初期化されていない値が作成された
-
[解決済み] staticmethodとclassmethodの違いについて
-
[解決済み] Pythonには文字列の'contains'サブストリングメソッドがありますか?
-
[解決済み] Pythonで現在時刻を取得する方法
-
[解決済み] なぜC++はPythonよりもstdinからの行の読み込みが遅いのですか?
-
[解決済み] time(1) の出力における 'real', 'user' および 'sys' はどのような意味ですか?
-
[解決済み】ネストされたディレクトリを安全に作成するには?
-
[解決済み】forループを使った辞書の反復処理
-
[解決済み】Pythonに三項条件演算子はありますか?
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み】 unsigned int vs. size_t
-
[解決済み] テスト
-
[解決済み】C++エラー。アーキテクチャ x86_64 に対して未定義のシンボル
-
[解決済み】C++でint型に無限大を設定する
-
[解決済み】LLVMで暗黙のうちに削除されたコピーコンストラクタの呼び出し
-
[解決済み】識別子 "string "は未定義?
-
[解決済み] [Solved] Error C1083: Cannot open include file: 'stdafx.h'
-
[解決済み】抽象クラス型の無効なnew-expression
-
[解決済み] error: 'if' の前に unqualified-id を期待した。
-
[解決済み】C++の余分な資格エラー