BERT事前学習に基づく中国語名前付き固有表現認識のTensorFlow実装
BERT-BiLSMT-CRF-NER
NERタスクのTensorflowソリューション Google BERT微調整付きBiLSTM-CRFモデル使用
GitHub
https://github.com/macanv/BERT-BiLSTM-CRF-NER
この記事は、機関のカタログです。
- 自分でモデルを学習する
- 説明
- 結果
- 独自のデータを使用する
2019.1.31更新 pip installパッケージ対応
以下のコマンドでパッケージがダウンロードできるようになりました。
pip install bert-base==0.0.7 -i https://pypi.python.org/simple
または、以下のソースベースのインストールを使用します。
git clone https://github.com/macanv/BERT-BiLSTM-CRF-NER
cd BERT-BiLSTM-CRF-NER/
python3 setup.py install
何も問題がなければ、このように表示されます。
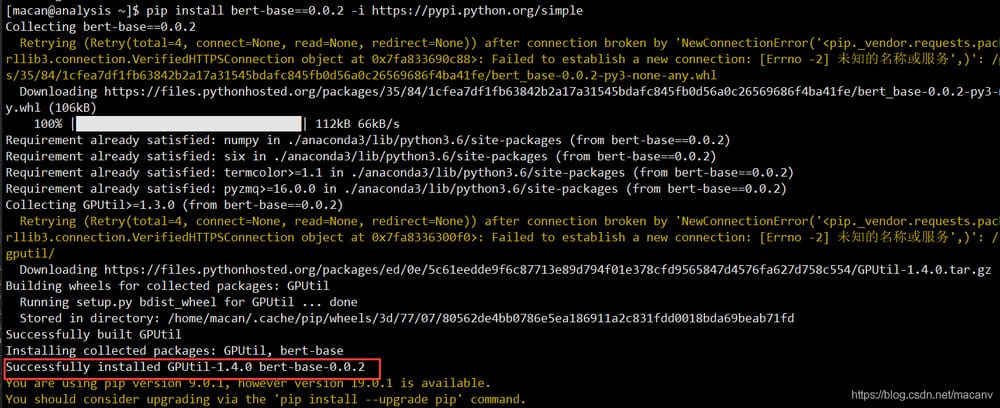
Windows 10/ Linux/ Mac OSXでテストしましたが、問題なくインストールできました。
現在パッケージでサポートされている機能
- 名前付き実体認識のための学習
- 名前付き実体の認識に関するサービスC/S
-
優れたオープンソースソフトウェアの継承:BERTの全サービスに対するbert_as_service(hanxiao)
4.テキスト分類サービス (2019.2.19)
コンテンツは今後も追加していきますので、鍛えられたモデルや新しい手法やデータ(ビジネスでは使わない弱小チキン、やはり新卒は無職のクズか~~)の共有は大歓迎です。
名前付き行を元に名前付き実体認識モデルを学習させる。
bert-base をインストールすると、2 つの名前付き行ベースのツールが生成されます。そのうちの 1 つである bert-base-ner-train は、名前付き実体認識モデルのトレーニングをサポートし、トレーニング データのディレクトリ、BERT 関連パラメータのディレクトリを指定する必要があるだけです。次のコマンドを使用して、ヘルプを表示することができます。
bert-base-ner-train -help
bert-base-ner-train \
-data_dir {your dataset dir}\
-output_dir {training output dir}\
-init_checkpoint {Google BERT model dir}\
-bert_config_file {bert_config.json under the Google BERT model dir} \
-vocab_file {vocab.txt under the Google BERT model dir}
<イグ
学習例には以下のような名前がついています。
Sea O
fishing O
Tournament O
Tournament O
Place O
Point O
in O
Building B-LOC
Door I-LOC
with O
Gold B-LOC
Door I-LOC
of O
between O
of O
Sea O
Domain O
O. O
パラメータの説明
-
トレーニングデータ、検証データ、テストデータのファイル名は train.txt, dev.txt, test.txt という形式になっており、この形式に従ってファイル名を付けるとエラーになります。
学習データのフォーマットは以下の通りです。bert-base-serving-start -help bert-base-serving-start \ -model_dir C:\workspace\python\BERT_Base\output\ner2 \ -bert_model_dir F:\english_L-12_H-768_A-12 -mode NER
各行は、最初の単語と2番目のそのタグを、スペース「'」で区切ってください。文章と文章の間は空白行で区切ってください。プログラムはあなたのデータを自動的に読み取ります。
- output_dir: 学習モデルの出力が格納されるファイルへのパス。モデルのチェックポイントとラベルマッピングテーブルが格納されます。
- init_checkpoint。ダウンロードしたGoogle BERTモデル
- bert_config_file : Google BERT モデルの下にある bert_config.json
- vocab_file : Google BERTモデルにおけるvocab.txt
学習が完了したら、指定したoutput_dirに学習結果が表示されます。
名前付きエンティティ認識タスクのサービス展開
サービスとして使用されるコードの多くは、優れたオープンソースプロジェクトから提供されています。 hanxiaoのサービスとしてのbert しかし、この変更がライセンス規定に抵触するかどうかはわかりません。もし抵触するようでしたら、すぐに教えてください。とサーバー側のコードは非常にデカップリングされている、別のタスクのためのサービスを変更しても、テキストの分類など、非常に簡単ですが、私はちょうどこの機能を提供しませんが、また、モデルやコードを共有するために喜んで子供たちを歓迎します。
bert-base-serving-startという名前のサービスですが、-helpでヘルプを見ることができます。
bert-base-serving-start -model_pd_dir /home/macan/ml/workspace/BERT_Base/output/predict_optimizer \
-bert_model_dir /home/macan/ml/data/chinese_L-12_H-768_A-12/ \
-ner_model_dir /home/macan/ml/data/bert_ner \
-num_worker 8
-mode NER
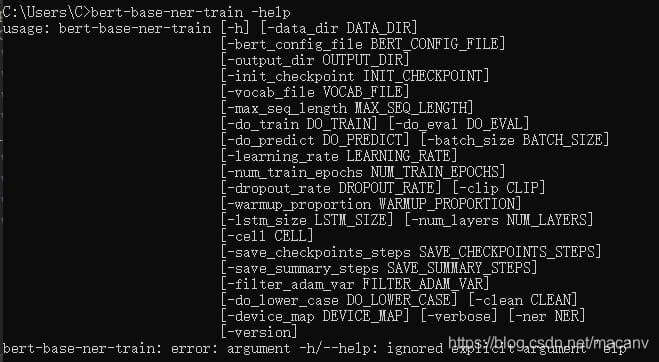
名前付きエンティティ識別タスクのサービスとして、次の2つのディレクトリを指定する必要があります: ner_model_dir, bert_model_dir
そして、以下のコマンドでそれらを起動することができます。
import time
from bert_base.client import BertClient
# Specify the IP of the server
with BertClient(ip='XXX,XXX,XXX,XXX', ner_model_dir=ner_model_dir, show_server_config=False, check_version=False, check_length=False, mode='NER') as bc:
start_t = time.perf_counter()
str = 'On January 24, Xinhua News Agency released the central government's guidance for the Xiong'an New Area, spilling over 12,000 words, mentioning Beijing 17 times and Tianjin 4 times, which is a lot of information and actually answers a lot of people's concerns.'
rst = bc.encode([str, str]) # test inputting two sentences at the same time, same for multiple inputs
print('rst:', rst)
print(time.perf_counter() - start_t)
パラメータの説明
bert_model_dir: Google BERT モデルを解凍するためのパスです。
https://github.com/google-research/bert
model_dir: 学習したNERモデルまたはテキスト分類モデルへのパス、上記のoutput_dirの場合
model_pd_dir: モデル最適化コード実行後に圧縮されたモデルが格納されるパス。例えば、上記コマンド実行後にバイナリファイル ner_model.pb がこのパスの下に生成されます。
mode:NER or BERT, type is string, if it is NER, then it will start NER service, if it is BERT, then the specific parameters will be same as the [bert as service] project.
名前付き実体認識のpbモデルは、以下のサイトでダウンロードできるようにしています。
https://pan.baidu.com/s/1m9VcueQ5gF-TJc00sFD88w
抽出コード: guqq
テキスト分類モデル。
https://pan.baidu.com/s/1oFPsOUh1n5AM2HjDIo2XCw
, 抽出コード:bbu8
テキストソートは、bert の demo:run_classxxx.py を使用しており、実行時に Pickle を使用して label_list と id2label フォールド変数をシリアライズしています。
ner_mode.pb/classification_model.pb ファイルを model_pd_dir ディレクトリに置き、命名認識 label_list.pkl と id2map.pkl は名前は同じだが中身が違うので区別する必要があるのでモデルごとに別のフォルダーに置く。
名前付き実体認識モデルは、人、場所、住所、組織の認識のみをサポートし、私のテストデータでのF1値は95.6%(実体レベルのスコア)であった
清華大学のテキスト分類モデルデータ。
http://thuctc.thunlp.org/
テストデータで98%から99%の精度で、、、。
太っちょは、より良く訓練されたモデルを共有することを歓迎します。
ダウンロードしたモデルを使用する場合は、以下のコマンドで自分のパスを置き換えて起動します。
git clone https://github.com/macanv/BERT-BiLSTM-CRF-NER
次のような起動メッセージが表示されます(起動ログはちょっと多いので、2枚に切ってあります)。
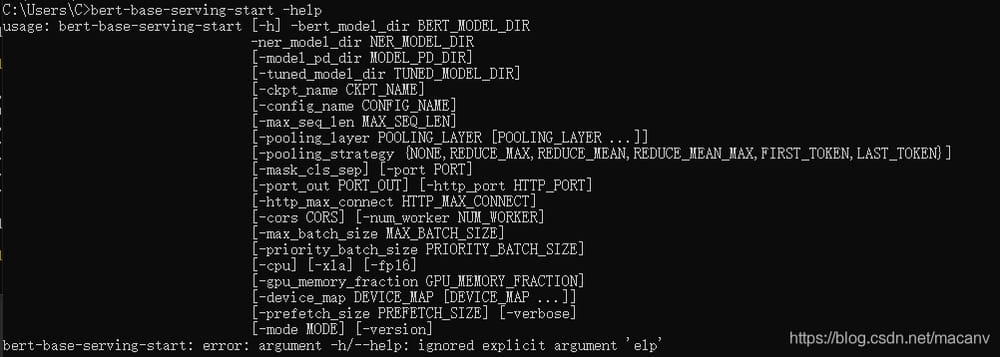
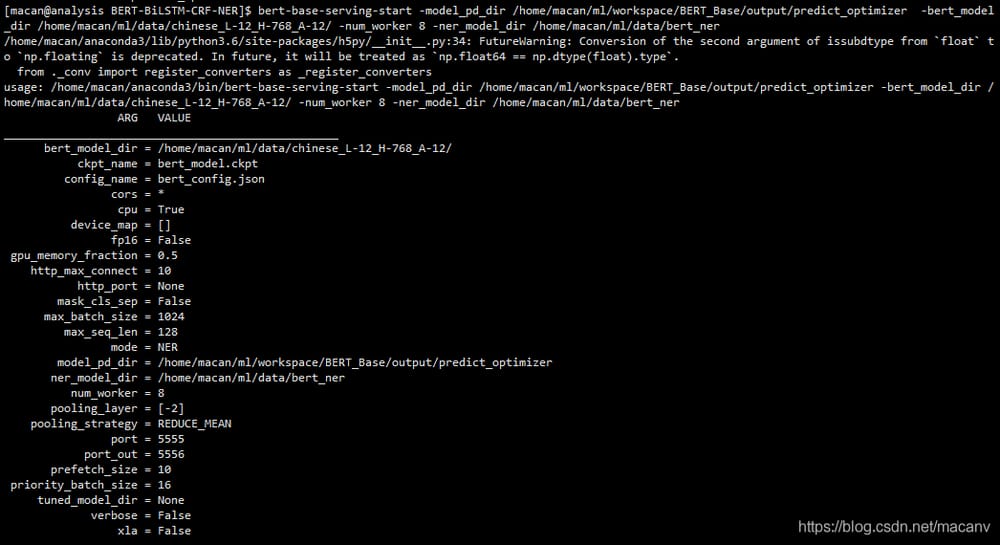
ローカル接続サーバーでの名前付きエンティティ認識のテスト
以下のクライアントコードで、サービスに接続し、ローカルでNERテストを行うことができます。
Download
wget https://storage.googleapis.com/bert_models/2018_11_03/chinese_L-12_H-768_A-12.zip
Unzip
unzip chinese_L-12_H-768_A-12.zip
実行すると、次のようなメッセージが出力されます。
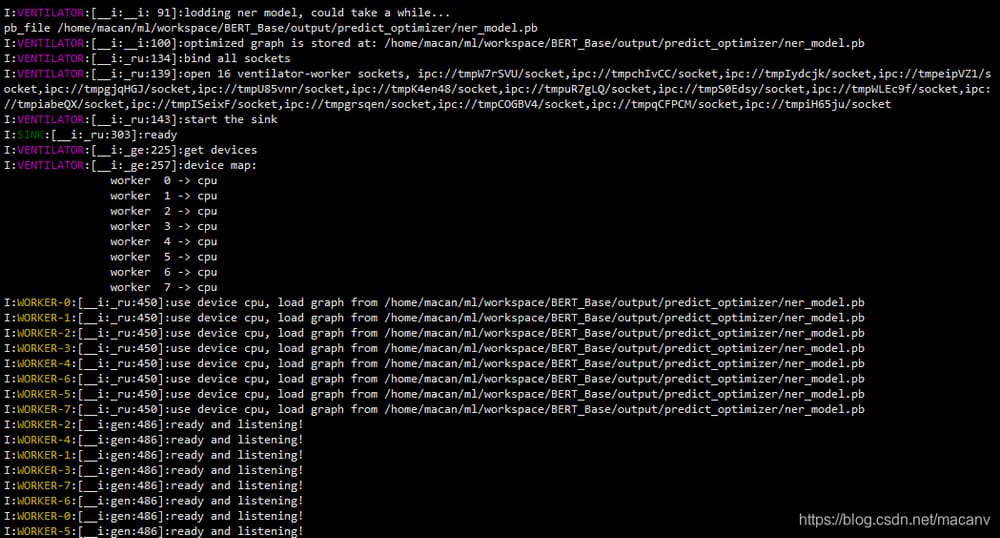
結果の説明
返された結果は、シーケンスラベリングの結果であり、その後の仕事は、後者の操作は、いくつかの戦略的な問題を含むので、書く準備ができていない、あまりにも多くの、コードの柔軟性に影響を与える、例えば、問題にfinal_predict.pyコードで子供の靴があり、独自のデータに適用することはできません。これはまた、より直感的に見えますよね〜〜〜。
コマンドラインベースの使い方は以上です。分からないことがあればコメントするか、GitHubに課題を提出してください。また、便利だと思った方は ギットハブ GitHubの星空~~~。
###########################################################################################
トレーニングやサービスを開始するためのソースコードベースのチュートリアルはこちらです。
###########################################################################################
独自の名前付き実体認識モデルの学習
BLSTM-CRFモデルで事前学習したGoogleのBERTモデルを使った中国語名前付き固有表現認識のTensorflowコード'
コードはGitHubにホストされています コードポータル クローンして、自分の目で確かめてください。
mkdir output
この記事では、中国語の名前付きエンティティのBERTに基づく微調整プロセスに焦点を当てています。
1. Google BERT事前学習モデルをダウンロードします。
python3 bert_lstm_ner.py \
--task_name="NER" \
--do_train=True \
--do_eval=True \
--do_predict=True
--data_dir=NERdata \
--vocab_file=checkpoint/vocab.txt \
--bert_config_file=checkpoint/bert_config.json \
--init_checkpoint=checkpoint/bert_model.ckpt \
--max_seq_length=128 \
--train_batch_size=32 \
--learning_rate=2e-5 \
--num_train_epochs=3.0 \
--output_dir=. /output/result_dir/
2. モデルの学習
Google の BERT モデルと私の GitHub コードをダウンロードした後、トレーニングを開始できます。
トレーニングの前に、プロジェクトのディレクトリに新しいoutputフォルダを作成し、そこにモデルの出力と構造を格納します。
if os.name == 'nt': #windows path config
bert_path = '{your BERT model path}'
root_path = '{project path}'
else: # linux path config
bert_path = '{your BERT model path}'
root_path = '{project path}'
モデルパラメータは、例えば以下のように名前付き行の形で指定することができます。
python3 bert_lstm_ner.py
筆者は初心者なので、デフォルトのパラメータを書くことにしました。トレーニングを始める前に、bert_lstm_ner.py ファイルにある以下のコードを修正するだけです。
# Make our input_ids data pass through the bert network structure
model = modeling.BertModel(
config=bert_config,
is_training=is_training,
input_ids=input_ids,
input_mask=input_mask,
token_type_ids=segment_ids,
use_one_hot_embeddings=use_one_hot_embeddings
)
# Get the last layer of the bert model
embedding = model.get_sequence_output()
os.name=='nt' は、認識されているシステムが Windows であることを示し、残りは Linux です。ここでは、1つだけ修正する必要があり、Windows のトレーニングであれば、パスの下の os.name='nt' を修正すればよく、Linux または Mac は、パスの下の else を修正します。
2つのパスが記述されています。
bert_path。ステップ1でダウンロード・抽出したBERTモデルのパス、絶対パスをコピーして置き換えるだけ、例えば、私のプロジェクトに書かれているパス
root_path。これはプロジェクトのパスで、絶対パスでもあり、すなわちBERT-BiLSTM-CRF-NERのパスである。
2つのパスを修正した後、トレーニングを開始することができます。
# Load the BLSTM-CRF model object
blstm_crf = BLSTM_CRF(embedded_chars=embedding, hidden_unit=FLAGS.lstm_size, cell_type=FLAGS.cell, num_layers=FLAGS.num_layers,
dropout_rate=FLAGS.droupout_rate, initializers=initializers, num_labels=num_labels,
seq_length=max_seq_length, labels=labels, lengths=lengths, is_training=is_training)
# Get the results after adding our own network structure, these results include loss, logits, trans, pred_ids
rst = blstm_crf.add_blstm_crf_layer(crf_only=True)
説明
モデルのコードは主にbert_lstm_ner.pyのcreate_model関数にあります。
この関数のロジックを以下に説明する。
- 1 bert モデルを使って入力を再現する。
python3 terminal_predict.py
bertの最後の層は、すべての変換結果の最後の次元であり、次元[batch_size, seq_length, embedding_size]の3次元ベクトルであり、これはtf.nn.embedding_lookupを使って得られる結果と同様に解釈することが可能です。
- 2 LSTM構造の入力としてエンベッディングを使用する。
def get_labels(self):
return ["O", "B-PER", "I-PER", "B-ORG", "I-ORG", "B-LOC", "I-LOC", " quot;X", "[CLS]", "[SEP]"]
ここで、いくつか注意点があります。
- BERT内部には既に双方向エンコーディングが存在するため、LSTMは必要なく、BERTの最終層の構造を直接CRFに投げてデコードすることができる。そこで、コード中のadd_blstm_crf_layer関数のcrf_onlyパラメータによって、学習時の微調整に用いるネットワーク構造の種類を制御しています。トランスフォーマーの力
- crf_only=TrueはデコードにCRFのみを使用し、従来の古典的なBLSTM-CRFを使用しない微調整、Falseはblstm-crfのようなネットワーク構造を使用することを意味します。
- しかし、CRFだけを使った場合の学習時間は、BLSTM-CRF構造の場合よりも長いことが実験でわかり、理解できないので、BLSTMネットワークにパラメータを追加するのが合理的だと思います。もし、これが間違った観察であるとか、合理的な説明をお持ちのお兄さんがいらっしゃいましたら、遠慮なくご教示をお願いします。
実験結果
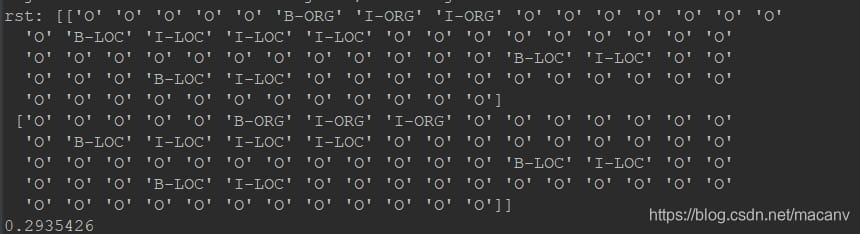
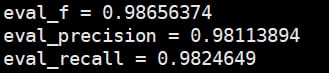
- 1 ラベルを元に計算されたメトリクス。
devデータセットで。
テストデータセットにおいて
-
2 エンティティレベルのレビューを用いてエンティティ結果を命名する方が理にかなっている箇所が多く、ここではエンティティレベルのレビューの結果を紹介します。
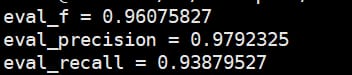
レビュースクリプトはconlleval.plを使用しています。 は、その conlleval.py
学習させたモデルのダウンロードを提供するため。
私のモデルは、バイドゥクラウドからダウンロードできます。
リンク https://pan.baidu.com/s/1GfDFleCcTv5393ufBYdgqQ 抽出コード 4cus
-
3 オンライン予測
モデルの学習が完了したら、以下のスクリプトを使用してモデルをロードし、オンライン予測を行うことができます。
def get_labels(self):
# There is some risk in getting the labels by reading the train file.
if os.path.exists(os.path.join(FLAGS.output_dir, 'label_list.pkl')):
with codecs.open(os.path.join(FLAGS.output_dir, 'label_list.pkl'), 'rb') as rf:
self.labels = pickle.load(rf)
else:
if len(self.labels) > 0:
self.labels = self.labels.union(set(["X", "[CLS]", "[SEP]"]))
with codecs.open(os.path.join(FLAGS.output_dir, 'label_list.pkl'), 'wb') as rf:
pickle.dump(self.labels, rf)
else:
self.labels = ["O", 'B-TIM', 'I-TIM', "B-PER", "I-PER", "B-ORG", "I-ORG", "B-LOC& quot;, "I-LOC", "X", "[CLS]", "[SEP]"]
return self.labels
<イグ
自分のデータを使って
BERTの太ももは、単に厚すぎる、効果は非常に良いですが、そのような効果を参照してください、再び自分のデータのいくつかをテストするために非常に熱心ではありませんか?実際には、bert_lstm_ner.pyファイルのコードのわずかな行を変更することはほとんどありません。
-
- get_labels関数
def get_labels(self):
return ["O", "B-PER", "I-PER", "B-ORG", "I-ORG", "B-LOC", "I-LOC", " quot;X", "[CLS]", "[SEP]"]
ここに私のデータのすべてのタグがあります。quot;X", "[CLS]", "[SEP]" が付加され、 "[CLS]", & quot;[SEP]" は文頭、文末マーク、XはWordpiceで生成したもの、中国はまだ遭遇していない、あなたは無視できる、あなたはそれを変更したい、ちょうどその前にあるラベルを変更。
例えば、時間型のエンティティを追加したい場合は、"B-TIME", "I-TIME" を追加します。
分詞に適用するのであれば、-○○○はありません。B,Iのものだけで、要するに配列アノテーションデータの2列目のラベルのセットですね。
このようにget_labels関数をきっぱりと書くこともできますが、テストセットやバリデータに表示されるOOLabelに気をつけながら
def get_labels(self):
# There is some risk in getting the labels by reading the train file.
if os.path.exists(os.path.join(FLAGS.output_dir, 'label_list.pkl')):
with codecs.open(os.path.join(FLAGS.output_dir, 'label_list.pkl'), 'rb') as rf:
self.labels = pickle.load(rf)
else:
if len(self.labels) > 0:
self.labels = self.labels.union(set(["X", "[CLS]", "[SEP]"]))
with codecs.open(os.path.join(FLAGS.output_dir, 'label_list.pkl'), 'wb') as rf:
pickle.dump(self.labels, rf)
else:
self.labels = ["O", 'B-TIM', 'I-TIM', "B-PER", "I-PER", "B-ORG", "I-ORG", "B-LOC& quot;, "I-LOC", "X", "[CLS]", "[SEP]"]
return self.labels
参考
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
ハートビート・エフェクトのためのHTML+CSS
-
HTML ホテル フォームによるフィルタリング
-
HTML+cssのボックスモデル例(円、半円など)「border-radius」使いやすい
-
HTMLテーブルのテーブル分割とマージ(colspan, rowspan)
-
ランダム・ネームドロッパーを実装するためのhtmlサンプルコード
-
Html階層型ボックスシャドウ効果サンプルコード
-
QQの一時的なダイアログボックスをポップアップし、友人を追加せずにオンラインで話す効果を達成する方法
-
sublime / vscodeショートカットHTMLコード生成の実装
-
HTMLページを縮小した後にスクロールバーを表示するサンプルコード
-
html のリストボックス、テキストフィールド、ファイルフィールドのコード例