データ分析セッション8 シーボーン
データ分析セッション8 シーボーン

I. シーボーンの紹介
シーボーン
シーボーンとは
1. 魅力的で情報量の多い統計グラフを作成するためのPythonによるグラフ作成ツールのライブラリ
2. matplotlibをベースに、データ構造の可視化のためにnumpyとpandasをサポートする。
3. Seaborn は Matplotlib よりもシンプルで使い勝手が良い
シーボーン社ウェブサイト:http://seaborn.pydata.org/

4. Win7システムインストールseaborn
pip install seaborn -i https://pypi.douban.com/simple --trusted-host pypi.douban.com
II. シーボーンの特徴
1. 複数のカラーテーマ
2. データセットの各変数の分布を比較するために使用される一変量、二次元の変数を可視化する。
3. 線形回帰モデルにおける変数の可視化
4.行列データの可視化、クラスタリングアルゴリズムによる行列間の構造探索
5.時系列データと不確実性の可視化
6. 複雑なビジュアライゼーションのために、分割された領域でグラフ化することができる
三、シーボーンのシンプルな使い方
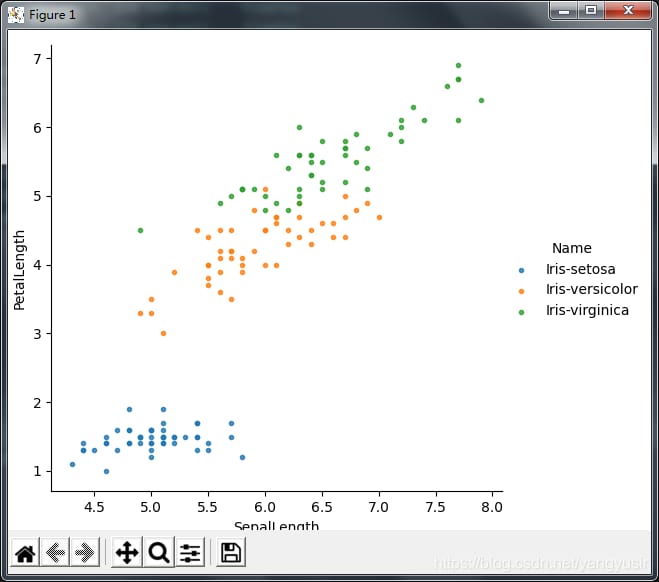
1. seabornでプロットする - 散布図
要求事項 花弁と萼の長さの散布図を描き、アヤメの種を区別するためにポイントを色付けする。
sns.lmplot()
# Simple use of seaborn
import pandas as pd
import seaborn as sns
from matplotlib import pyplot as plt
# Requirement: Draw a scatter plot of the length of the petal and calyx, and the color of the points should distinguish the species of the iris
df = pd.read_csv('. /iris.csv')
# print(df.info())
'''
RangeIndex: 150 entries, 0 to 149
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 SepalLength 150 non-null float64
1 SepalWidth 150 non-null float64
2 PetalLength 150 non-null float64
3 PetalWidth 150 non-null float64
4 Name 150 non-null object
dtypes: float64(4), object(1)
memory usage: 6.0+ KB
memory usage: 6+ KB
'''
# print(df.loc[:,'Name'].unique()) # ['Iris-setosa' 'Iris-versicolor' 'Iris-virginica']
# fit_reg=True default has regression lines
sns.lmplot(x='SepalLength',y='PetalLength',data=df,hue='Name',fit_reg=False,markers='.')
plt.show()
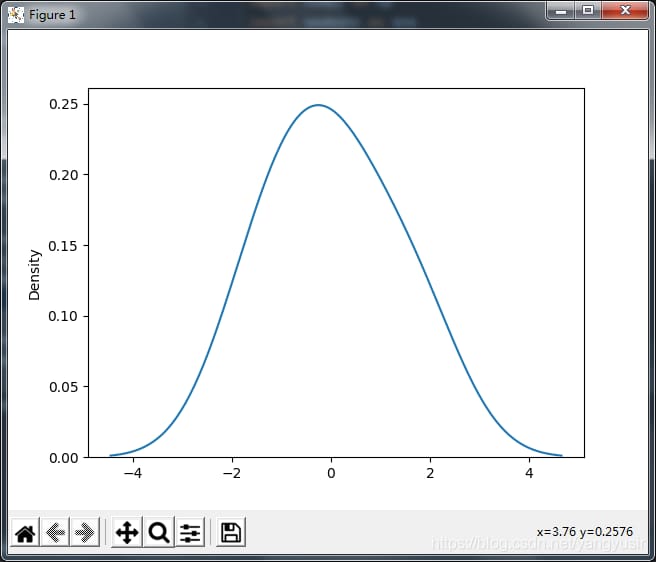
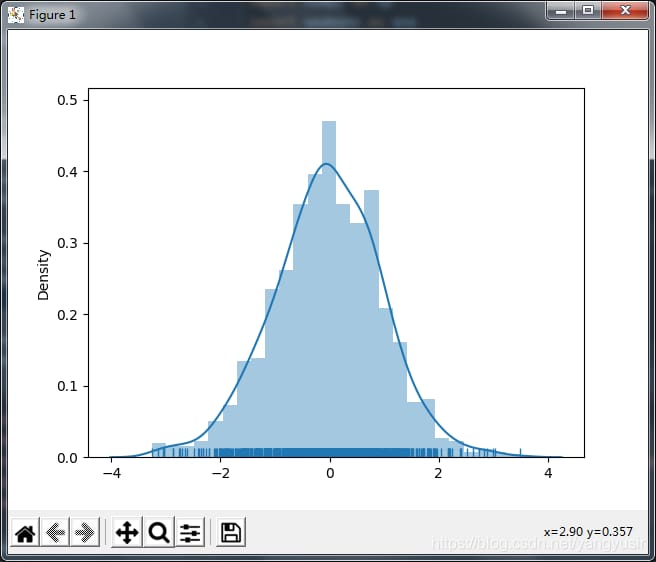
2. 一変量分布
カーネル密度推定プロット
1. カーネル密度推定(kernel density estimation)は、確率論において未知の密度関数を推定するために使用される。
2. カーネル密度推定プロットは、データサンプル自体の分布特性を可視化するために使用することができます
import numpy as np
import seaborn as sns
from matplotlib import pyplot as plt
# Normal distribution to generate data
data1 = np.random.normal(size=4)
sns.kdeplot(data1)
plt.show()
import numpy as np
import seaborn as sns
from matplotlib import pyplot as plt
# Normal distribution to generate data
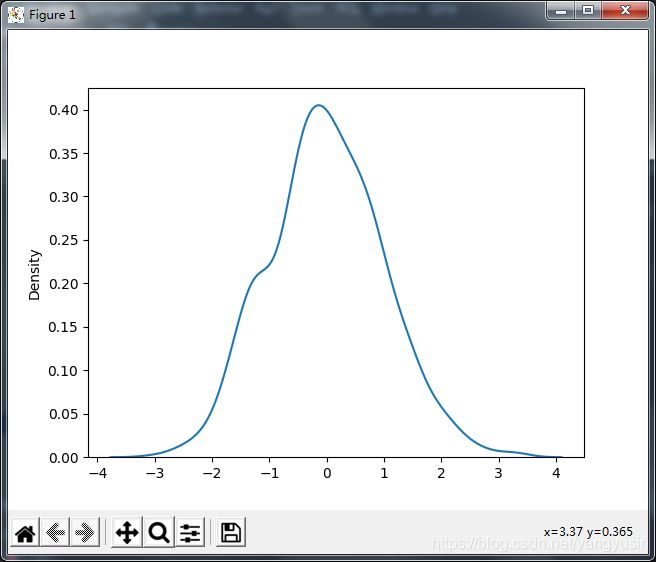
data1 = np.random.normal(size=1000)
sns.kdeplot(data1)
plt.show()
<イグ
# Simple use of seaborn
import pandas as pd
import numpy as np
import seaborn as sns
from matplotlib import pyplot as plt
s1 = pd.Series(np.random.randn(1000))
# Histogram
# plt.hist(s1)
# rug=True show density observation bar hist=True show histogram kde=True show kernel density estimation curve
sns.distplot(s1,kde=True,hist=True,rug=True)
# sns.kdeplot(s1,shade=True,color='r')
plt.show()
<イグ
ヒストグラムと密度プロットのプロット
distplot はヒストグラムとカーネル関数推定を一緒にしたものです。
- kde = True カーネル密度推定曲線を表示します。
- hist = True ヒストグラムを表示する
- rug = True 密度ウォッチバーを表示する。
# Simple use of seaborn
import pandas as pd
import numpy as np
import seaborn as sns
from matplotlib import pyplot as plt
df = pd.DataFrame({'x': np.random.randn(500), 'y': np.random.randn(500)})
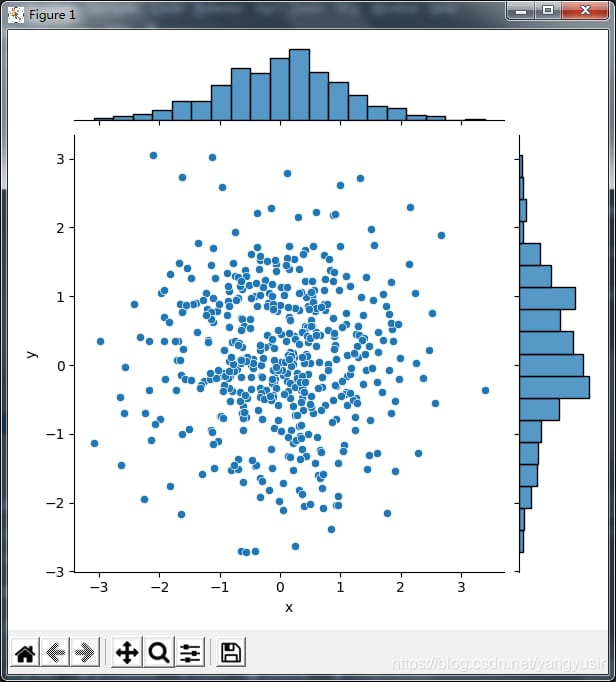
# Two-dimensional scatterplot
# sns.jointplot(x='x',y='y',data=df)
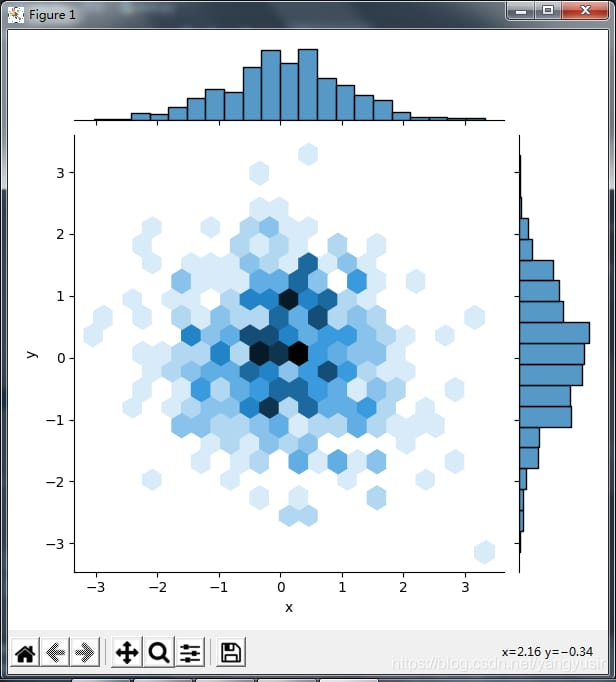
# two-dimensional histogram
# sns.jointplot(x='x',y='y',data=df,kind='hex')
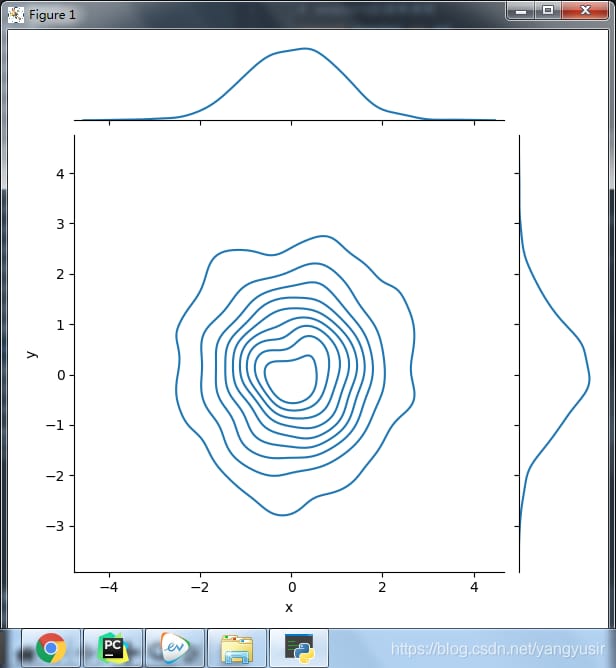
# Two-dimensional density plot
sns.jointplot(x='x', y='y', data=df, kind='kde')
plt.show()
# Plot heat map and histogram
import pandas as pd
import numpy as np
import seaborn as sns
from matplotlib import pyplot as plt
'''
name : str
Name of the dataset (``{name}.csv`` on
https://github.com/mwaskom/seaborn-data).'''
# Load the online data
df = sns.load_dataset('flights')
# print(df.info())
'''
RangeIndex: 144 entries, 0 to 143
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 year 144 non-null int64
1 month 144 non-null category
2 passengers 144 non-null int64
dtypes: category(1), int64(2)
memory usage: 2.9 KB
None'''
# print(df.head())
'''
year month passengers
0 1949 Jan 112
1 1949 Feb 118
2 1949 Mar 132
3 1949 Apr 129
4 1949 May 121'''
df = df.pivot(index='month',columns='year',values='passengers')
# print(df.head())
'''
year 1949 1950 1951 ... 1958 1959 1960
month ...
Jan 112 115 145 ... 340 360 417
Feb 118 126 150 ... 318 342 391
Mar 132 141 178 ... 362 406 419
Apr 129 135 163 ... 348 396 461
May 121 125 172 ... 363 420 472'''
# heatmap
# sns.heatmap(df)
# sns.heatmap(df,annot=True,fmt='d') # annot=True,fmt='d' adjusts the value
# sns.heatmap(df,annot=True,fmt='d',cmap='YlGnBu') # cmap='YlGnBu' adjusts the color
s = df.sum()
# print(s)
'''
year
1949 1520
1950 1676
1951 2042
1952 2364
1953 2700
1954 2867
1955 3408
1956 3939
1957 4421
1958 4572
1959 5140
1960 5714
dtype: int64'''
x = s.index
y = s.values
# barplot
sns.barplot(x, y)
plt.show()
<イグ
3. 二変量分布
sns.jointplot(x,y,データ,種類)
- x,y 二次元データ、ベクトルまたは文字列
- x,yが文字列の場合、データはDataFrameである必要があります。
- kind='scatter' デフォルト,2次元散布図
- kind='hex',2次元ヒストグラム
- kind='ked',2次元カーネル密度推定プロット
# Set the display effect
import pandas as pd
import numpy as np
import seaborn as sns
from matplotlib import pyplot as plt
style = ['darkgrid', 'dark', 'white', 'whitegrid', 'ticks']
# Set the style
sns.set_style(style[0], {'grid.color': 'red'})
# Parameters for the current style
# print(sns.axes_style())
'''
{'axes.facecolor': '#EAEAF2', 'axes.edgecolor': 'white', 'axes.grid': True, 'axes.axisbelow': True, 'axes.labelcolor': '.15', 'figure. facecolor': 'white', 'grid.color': 'red', 'grid.linestyle': '-', 'text.color': '.15', 'xtick.color': '.15', 'ytick.color': '.15', 'xtick. direction': 'out', 'ytick.direction': 'out', 'lines.solid_capstyle': 'round', 'patch.edgecolor': 'w', 'patch.force_edgecolor': True, 'image. cmap': 'rocket', 'font.family': ['sans-serif'], 'font.sans-serif': ['Arial', 'DejaVu Sans', 'Liberation Sans', 'Bitstream Vera Sans', 'sans- serif'], 'xtick.bottom': False, 'xtick.top': False, 'ytick.left': False, 'ytick.right': False, 'axes.spines.left': True, 'axes.spines.bottom' : True, 'axes.spines.right': True, 'axes.spines.top': True}'''
context = ['paper', 'notebook', 'talk', 'poster']
sns.set_context(context[0], rc={'grid.linewidth': 2.0})
# print(sns.plotting_context())
'''
{'font.size': 9.600000000000001, 'axes.labelsize': 9.600000000000001, 'axes.titlesize': 9.600000000000001, 'xtick.labelsize': 8.8, 'ytick. labelsize': 8.8, 'legend.fontsize': 8.8, 'axes.linewidth': 1.0, 'grid.linewidth': 3.0, 'lines.linewidth': 1.20000000000000000002, 'lines. markersize': 4.800000000000001, 'patch.linewidth': 0.8, 'xtick.major.width': 1.0, 'ytick.major.width': 1.0, 'xtick.minor.width': 0.8, 'ytick .minor.width': 0.8, 'xtick.major.size': 4.800000000000001, 'ytick. size': 3.2, 'legend.title_fontsize': 9.600000000000001}'''
'''
name : str
Name of the dataset (``{name}.csv`` on
https://github.com/mwaskom/seaborn-data).'''
# Load the online data
df = sns.load_dataset('flights')
# print(df.info())
'''
RangeIndex: 144 entries, 0 to 143
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 year 144 non-null int64
1 month 144 non-null category
2 passengers 144 non-null int64
dtypes: category(1), int64(2)
memory usage: 2.9 KB
None'''
# print(df.head())
'''
year month passengers
0 1949 Jan 112
1 1949 Feb 118
2 1949 Mar 132
3 1949 Apr 129
4 1949 May 121'''
df = df.pivot(index='month', columns='year', values='passengers')
# print(df.head())
'''
year 1949 1950 1951 ... 1958 1959 1960
month ...
Jan 112 115 145 ... 340 360 417
Feb 118 126 150 ... 318 342 391
Mar 132 141 178 ... 362 406 419
Apr 129 135 163 ... 348 396 461
May 121 125 172 ... 363 420 472'''
# heatmap
# sns.heatmap(df)
# sns.heatmap(df,annot=True,fmt='d') # annot=True,fmt='d' adjusts the value
# sns.heatmap(df,annot=True,fmt='d',cmap='YlGnBu') # cmap='YlGnBu' adjusts the color
s = df.sum()
# print(s)
'''
year
1949 1520
1950 1676
1951 2042
1952 2364
1953 2700
1954 2867
1955 3408
1956 3939
1957 4421
1958 4572
1959 5140
1960 5714
dtype: int64'''
x = s.index
y = s.values
# barplot
sns.barplot(x, y)
plt.show()
<イグ
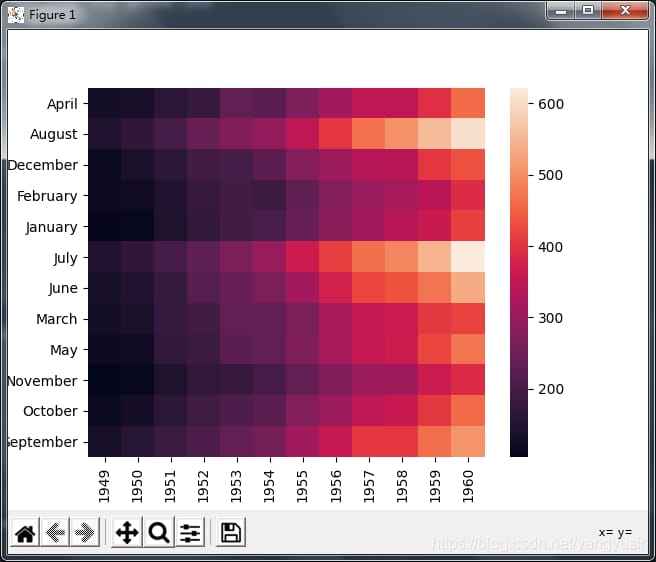
4. ヒートマップとヒストグラムのプロット
# Plot heat map and histogram
import pandas as pd
import numpy as np
import seaborn as sns
from matplotlib import pyplot as plt
'''
name : str
Name of the dataset (``{name}.csv`` on
https://github.com/mwaskom/seaborn-data).'''
# Load the online data
df = sns.load_dataset('flights')
# print(df.info())
'''
RangeIndex: 144 entries, 0 to 143
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 year 144 non-null int64
1 month 144 non-null category
2 passengers 144 non-null int64
dtypes: category(1), int64(2)
memory usage: 2.9 KB
None'''
# print(df.head())
'''
year month passengers
0 1949 Jan 112
1 1949 Feb 118
2 1949 Mar 132
3 1949 Apr 129
4 1949 May 121'''
df = df.pivot(index='month',columns='year',values='passengers')
# print(df.head())
'''
year 1949 1950 1951 ... 1958 1959 1960
month ...
Jan 112 115 145 ... 340 360 417
Feb 118 126 150 ... 318 342 391
Mar 132 141 178 ... 362 406 419
Apr 129 135 163 ... 348 396 461
May 121 125 172 ... 363 420 472'''
# heatmap
# sns.heatmap(df)
# sns.heatmap(df,annot=True,fmt='d') # annot=True,fmt='d' adjusts the value
# sns.heatmap(df,annot=True,fmt='d',cmap='YlGnBu') # cmap='YlGnBu' adjusts the color
s = df.sum()
# print(s)
'''
year
1949 1520
1950 1676
1951 2042
1952 2364
1953 2700
1954 2867
1955 3408
1956 3939
1957 4421
1958 4572
1959 5140
1960 5714
dtype: int64'''
x = s.index
y = s.values
# barplot
sns.barplot(x, y)
plt.show()
5. 表示効果を設定する
スタイル = ['darkgrid','dark','white','whitegrid ','ticks'].
# スタイルを設定する
sns.set_style(style[0],{'grid.color':'red'})です。
# 現在のスタイルに関するパラメータ
print(sns.axes_style()の場合)
コンテキスト = ['paper', 'notebook', 'talk', 'poster '].
sns.set_context(context[0],rc={'grid.linewidth': 2.0})
print(sns.plotting_context()の場合)
# Set the display effect
import pandas as pd
import numpy as np
import seaborn as sns
from matplotlib import pyplot as plt
style = ['darkgrid', 'dark', 'white', 'whitegrid', 'ticks']
# Set the style
sns.set_style(style[0], {'grid.color': 'red'})
# Parameters for the current style
# print(sns.axes_style())
'''
{'axes.facecolor': '#EAEAF2', 'axes.edgecolor': 'white', 'axes.grid': True, 'axes.axisbelow': True, 'axes.labelcolor': '.15', 'figure. facecolor': 'white', 'grid.color': 'red', 'grid.linestyle': '-', 'text.color': '.15', 'xtick.color': '.15', 'ytick.color': '.15', 'xtick. direction': 'out', 'ytick.direction': 'out', 'lines.solid_capstyle': 'round', 'patch.edgecolor': 'w', 'patch.force_edgecolor': True, 'image. cmap': 'rocket', 'font.family': ['sans-serif'], 'font.sans-serif': ['Arial', 'DejaVu Sans', 'Liberation Sans', 'Bitstream Vera Sans', 'sans- serif'], 'xtick.bottom': False, 'xtick.top': False, 'ytick.left': False, 'ytick.right': False, 'axes.spines.left': True, 'axes.spines.bottom' : True, 'axes.spines.right': True, 'axes.spines.top': True}'''
context = ['paper', 'notebook', 'talk', 'poster']
sns.set_context(context[0], rc={'grid.linewidth': 2.0})
# print(sns.plotting_context())
'''
{'font.size': 9.600000000000001, 'axes.labelsize': 9.600000000000001, 'axes.titlesize': 9.600000000000001, 'xtick.labelsize': 8.8, 'ytick. labelsize': 8.8, 'legend.fontsize': 8.8, 'axes.linewidth': 1.0, 'grid.linewidth': 3.0, 'lines.linewidth': 1.20000000000000000002, 'lines. markersize': 4.800000000000001, 'patch.linewidth': 0.8, 'xtick.major.width': 1.0, 'ytick.major.width': 1.0, 'xtick.minor.width': 0.8, 'ytick .minor.width': 0.8, 'xtick.major.size': 4.800000000000001, 'ytick. size': 3.2, 'legend.title_fontsize': 9.600000000000001}'''
'''
name : str
Name of the dataset (``{name}.csv`` on
https://github.com/mwaskom/seaborn-data).'''
# Load the online data
df = sns.load_dataset('flights')
# print(df.info())
'''
RangeIndex: 144 entries, 0 to 143
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 year 144 non-null int64
1 month 144 non-null category
2 passengers 144 non-null int64
dtypes: category(1), int64(2)
memory usage: 2.9 KB
None'''
# print(df.head())
'''
year month passengers
0 1949 Jan 112
1 1949 Feb 118
2 1949 Mar 132
3 1949 Apr 129
4 1949 May 121'''
df = df.pivot(index='month', columns='year', values='passengers')
# print(df.head())
'''
year 1949 1950 1951 ... 1958 1959 1960
month ...
Jan 112 115 145 ... 340 360 417
Feb 118 126 150 ... 318 342 391
Mar 132 141 178 ... 362 406 419
Apr 129 135 163 ... 348 396 461
May 121 125 172 ... 363 420 472'''
# heatmap
# sns.heatmap(df)
# sns.heatmap(df,annot=True,fmt='d') # annot=True,fmt='d' adjusts the value
# sns.heatmap(df,annot=True,fmt='d',cmap='YlGnBu') # cmap='YlGnBu' adjusts the color
s = df.sum()
# print(s)
'''
year
1949 1520
1950 1676
1951 2042
1952 2364
1953 2700
1954 2867
1955 3408
1956 3939
1957 4421
1958 4572
1959 5140
1960 5714
dtype: int64'''
x = s.index
y = s.values
# barplot
sns.barplot(x, y)
plt.show()
関連
-
[解決済み】MIPSでmod演算子を正しく使うには?
-
[解決済み】+のオペランド型が未サポート:'float'と'str'エラー【終了しました
-
[解決済み] MissingSectionHeaderError: ファイルにセクションヘッダがない
-
[解決済み] pandasの.groupbyと反対の「ungroup by」操作はありますか?
-
[解決済み] pip.reqという名前のモジュールがない
-
[解決済み] Google foo.bar レベル3 (queue_to_do) を完了しようとすると、制限時間を超過し続ける [終了] 。
-
[解決済み] データフレーム列の </p> を置換する。
-
[解決済み] Matplotlib のプロット: 軸、凡例、空白を削除する
-
pip install MySQL-python reports "EnvironmentError: mysql_config not found" (環境エラー:mysql_configが見つかりません。
-
ValueError: 解凍する値が足りない (期待値 3、取得値 2)
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
Pythonコードの可読性を向上させるツール「pycodestyle」の使い方を詳しく解説します
-
Pythonの@decoratorsについてまとめてみました。
-
[python np.where] - error:raise ValueError(ValueError: Length of values does not match length of index) エラー。
-
[解決済み] matplotlib: RuntimeError: Python はフレームワークとしてインストールされていません
-
[解決済み] データ型変換エラーです。ValueError: 非有限値(NAまたはinf)を整数に変換できない[重複]。
-
[解決済み] Pythonでfloat値をファイルに書き込むための正しい書式は何ですか?
-
[解決済み] IndentationError: 想定外のunindent WHY?
-
[解決済み] Python/Django: ランサーバーではコンソールにログ、Apacheではファイルにログを出力
-
[解決済み] Python 3でxreadlines()の代わりになるものは何ですか?
-
[解決済み] shell=True で起動した python サブプロセスを終了させる方法