32ビットと64ビットでコンパイルした場合の大きな性能差(26倍速)
質問
を使用した場合の違いを測定しようとしていました。
for
と
foreach
である。
プロファイリングを行うために、以下のクラスを使用しました。
public static class Benchmarker
{
public static void Profile(string description, int iterations, Action func)
{
Console.Write(description);
// Warm up
func();
Stopwatch watch = new Stopwatch();
// Clean up
GC.Collect();
GC.WaitForPendingFinalizers();
GC.Collect();
watch.Start();
for (int i = 0; i < iterations; i++)
{
func();
}
watch.Stop();
Console.WriteLine(" average time: {0} ms", watch.Elapsed.TotalMilliseconds / iterations);
}
}
私は
double
を使いました。
そして、参照型をテストするために、この「偽のクラス」を作りました。
class DoubleWrapper
{
public double Value { get; set; }
public DoubleWrapper(double value)
{
Value = value;
}
}
最後にこのコードを実行し、時間差を比較してみました。
static void Main(string[] args)
{
int size = 1000000;
int iterationCount = 100;
var valueList = new List<double>(size);
for (int i = 0; i < size; i++)
valueList.Add(i);
var refList = new List<DoubleWrapper>(size);
for (int i = 0; i < size; i++)
refList.Add(new DoubleWrapper(i));
double dummy;
Benchmarker.Profile("valueList for: ", iterationCount, () =>
{
double result = 0;
for (int i = 0; i < valueList.Count; i++)
{
unchecked
{
var temp = valueList[i];
result *= temp;
result += temp;
result /= temp;
result -= temp;
}
}
dummy = result;
});
Benchmarker.Profile("valueList foreach: ", iterationCount, () =>
{
double result = 0;
foreach (var v in valueList)
{
var temp = v;
result *= temp;
result += temp;
result /= temp;
result -= temp;
}
dummy = result;
});
Benchmarker.Profile("refList for: ", iterationCount, () =>
{
double result = 0;
for (int i = 0; i < refList.Count; i++)
{
unchecked
{
var temp = refList[i].Value;
result *= temp;
result += temp;
result /= temp;
result -= temp;
}
}
dummy = result;
});
Benchmarker.Profile("refList foreach: ", iterationCount, () =>
{
double result = 0;
foreach (var v in refList)
{
unchecked
{
var temp = v.Value;
result *= temp;
result += temp;
result /= temp;
result -= temp;
}
}
dummy = result;
});
SafeExit();
}
私が選んだ
Release
と
Any CPU
オプションを指定してプログラムを実行したところ、以下のようなタイムが得られました。
valueList for: average time: 483,967938 ms
valueList foreach: average time: 477,873079 ms
refList for: average time: 490,524197 ms
refList foreach: average time: 485,659557 ms
Done!
そして、Releaseとx64のオプションを選択し、プログラムを実行したところ、以下のようなタイムが表示されました。
valueList for: average time: 16,720209 ms
valueList foreach: average time: 15,953483 ms
refList for: average time: 19,381077 ms
refList foreach: average time: 18,636781 ms
Done!
なぜ x64 bit 版はこんなに速いのですか?ある程度の違いは予想していましたが、これほど大きな違いはありません。
私は他のコンピュータにアクセスできません。あなたのマシンでこれを実行し、結果を教えていただけませんか?私は Visual Studio 2015 を使用していて、Intel の コア i7 930.
ここでは
SafeExit()
メソッドがあるので、自分でコンパイル/実行することができます。
private static void SafeExit()
{
Console.WriteLine("Done!");
Console.ReadLine();
System.Environment.Exit(1);
}
要求されたように
double?
の代わりに
DoubleWrapper
:
任意のCPU
valueList for: average time: 482,98116 ms
valueList foreach: average time: 478,837701 ms
refList for: average time: 491,075915 ms
refList foreach: average time: 483,206072 ms
Done!
x64
valueList for: average time: 16,393947 ms
valueList foreach: average time: 15,87007 ms
refList for: average time: 18,267736 ms
refList foreach: average time: 16,496038 ms
Done!
最後になりましたが
x86
を使うのとほぼ同じ結果が得られます。
Any CPU
.
どのように解決するのですか?
4.5.2にて再現しています。ここでは、RyuJIT はありません。x86 と x64 の両方のディスアセンブリは合理的に見えます。範囲チェックなどは同じです。基本的な構造は同じ。ループ展開なし。
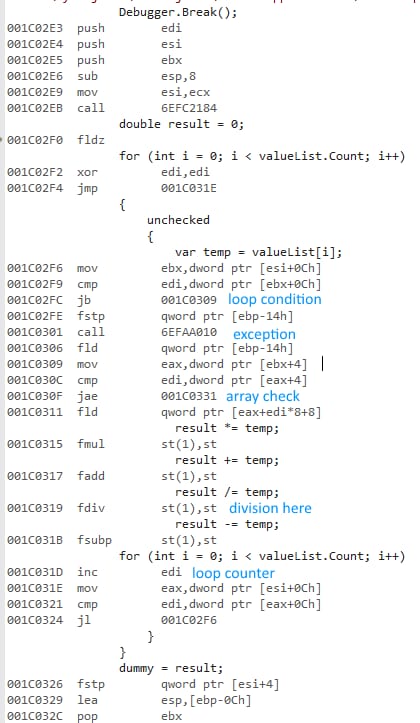
x86は異なるfloat命令群を使用します。これらの命令の性能はx64の命令と同等であると思われる 除算を除けば :
除算演算のため、32ビット版では超低速になります。 除算をアンコメントすると、パフォーマンスが等しくなる を大幅に改善しました (32 ビット版では 430ms から 3.25ms に低下)。
Peter Cordes は、2 つの浮動小数点ユニットの命令レイテンシがそれほど異ならないことを指摘しています。おそらく、中間結果のいくつかは、非正規化された数値または NaN であると思われます。これらは、どちらかのユニットで遅いパスをトリガーするかもしれません。あるいは、10バイトと8バイトの浮動小数点精度のために、2つの実装間で値が発散しているのかもしれません。
Peter Cordes
はまた、次のように指摘しています。
すべて
の中間結果はNaN
... この問題を除去する (
valueList.Add(i + 1)
を削除すると、ほとんどの場合結果が同じになります。どうやら、32ビットコードはNaNオペランドを全く好まないようです。いくつかの中間値を表示してみましょう。
if (i % 1000 == 0) Console.WriteLine(result);
. これで、データがまともになったことが確認できます。
ベンチマークを行う場合、現実的なワークロードをベンチマークする必要があります。しかし、無害な分割がベンチマークを台無しにするとは、誰が考えたでしょうか!
より良いベンチマークを得るために、単純に数字を合計してみてください。
除算とモジュロは常に非常に遅いです。もし、BCLを修正すると
Dictionary
のコードを修正し、バケットインデックスを計算するためにモジュロ演算子を使わないようにすれば、パフォーマンスは測定可能なほど改善されます。これは、除算がいかに遅いかということです。
以下は32ビットコードです。
64ビットコード(構造は同じ、高速除算)。
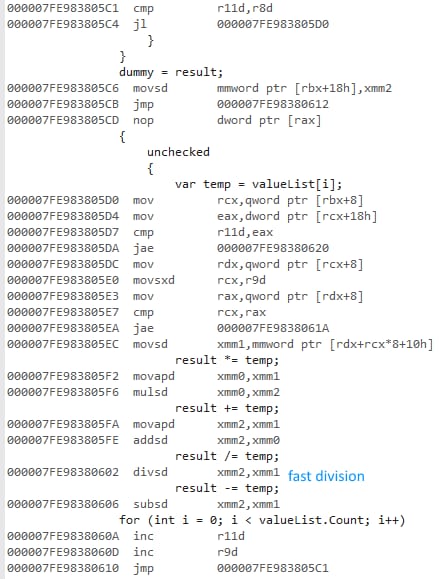
これは ではない SSE 命令が使用されているにもかかわらず、ベクトル化されていません。
関連
-
[解決済み】エラー「必要なフォーマルパラメータに対応する引数が与えられていない」を解決する?
-
[解決済み] C#のStringとstringの違いは何ですか?
-
[解決済み] callとapplyの違いは何ですか?
-
[解決済み] C#のconstとreadonlyの違いは何ですか?
-
[解決済み] フィールドとプロパティの違いは何ですか?
-
[解決済み] async」と「await」の使い方とタイミング
-
[解決済み] SelectとSelectManyの違い
-
[解決済み] キーワード「ref」と「out」の違いは何ですか?
-
[解決済み] Collatz予想の検証を行うC++のコードは、なぜ手書きのアセンブリよりも高速に動作するのでしょうか?
-
[解決済み] C言語のi++と++iに性能差はあるのでしょうか?
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み】文字列が有効な DateTime " format dd/MM/yyyy " として認識されなかった。
-
[解決済み】取り消せないメンバはメソッドのように使えない?
-
[解決済み] 'IEnumerable<SelectListItem>' 型の ViewData アイテムで、キーが国であるものは存在しない。
-
[解決済み】Socket.Selectがエラー "An operation was attempted on something that is not a socket" を返す。
-
[解決済み】Entity FrameworkからのSqlException - セッション内で他のスレッドが動作しているため、新しいトランザクションは許可されません。
-
[解決済み】エラー「必要なフォーマルパラメータに対応する引数が与えられていない」を解決する?
-
[解決済み】Unityでゲームオブジェクトのすべての子をループスルーして破壊する方法?
-
[解決済み] 関数を終了するには?
-
[解決済み】名前 'ViewBag' が現在のコンテキストに存在しない - Visual Studio 2015
-
[解決済み】データが存在しないのに読み込もうとする試みが無効である